











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






自动驾驶中机器学习算法应用大盘点
2017年07月17日 由 yining 发表
417102
0

今天,机器学习算法被广泛应用于解决自动驾驶汽车制造的各种挑战问题中。人类将传感器数据处理集成到汽车的ECU(电子控制单元)中。 提高机器学习的利用率去完成新的任务是十分必要的,潜在的应用包括对驾驶员条件的评估,或者通过不同的外部和内部传感器进行数据融合,比如激光雷达、雷达、相机或物联网。
运行车载信息娱乐系统的应用程序可以接收来自传感器数据融合系统的信息,例如,如果它发现司机有什么不对劲的地方,就有能力直接将汽车开到医院。这个基于机器学习的应用程序还包括驾驶员的语音、手势识别和语言翻译。算法被分为非监督和监督算法。两者的区别在于它们是如何学习的。
受监督的算法利用训练数据集学习,直到达到他们所期望的水平(错误概率最小化)。受监督的算法可以分为回归、分类和异常检测或降维。
无人监督的算法试图从可用数据中获取价值。这意味着,在可用的数据中,一种算法开发出一种关系,以检测模式或将数据集划分为子群,这取决于它们之间的相似程度。非监督算法可以在很大程度上被划分为关联规则学习和集群。
强化算法是另一组机器学习算法,它可以在无人监督和监督的学习之间进行。对于每个训练例子来说,在监督学习中有一个目标标签; 在无监督学习中没有标签; 强化学习包括时间延迟和稀疏标签,也就是未来的奖励。
Agent根据这些奖励学习在环境中行为。为了理解算法的局限性和优点,开发有效的学习算法是强化学习的目标。强化学习可能涉及到大量的实际应用,从人工智能到控制工程或操作研究——所有这些都与自动驾驶汽车的发展有关。这可以被归类为间接学习和直接学习。
在自动驾驶汽车中,机器学习算法的主要任务之一是对周围环境进行连续的渲染,并预测这些环境可能发生的变化。这些任务被分成4个子任务:
- 探测对象
- 识别对象或识别对象的分类
- 物体的定位
- 运动预测
机器学习算法大致分为4类:决策矩阵算法、聚类算法、模式识别算法和回归算法。机器学习算法的一个类别可以用来完成2个或更多的子任务。例如,回归算法可以用于对象定位,也可以用于对象检测或运动预测。
决策矩阵算法(Decision Matrix Algorithms)
决策矩阵算法系统地分析、识别和评价信息集和值集之间的关系的性能。这些算法主要用于决策制定。汽车是否需要刹车或左转,取决于这些算法对物体下一次运动的识别、分类和预测的置信程度。决策矩阵算法是由独立训练的各种决策模型组成的模型,在某种程度上,这些预测被组合在一起做出整体预测,同时减少决策失误的可能性。AdaBoosting是最常用的算法。
AdaBoosting
