











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌开源基于TensorFlow的通用框架AdaNet,快速且易于使用
2018年10月31日 由 浅浅 发表
594895
0
 Ensemble learning结合不同机器学习模型预测,被广泛用于神经网络以实现最先进的性能,得益于丰富的历史和理论保证,成功的挑战,如Netflix奖和各种Kaggle竞赛。然而,由于训练时间长,它们在实践中使用不多,机器学习模型候选者选择需要其自己的领域专业知识。但随着计算能力和专用深度学习硬件(如TPU)变得越来越容易获得,机器学习模型将变得更大,整体效果将变得更加突出。现在,想象一个工具可以自动搜索神经架构,并学会将最好的架构组合成一个高质量的模型。
Ensemble learning结合不同机器学习模型预测,被广泛用于神经网络以实现最先进的性能,得益于丰富的历史和理论保证,成功的挑战,如Netflix奖和各种Kaggle竞赛。然而,由于训练时间长,它们在实践中使用不多,机器学习模型候选者选择需要其自己的领域专业知识。但随着计算能力和专用深度学习硬件(如TPU)变得越来越容易获得,机器学习模型将变得更大,整体效果将变得更加突出。现在,想象一个工具可以自动搜索神经架构,并学会将最好的架构组合成一个高质量的模型。今天,谷歌推出了AdaNet,这是一个基于TensorFlow的轻量级框架,可以通过最少的专家干预自动学习高质量的模型。AdaNet建立在谷歌最近的强化学习和基于进化的AutoML工作的基础上,在提供学习保证的同时又快速灵活。重要的是,AdaNet提供了一个通用框架,不仅可以学习神经网络架构,还可以学习集成以获得更好的模型。
AdaNet易于使用,可创建高质量的模型,为机器学习从业者节省了通常用于选择最佳神经网络架构的时间,实现了将神经架构学习为子网络集成的自适应算法。AdaNet能够添加不同深度和宽度的子网络,以创建多样化的集成,并通过参数数量来改善性能。
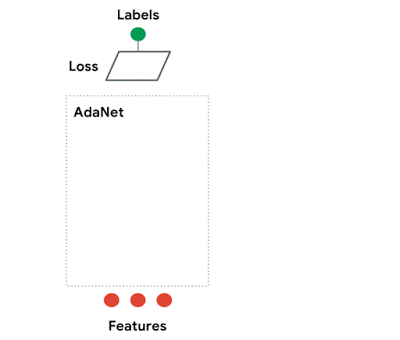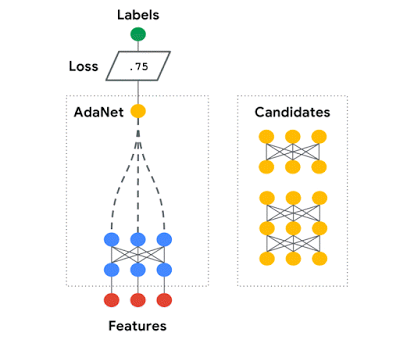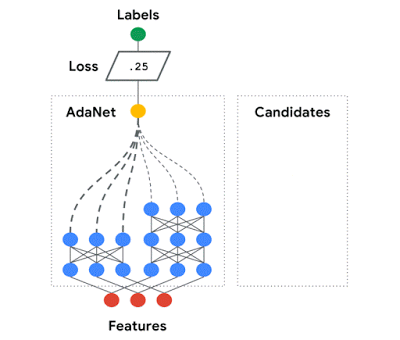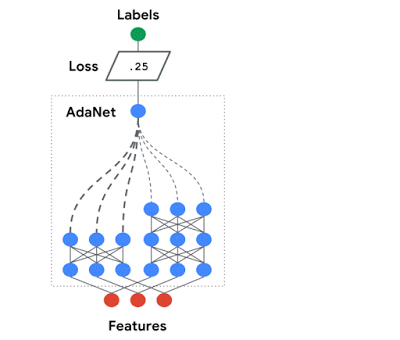
AdaNet自适应地生成了一系列神经网络。在每次迭代中,它测量每个候选对象的集成损耗,并选择最好的一个进行下一次迭代。
快速且易于使用
AdaNet实现了TensorFlow Estimator接口,通过封装训练,评估,预测和服务导出,大大简化了机器学习编程。它集成了开源工具,如TensorFlow Hub模块,TensorFlow模型分析和Google Cloud的Hyperparameter Tuner。分布式训练支持可显著缩短训练时间,并可与可用的CPU和加速器(例如GPU)进行线性扩展。
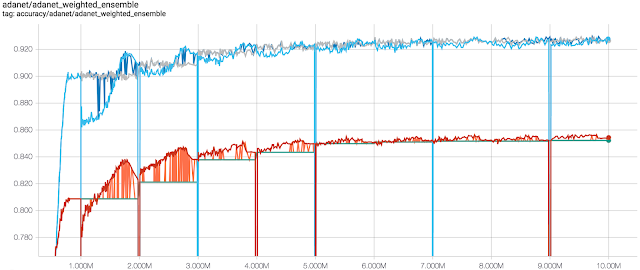
AdaNet在cifar 100上每训练步(x轴)对应精度(y轴)。蓝线表示训练集的准确率,红线表示测试集的性能。每百万步就会有一个新的子网络开始训练,最终提高集成的性能。在添加新子网络之前,灰色和绿色的线是集成的精度。
