











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何通过热图发现图片分类任务的数据渗出
2018年10月31日 由 yuxiangyu 发表
933502
0

两个训练样本的最后一个卷积热图
这是一篇关于如何确保你的模型真正学到了你认为的学习内容的指南。
文末GitHub链接提供了生成以下图片所需的数据集和源代码。本文的所有内容都可以在具有1G内存GPU的笔记本电脑上复现。
在本文中,你将学到:
- 如何在图像分类任务中发现数据渗出(Data Leakage,或数据泄露)
- 如何解决数据渗出(对给定的图像分类任务)
问题
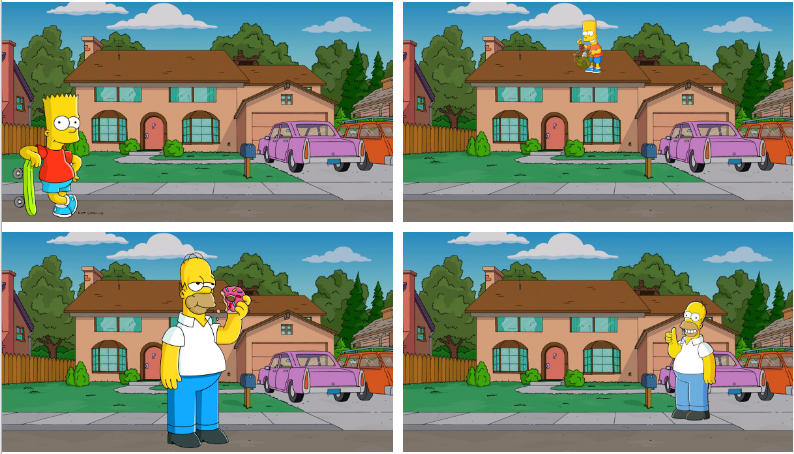
想象一下,玛吉·辛普森(Marge Simpson)委托你完成一项任务:她希望你制定一个算法来区分巴特(Bart )和霍默(Homer)。
因为她爱她的丈夫和她的儿子,她给了你66张在她家前面的父子二人的照片。(注意,在她家前面很重要)
以下是数据集的摘录。
作为一名经验丰富的数据科学家,你应该会选择使用自己喜欢的预训练的图像识别深度神经网络:假设说是VGG16。
但是,因为我们要关注的部分(巴特或霍默)只代表图像中的一个小区域,所以你选择用单个卷积层和全局平均池化层替换末尾的完全连接层,如下所示:
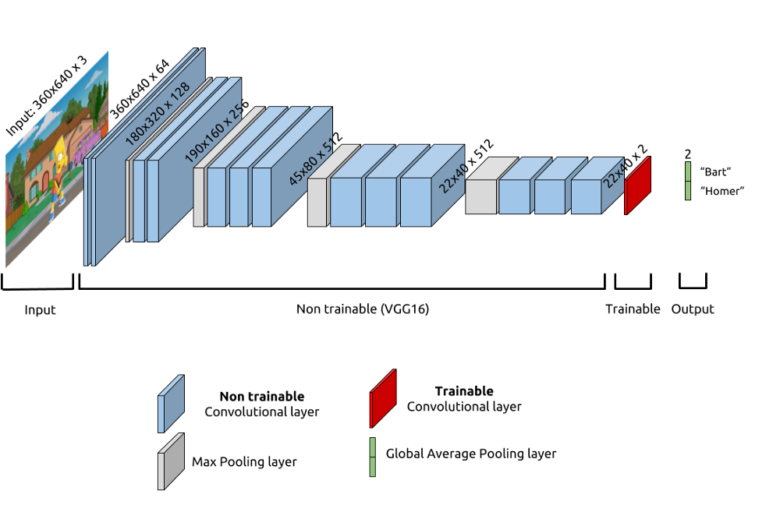
用于巴特vs霍默分类的模型(基于VGG16)。唯一可训练的层是红色的。
对于有些人来说,全局平均池化是一种复杂的说法尤其是这个“平均”。我们会在稍后详细解释它。
如上所述,对于我们的识别任务,你只训练最后一个卷积层。在将给定数据集拆分为训练集和验证集之后,你训练了最后一个卷积层。
学习曲线很好:低的训练和验证损失意味着你有良好的性能并且不会过拟合。你甚至在训练和验证集上达到了100%的准确率。
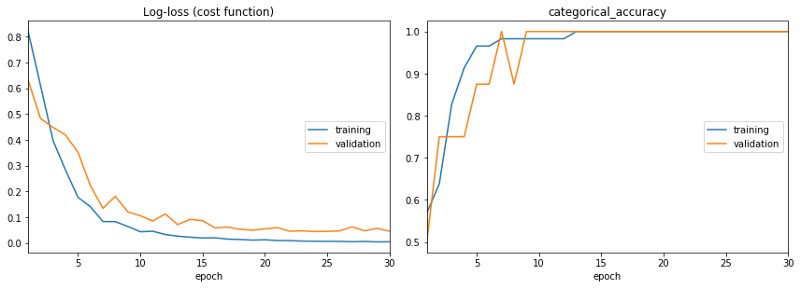
学习曲线
现在是时候在生产环境中使用你的模型了!
