


















RNN示例项目从开发到部署(一):详解使用RNN撰写专利摘要

我第一次尝试研究RNN时,我试图先学习LSTM和GRU之类的理论。在看了几天线性代数方程之后(头疼的要死),我在Python深度学习中发生了以下这段话:
总之,你不需要了解LSTM单元具体架构的所有内容;作为一个人,理解它不应该是你的工作。只要记住LSTM单元要执行的操作:允许以后重新插入过去的信息。
这是深度学习专家Keras库的作者(Francois Chollet),他告诉我,我并不需要了解基础层面的所有内容!我意识到我的错误是从底层理论开始的,而没有简单的试图构建一个RNN。
于是,我改变了战术,决定尝试最有效的学习数据科学技术的方法:找到问题并解决它!
这种自上而下的方法意味着,我们要在回去学习理论之前,先学习如何实现方法。通过这种方式,我能够弄清楚在此过程中我需要知道什么,当我回去研究概念时,我就有了一个可以把每个概念都融入其中的框架。于是,我决定不再管细节,先完成一个RNN项目。
本文介绍了如何在Keras中构建和使用一个RNN来编写专利摘要。这篇文章理论比较浅显,但是当你跟随我们的教程第二部分RNN示例项目从开发到部署(二):将Keras深度学习模型部署为Web应用程序和第三部分RNN示例项目从开发到部署(三):在AWS上部署深度学习模型完成这个项目时,你会发现你在过程中会学到了你需要知道的东西。最后,你可以构建一个有用的应用程序,并弄清楚自然语言处理的深度学习方法是如何工作的。
完整代码在GitHub上提供(链接在文末)。我还提供了所有预训练好模型,因此你不必自己训练几个小时!要尽快开始并研究模型,请参阅notebooks/Quick Start to Recurrent Neural Networks.ipynb,有关深入解释,请参阅notebooks/Deep Dive into Recurrent Neural Networks.ipynb。
RNN
在开始实施之前,至少要理解一些基础知识。在高层次中,RNN( recurrent neural network)用于处理序列,如每日股票价格,句子、传感测量 - 每次一个单元,同时保留之前序列中的记忆(称为状态)。
“recurrent ”意味着当前时间步的输出成为下一个时间步的输入。在序列的每个单元,模型不仅考虑当前输入,还考虑它对前面单元的记忆。
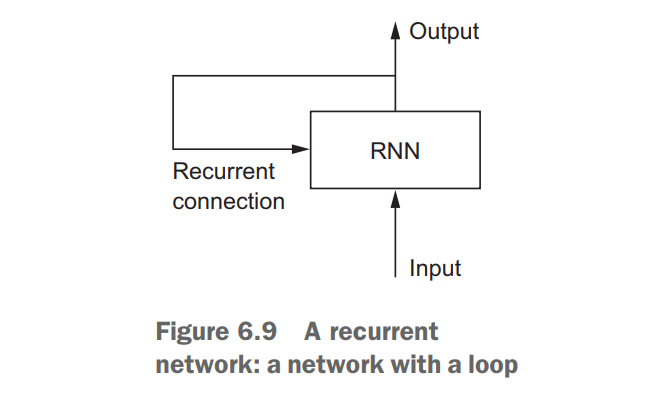
这种记忆使网络学习序列中的长期依赖关系,这意味着它可以在进行预测时考虑整个上下文,可用于预测句子中的下一个单词,情感分类还是温度预测。RNN旨在模仿人类处理序列的方式:我们在形成一个回应时考虑整个句子,而不是单词本身。例如,以下句子:
“The concert was boring for the first 15 minutes while the band warmed up but then was terribly exciting.”