由于TensorBoard是用于在训练期间可视化模型度量的最佳TensorFlow功能之一,因此AdaNet可与其无缝集成,以监控子网络训练,集成组合和性能。当AdaNet完成训练后,它会导出一个可以使用TensorFlow Serving部署的SavedModel。
学习保证
构建神经网络集成有多重挑战:最佳子网架构是什么?重复使用相同的架构还是鼓励多样性?虽然具有更多参数的复杂子网将倾向于在训练集上表现更好,但由于其更大的复杂性,它们可能不会推广到没见过的数据中。这些挑战源于模型性能评估。我们可以评估来自训练集的保持集分割的性能,但这样做会减少可用于训练神经网络的示例数量。
相反,AdaNet的方法(论文AdaNet: Adaptive Structural Learning of Artificial Neural Networks中提出)是为了优化一个目标,以平衡集成在训练集上的表现与其推广到看不见的数据的能力之间的权衡。直觉是指整体只有当它改善整体训练损失而不是影响其概括能力时才包括候选子网。这保证了:
- 集成的泛化误差受其训练误差和复杂性的约束。
- 通过优化此目标,我们直接最小化此约束。
优化此目标函数的一个实际好处是,它不需要保留集来选择要添加到集成中的候选子网络。这样做的另一个好处是可以使用更多的训练数据来训练子网络。要了解更多信息,请浏览有关AdaNet目标的教程:github.com/tensorflow/adanet/blob/v0.1.0/adanet/examples/tutorials/adanet_objective.ipynb
可扩展
为研究和生产使用制作有用的AutoML框架的关键是不仅要提供合理的默认值,还要允许用户尝试自己的子网络/模型定义。这样机器学习研究人员,从业人员和爱好者均可使用高级TensorFlow API(如tf.layers)定义自己的AdaNet adanet.subnetwork.Builder。
已经在系统中集成了TensorFlow模型的用户可以轻松地将他们的TensorFlow代码转换为AdaNet子网络,并使用adanet.Estimator提高模型性能,同时获得学习保证。AdaNet将探索他们定义的候选子网的搜索空间,并学习整合子网。例如,采用NASNet-A CIFAR架构的开源实现,将其转换为子网,并在八次AdaNet迭代后对CIFAR-10最先进的结果进行了改进。此外,模型使用更少的参数实现了这个结果:
用户通过固定或定制tf.contrib.estimator.Heads,将自定义的损失函数用作AdaNet目标的一部分,以便训练回归,分类和多任务学习问题。

在CIFAR-10上,2018年Zoph等人提出的NASNet-A模型 VS AdaNet学习结合NASNet-A子网络的性能。
用户还可以通过扩展adanet.subnetwork.Generator类别,来完全定义要探索的候选子网络的搜索空间。这允许他们根据可用硬件增加或减少搜索空间。子网络的搜索空间可以简单到使用不同的随机种子复制相同的子网络配置,训练具有不同超参数组合的数十个子网络,并让AdaNet选择一个进入最终集成。
Github:github.com/tensorflow/adanet
教程notebook:github.com/tensorflow/adanet/tree/v0.1.0/adanet/examples/tutorials
论文:proceedings.mlr.press/v70/cortes17a.html

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消