然而,在生产环境中,巴特和霍默可以在世界任何地方,比如在斯普林菲尔德核电站前,如下所示:

地面真值:巴特 - 预测标签:Bart ==> OK

地面真值:霍默- 预测标签:Homer ==> OK
对于这4张以前的图片,你的模型在100%预测正确(上面图片预测为巴特,底部图片预测为霍默)。
干得好,玛吉看到了会很开心!
但现在让我们在略有不同的数据集上训练你的模型:
- 因为霍默很多时间都在工作,所以玛吉给你的所有照片都是霍默在核电站前面。
- 而巴特是经常玩耍的孩子,所以玛吉给你的所有照片都是巴特在家庭住宅前面。
下面是这个新数据集的摘录。
新数据集:请注意,在这个数据集中,巴特总是在房子前面,而霍默总是在核电站前面。
与第一次一样,在将给定的数据集分割成训练集和验证集之后,训练模型的最后一个卷积层。
学习曲线超级好:你训练一次准确率就达到了100%!
然而,这好过头了,根本不可能。
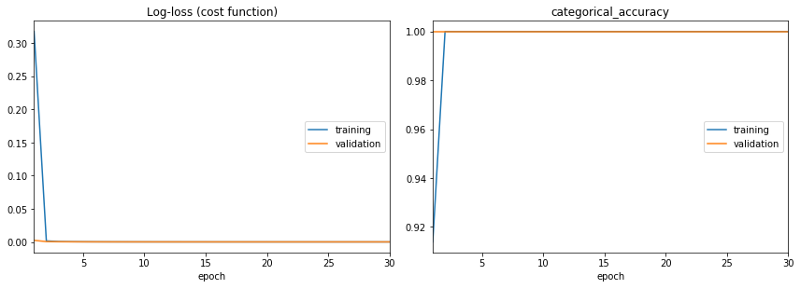
学习曲线
与之前的训练集一样,现在是时候在生产中使用你的模型了!
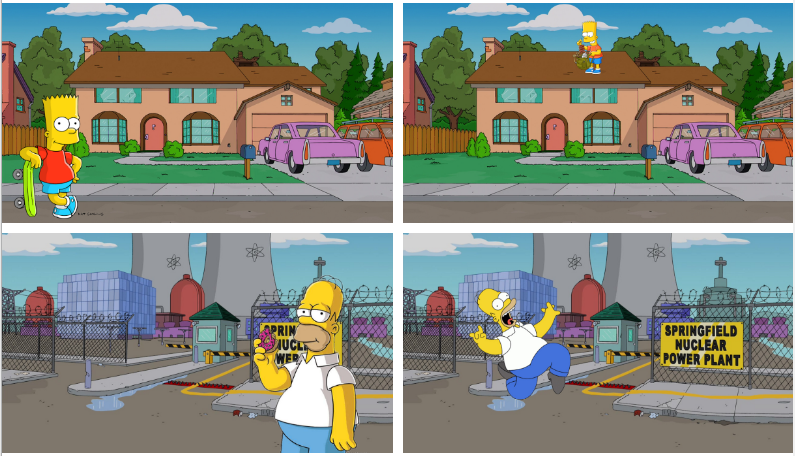
让我们看看你的模型在:巴特在核电站前面和霍默房子前面的表现如何。
也就是说,在训练集中,巴特在房子前面而霍默在核电站前面。在生产环境中,我们测试方法正好相反:巴特在核电站前面和霍默在房子前面。

地面真值:巴特 - 预测标签:Homer ==> NOT OK at ALL

地面真值:霍默 - 预测标签:Bart ==> NOT OK at ALL
这时,你的模特总是预测错误的标签。所以让我们总结一下:
- 训练集的损失和准确性:好。
- 验证集的损失和准确性:好。
- 生产中的模型预测:差。
为什么 ?
