











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI算法掌握困难游戏,AI智能体胜过人类玩家
2018年11月05日 由 浅浅 发表
76513
0
 OpenAI最新论文中,详细介绍了在复古平台游戏Montezuma's Revenge中AI胜过人类玩家。表现最佳的迭代发现了第一关中24个房间中的22个,偶尔几次会发现所有24个房间。
OpenAI最新论文中,详细介绍了在复古平台游戏Montezuma's Revenge中AI胜过人类玩家。表现最佳的迭代发现了第一关中24个房间中的22个,偶尔几次会发现所有24个房间。机器学习算法掌握Montezuma's Revenge是非常困难的。这是唯一在2015年挫败DeepMind炙手可热的深度Q-Learning网络的Atari 2600游戏。
OpenAI表示,“简单的探索策略极不太可能得到任何奖励,或者看到该级别的24个房间中的更多,从那时起,该游戏进展被许多人视为探索进步的代名词。”
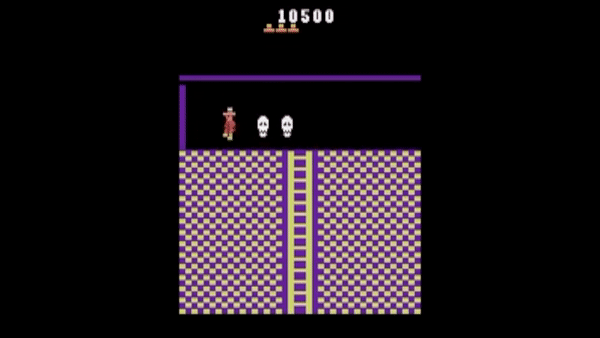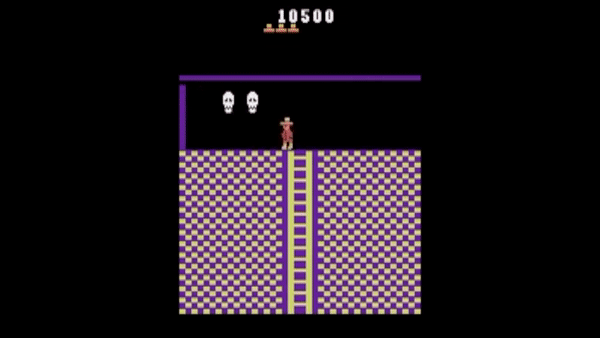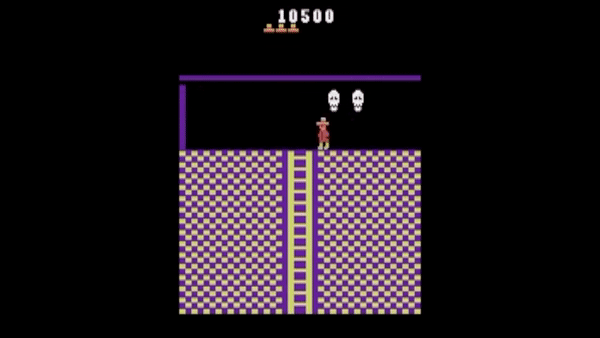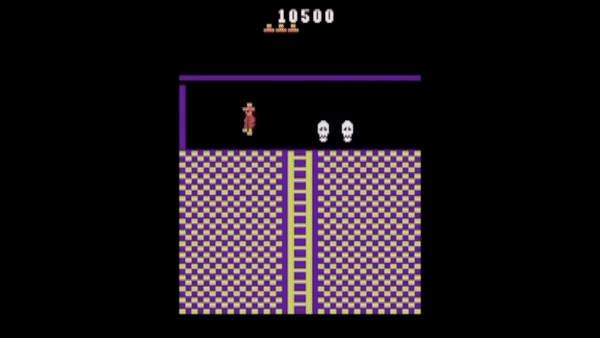
控制玩家角色的智能体。
OpenAI将其方法称为Random Network Distillation(RND),并表示它被设计用于任何强化学习算法,即使用奖励和惩罚系统的模型,以便在特定目标的方向上驱动AI智能体。
传统上,智能体从他们的经验中学习下一状态预测模型,并将预测误差用作内在奖励。与现有方法不同,RND引入奖励奖励,该奖励基于预测下一状态下固定和随机初始化神经网络的输出。
在运行过程中,智能体完全随机地玩游戏,通过反复试验改进他们的战略。由于RND组件,它们被激励去探索它们可能没有的游戏地图区域,即使没有明确传达也能实现游戏的目标。