Adaptive Boosting或AdaBoost是多种学习算法的结合,可用于回归或分类。与其他机器学习算法相比,它克服了过度拟合,并且对异常值和噪声数据较为敏感。为了创建一个强大的学习方法,AdaBoost进行了多次迭代。所以,这是它被称为“适应性”的原因。通过不断地增加弱学习器的能力,AdaBoost进阶成了一个强大的学习器。将一个新的弱学习器附加到实体中,并对一个重向量进行调整,从而注意在前几轮中错误分类的例子。结果是一个分类器比弱学习分类器有着更高的精确度。
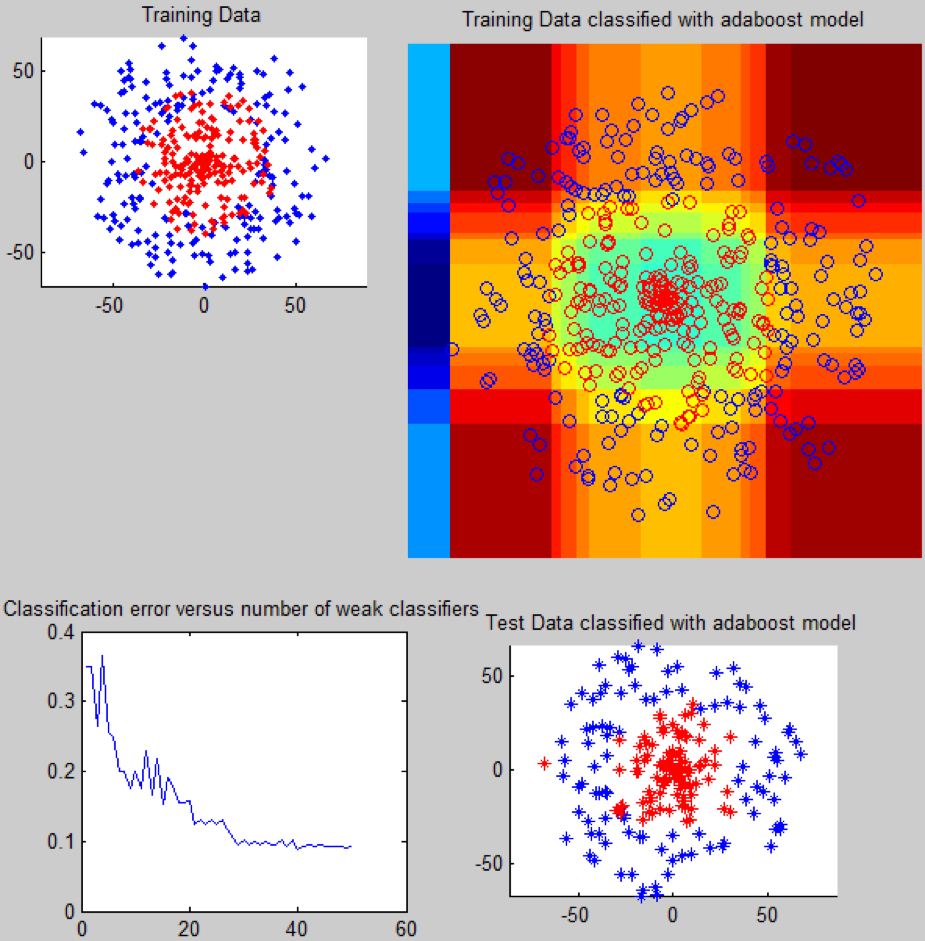
AdaBoost有助于将弱阈值分类器提升为强分类器。上面的图片描述了如何在一个可以理解性代码的单个文件中实现AdaBoost算法。该函数包含一个弱分类器和增强组件。弱分类器尝试在一个数据维度中找到理想的阈值,从而将数据分成两个类。该分类器是按迭代的方式调用的,在每次分类步骤之后,它都改变了分类错误的例子的权重。因此这个原因,大量的弱分类器被创建,并且它的性能就像强分类器一样好。
聚类算法(Clustering Algorithms)
有时,系统获取的图像不清晰,很难定位和探测对象。分类算法也可能会丢失对象,在这种情况下,它们无法对系统进行分类并将其报告给系统。可能的原因应该是不连续的数据,非常少的数据点或图像的分辨率过低。聚类算法是专门研究数据点的结构的,通常是通过对分层和基于质心的方法进行建模来组织的。所有方法都关注于利用数据中的固有结构,让数据进入最大的公共性群体中。k-均值聚类,多类神经网络是最常用的算法。
K-均值聚类(K-means)
k-均值聚类是一种著名的聚类算法。该算法将样本聚类成 k 个集群,k用于定义集群中的k个质心点。如果它比其他的质心更接近这个集群的质心,这个点会被认为是在一个特定的集群中。质心点的更新则根据计算当前分配的数据点到集群的距离来进行。将数据点归于某个集群则取决于当前的质心点。
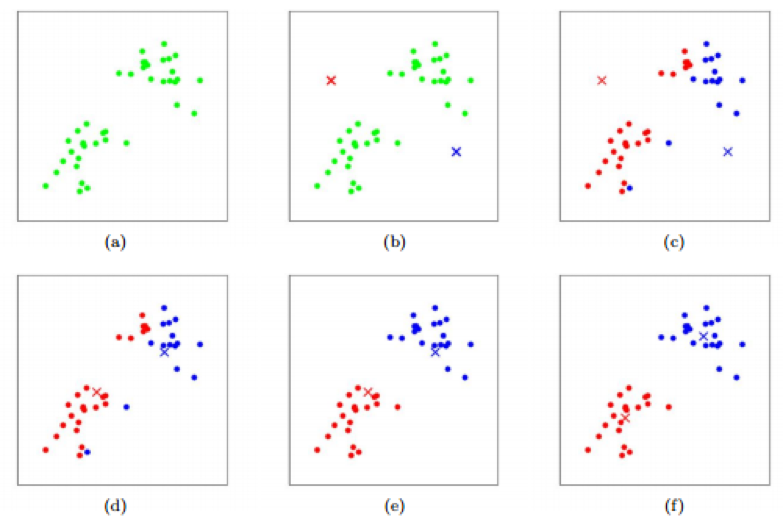
k-均值聚类算法-集群的质心被描述为交叉,训练示例被描述为点。(a)为原始数据集;(b)为随机的初始集群质心;(c-f)为k-均值聚类的2轮迭代后的演示。
每个训练实例都在每个迭代中分配到最接近的集群质心,然后每个集群质心被移动到分配给它的点的平均值上面。
模式识别算法 (Pattern Recognition Algorithms) (分类)
在高级驾驶辅助系统(ADAS)中通过传感器获得的图像由各种环境数据组成; 通过对图像进行过滤,可以排除无关的数据点,从而确定一个对象类别的实例。在对对象进行分类之前,对模式的识别是在数据集中的一个重要步骤。这种算法被定义为数据简化算法。
数据简化算法有助于减少对象的数据集的边缘和多线(拟合线段)以及圆弧的边缘。直到某个节点,线段与边对齐成一条直线,新的线段将在这之后出现。圆形的弧线与线段的序列相一致。在不同的方面来看,图像的特征(圆弧和线段)被组合在一起,用来确定一个物体的特征。