答:你的模型发生了数据渗出。为了学习,模型使用了一些不应该使用的特征。
如何发现数据渗出
首先,让我们看一下模型的最后部分:
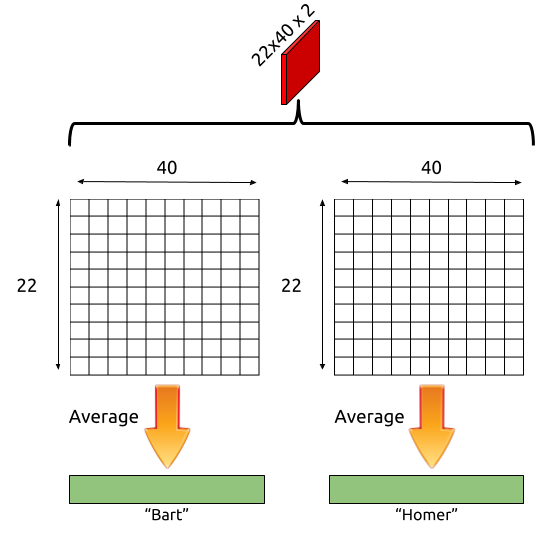
我们的思路方法是在原始图像上方叠加最后一个卷积层的输出。该层输出是22x40的2个矩阵。第一个矩阵表示用于巴特预测的激活,第二个矩阵表示霍默预测的激活。
当然,因为这些矩阵中的每一个形状都为22x40,所以在将它们叠加到原始360x640之上之前,必须将它们放大。
让我们用4张验证集的图片来做这个:
左边是“Bart”最后一个卷积层的输出,右边是“Homer”最后卷积层的输出。
颜色:
蓝色为低输出(接近0),红色为高输出。
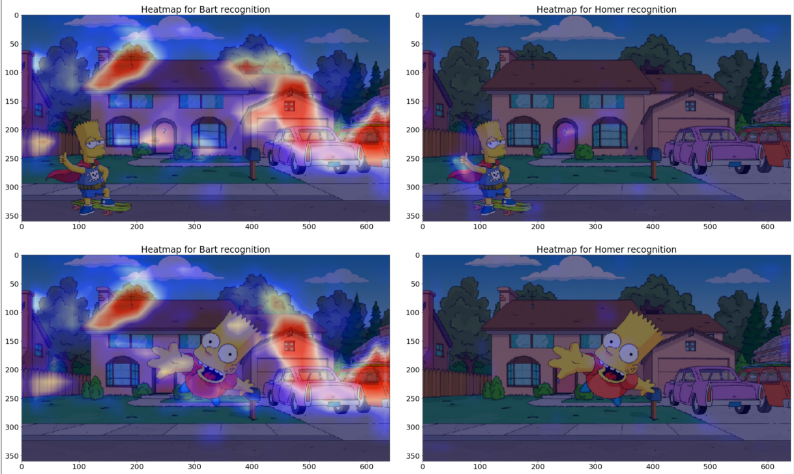
验证集图片最后一个卷积层输出所对应的热图
这样看来,你的模型基本没有使用巴特和霍默进行分类任务,而是使用背景进行学习!
为了确保这个假设是正确的,让我们显示不含有巴特和霍默的图片的最后卷积层输出!