机器学习模型只考虑单独的单词 - 例如词袋模型 - 可能会得出结论这句话是消极的。相比之下,RNN应该能够看到单词“but”和“terribly exciting”并且意识到句子从消极变为积极,因为它查看了整个序列。读取整个序列为我们提供了处理其含义的上下文,这就是在RNN中编码的概念。
RNN的核心是由记忆单元构成的层。目前最流行的单元是LSTM,它可以保持单元状态和进位(carry),以确保信号(梯度形式的信息)在处理序列时不会丢失。在每个时间步,LSTM考虑当前进位,进位和单元状态。
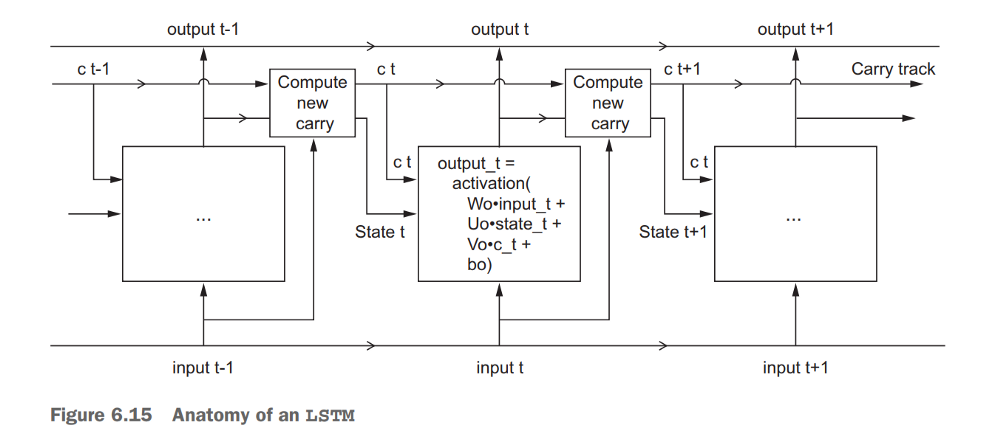
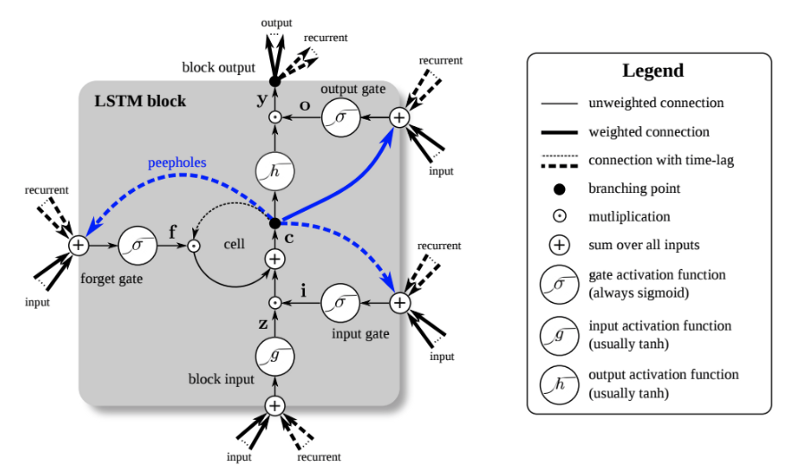
LSTM(长短期记忆网络)单元
LSTM有3个不同的门和权重向量:有一个“遗忘”门用于丢弃无关信息;一个用于处理当前输入的“输入”门,一个“输出”门用于在每个时间步中生成预测。然而,正如Chollet指出的那样,尝试为单元中的每个元素指定特定含义意义不大。
每个单元的功能最终由训练期间学习的参数(权重)决定。你可以随意标记每个单元部分,但这并不是有效使用的必要条件!