PCA(主成分分析法),HOG(定向梯度的直方图)还有SVM(支持向量机)是高级驾驶辅助系统中常用的识别算法。同时,K近邻(KNN)和Bayes决策法规则也会被使用。
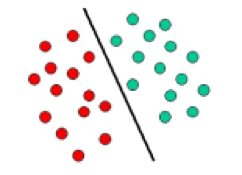
支持向量机(Support Vector Machines)
SVM取决于定义决策边界的决策平面概念。SVM 的超平面会在保留最大间隔的情况下把不同类别的数据分隔开。下面给出了一个示意图。在这种情况下,对象属于红色或绿色类。分离的分界线将红色和绿色的物体分开。左边的任何新物体都被标记为红色,如果它落在左边,它就会被标记为绿色。
回归算法(Regression Algorithms)
这种算法对预测事件很有好处。回归分析评估两个或多个变量之间的关系,并将变量对不同尺度的影响进行排序,主要由3个指标驱动:
- 回归直线的形状
- 依赖变量的类型
- 独立变量的个数
图像(相机或雷达)在执行和定位过程中扮演着重要的角色,而对于任何算法来说,最大的挑战是为特征选择和预测来开发一个基于图像的模型。
环境的可重复性被回归算利用,并建立了一个统计模型。该模型通过允许图像采样,并且提供了快速的在线检测和离线学习。它可以扩展到其他对象,而不需要进行广泛的建模。作为在线实时输出以及对物体存在的反馈,算法将自动返回该物体的位置。
回归算法也可以用于短期预测、长时间学习。这种回归算法可以用于自动驾驶汽车,包括决策森林回归、神经网络回归和贝叶斯回归等。
神经网络回归(Neural Network Regression)
神经网络被用于回归、分类或无监督学习上。它们对未标记的数据进行分组,对数据进行分类,或在经过监督的培训后对其进行预测。神经网络通常在网络的最后一层使用一种逻辑回归形式,将连续数据转换为1或0这样的变量。
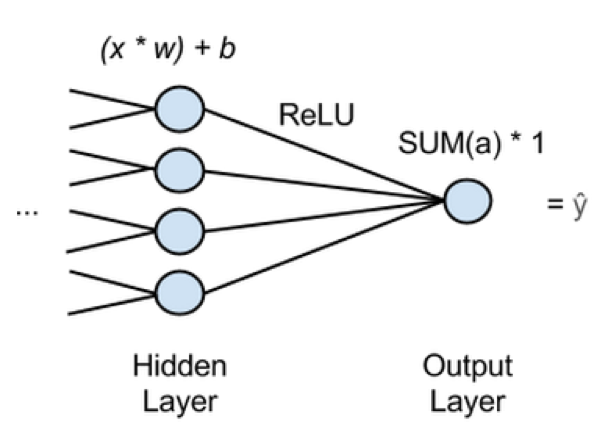
在上面的图中,“x”是输入,特征是从网络的前一层开始传递。在最后一个隐藏层的每一个节点上,都会有很多x的值,每一个x都会被乘以一个对应的w权重。对于偏差,产品的总和被添加并移动到一个激活函数中。激活函数是一个ReLU (整流的线性单元),通常使用它不像 sigmoid 函数那样在浅层梯度情况下易趋于饱和。ReLU为每个隐藏节点提供一个输出,激活a,并将其添加到输出节点,该节点将乘以激活的总和。这意味着,执行回归的神经网络包含单个输出节点,这个节点将把前一层的激活数值乘以1图中神经网络的估计,“Y hat”将是结果。“Y hat”是所有x映射的因变量。你们可以这种方式使用神经网络,从而通过与 y(单个因变量)相关的 x(多个自变量)而预测连续值结果。
此文为编译作品,原网站:https://docs.google.com/document/d/1HIuTNmZvXnVh1oiwfsZJYrDSsekqAK-XumK1c8D4g7Q/edit

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消