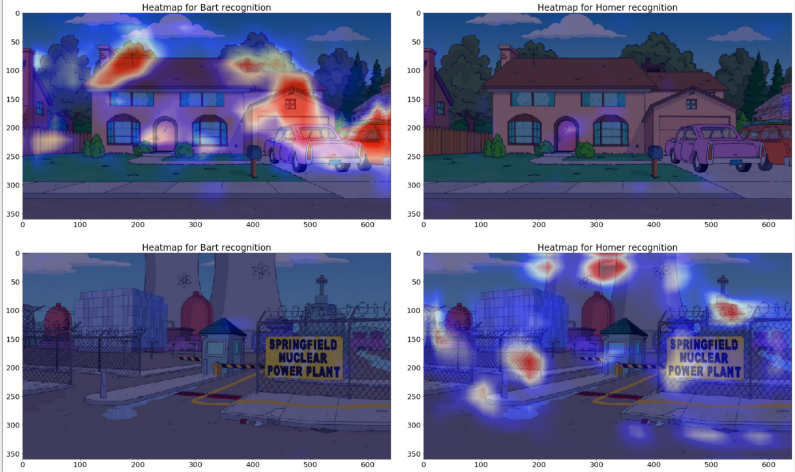
纯背景的最后卷积层输出
嗯,基本可以确定我们的假设是正确的。有没有巴特和霍默对分类模型没有太大影响。
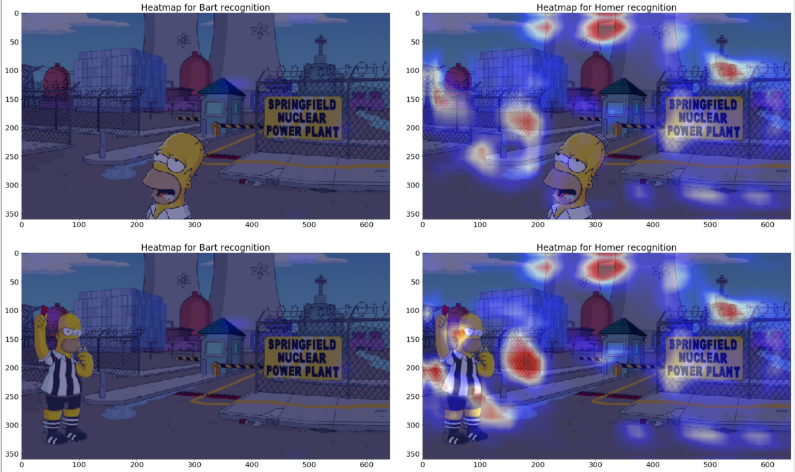
让我们回顾以下我们的第一个模型(仅在房子前面用巴特和霍默的图片进行训练的模型),让我们同样显示最后一个卷积层的输出以获得验证示例:

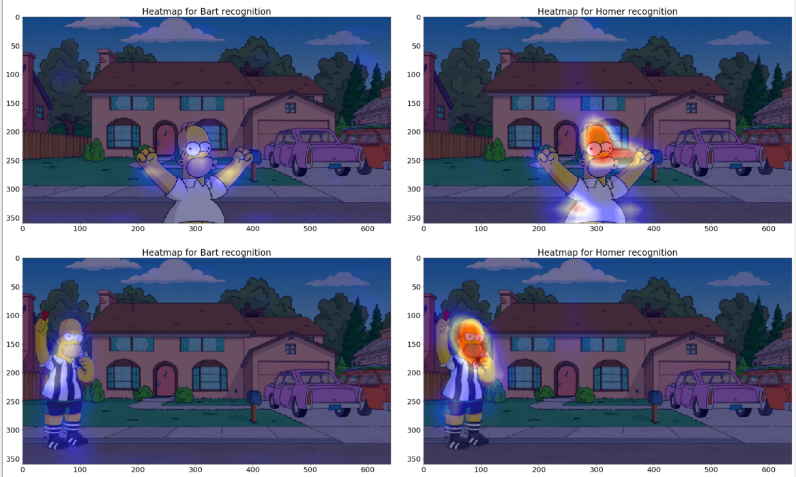
这时,我们就能够理解为什么这个模型预测正确了:因为它确实上使用了巴特和霍默来预测输出!