OpenAI解释说:“好奇心促使智能体发现新的房间并找到增加游戏内得分的方法,而这种外在的奖励促使它在训练后期再次访问这些房间。好奇心为我们提供了一种更简单的方式来教授代理与任何环境进行交互,而不是通过广泛设计的任务特定的奖励功能,我们希望这些功能与解决任务相对应。使用不属于环境细节的通用奖励功能的代理可以在广泛的环境中获得基本的能力水平,从而使智能体能够确定即使在没有精心设计的奖励的情况下哪些行为也是如此。”
RND解决了强化学习方案中的另一个常见问题:所谓的噪声电视问题,其中AI智能体可能会陷入在随机数据中寻找模式的困境(如电视上的静态数据)。
OpenAI写道:“就像赌博机上的赌徒吸引机会的结果一样,智能体有时会被其好奇心困住。智能体在环境中找到了随机性的来源,并不断观察它,总是会对这种转变产生很高的内在回报。”
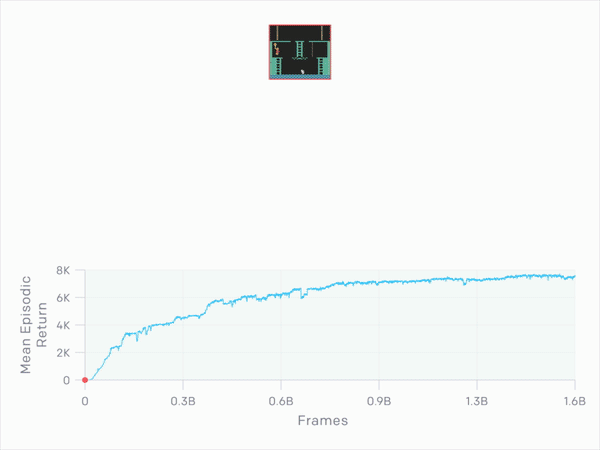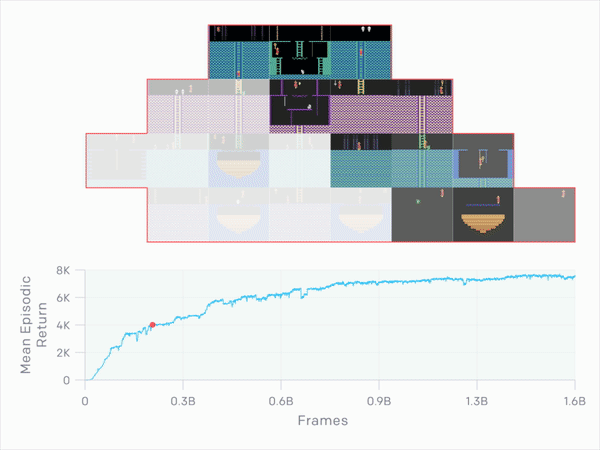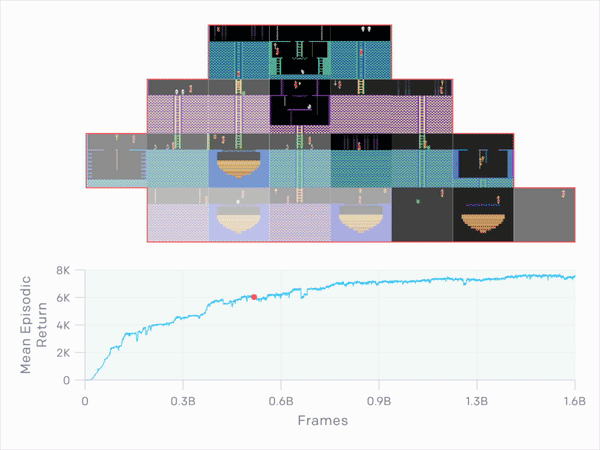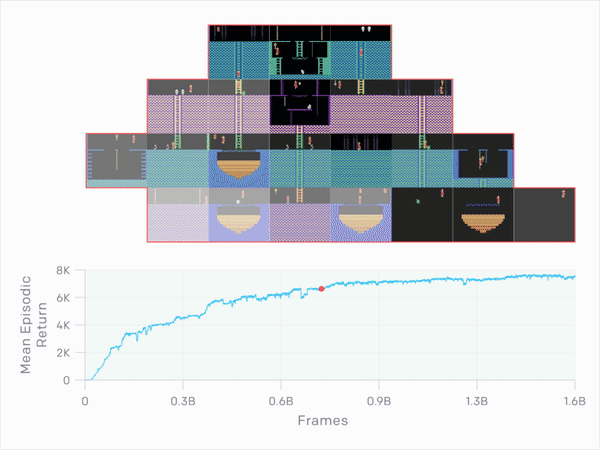
那表现如何呢?平均而言,OpenAI的智能体在九次运行中获得了10K,最佳平均回报率为14.5K。较长时间运行的测试达到了17.5K,相当于通过第一关并找到所有24个房间。
他们掌握的不仅仅是Montezuma's Revenge。当在超级马里奥上运行时,智能体发现了11个关卡,发现了秘密房间,并且击败了首领。经过几个小时的训练,他们学会了如何通关Breakout。当在Pong与一名人类玩家一起较量时,他们试图延长比赛而不是取胜。
论文:arxiv.org/abs/1810.12894

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消