解决方案
如何解决巴特在房子前面而霍默在核电站前面的训练集的数据渗出问题?我们有几种选择:
- 最常见的是使用边界框修改模型。但是,这很费劲:你必须逐一注释每个训练样本。
- 将我们的2类分类问题(巴特&霍默)转换为3类分类问题(巴特,霍默和背景),这比较简单。
第一类将包含巴特的照片(在房子前面),第二类将包含霍默的照片(在核电站前面),第三类将包含2张图片:房子和发电站的图片(不包含人)。
就这样!
以下是第二种选择的训练模型学习曲线。这些曲线看起来更加“正常”。
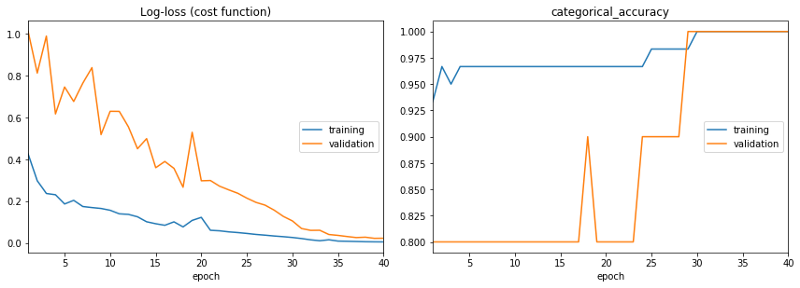
训练模型的曲线
以下是一些验证示例的最后卷积层输出:
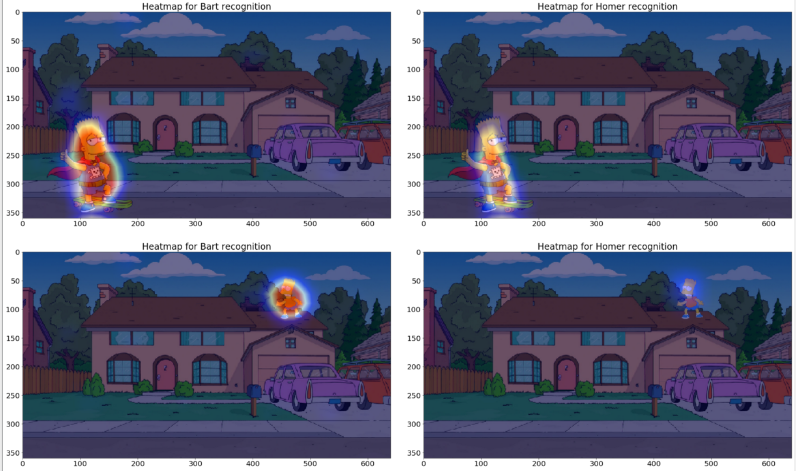
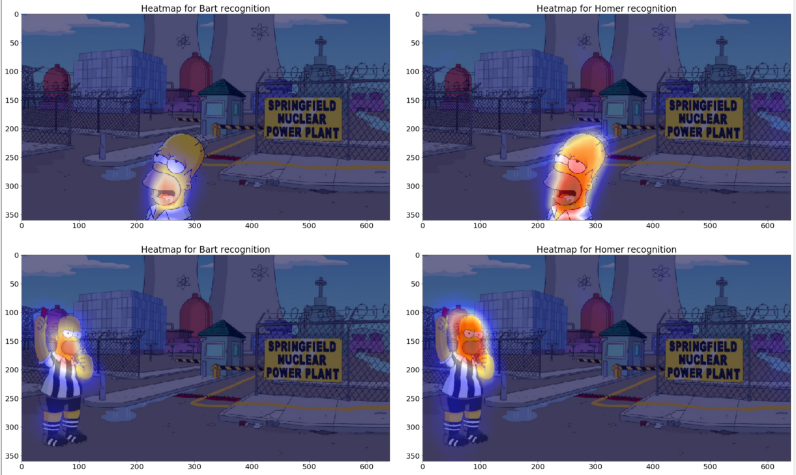
对应的热图
现在,你的模型现在也适用于生产环境。
总结
通过本文,你了解了如何发现图像分类任务中的数据渗出,以及如何修复它。生成上述图像所需的数据集和源代码可访问GitHub获得。
GitHub:https://github.com/nalepae/bart-vs-homer

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消