问题制定
我们可以通过多种方式制定训练RNN编写文本的任务,本文中使用专利摘要。但是,我们会选择将其训练为多对一序列映射器。也就是说,我们输入一系列单词并训练模型预测下一个单词。在传递到LSTM层之前,将使用嵌入矩阵(预训练的或可训练的)将单词映射到整数然后映射到向量。
当我们去写一个新的专利摘要时,我们传入一个单词的起始序列,对下一个单词进行预测,更新输入序列,进行下一个预测,将单词添加到序列中并继续生成单词。
该方法的步骤概述如下:
- 将字符串列表中的摘要转换为整数列表(序列)
- 从序列创建要素和标签
- 使用Embedding,LSTM和Dense层构建LSTM模型
- 加载预训练好的嵌入
- 在序列中训练模型来预测接下来的单词
- 通过传递初始序列进行预测
请记住,这只是问题的一个表述:我们还可以使用字符级模型或对序列中的每个单词进行预测。与机器学习中的许多概念一样,这没有一个标准答案,但这种方法在实践中很有效。
数据准备
即使具有神经网络有强大的表示能力,获得高质量,干净的数据集也是至关重要的。该项目的原始数据来自USPTO PatentsView,你可以在其中搜索有关在美国申请的任何专利的信息。我搜索了“神经网络”这个术语并下载了最终的专利摘要 - 总共3500个。我发现最好在窄的领域上进行训练,你也可以尝试使用不同的专利。

专利摘要数据
我们首先将专利摘要作为字符串列表。我们模型的主要数据准备步骤是:
- 删除标点符号并将字符串拆分为单个单词列表
- 将单个单词转换为整数
这两个步骤都可以使用Keras中的Tokenizer类完成。默认情况下,这将删除所有标点符号,将单词小写,然后将单词转换为整数序列(sequences)。Tokenizer首先出现适应在字符串列表中,然后将此列表转换为整数列表列表。如下:
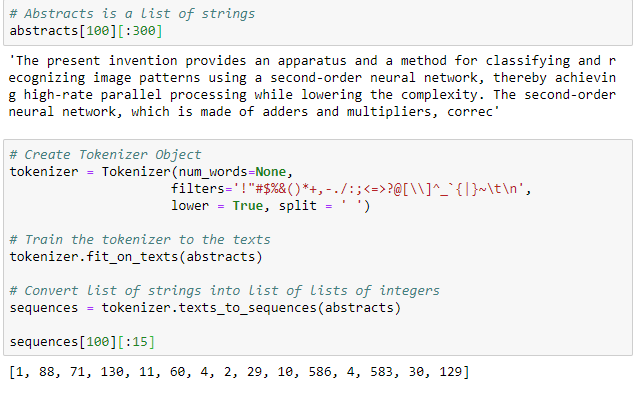
第一个单元格的输出显示原始摘要,第二个单元格的输出显示标记化序列。每个摘要现在表示为整数。
我们可以使用已训练的tokenizer的idx_word属性来算出每个整数的含义:
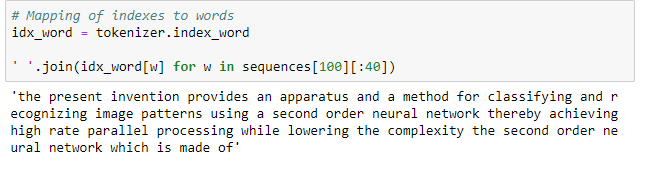
仔细观察,你会注意到Tokenizer已经删除了所有标点并小写了所有单词。如果我们使用这些设置,那么神经网络将无法学习正确的英语!我们可以通过更改过滤器调整它,使Tokenizer为不再删除标点。
# Don't remove punctuation or uppercase
tokenizer = Tokenizer(num_words=None,
filters='#$%&()*+-<=>@[\\]^_`{|}~\t\n',
lower = False, split = ' ')
notebooks中的有不同实现。但是,当我们使用预训练的嵌入时,我们必须删除大写,因为嵌入中没有小写字母。而在训练我们自己的嵌入时,我们不必担心这个,因为模型将以不同表示学习大小写。
特征和标签
上一步将所有摘要转换为整数序列。下一步是创建一个用于训练网络的监督机器学习问题。你可以以多种方式为文本生成设置RNN任务,但我们将使用以下方法:
给网络一个单词序列,训练它预测下一个单词。
单词数留作参数;我们将使用50为例,这意味着我们给我们的网络50个单词,并训练它预测第51个单词。训练网络的其他方法是让它预测序列中每个点的下一个词。即,对每个输入词进行预测而不是对整个序列进行一次预测或者使用单个字符训练模型。这里使用的实现不一定是最优的,也没有公认的最佳解决方案 ,但它运作良好!
创建要素和标签相对简单,对于每个摘要(以整数表示),我们创建多组特征和标签。使用前50个单词作为特征,第51个单词作为标签,然后使用单词第2-51作为特征并预测第52个单词等等。这为我们提供了更多的训练数据,这是有益的,因为网络的性能与它在训练期间所用到的数据量成正比。
创建功能和标签的实现如下:
features = []
labels = []
training_length = 50
# Iterate through the sequences of tokens
for seq in sequences:
# Create multiple training examples from each sequence
for i in range(training_length, len(seq)):
# Extract the features and label
extract = seq[i - training_length:i + 1]
# Set the features and label
features.append(extract[:-1])
labels.append(extract[-1])
features = np.array(features)
特征最终形状(296866, 50),这意味着我们有近300,000个序列,每个序列有50个标记(token)。在RNN的语言中,每个序列具有50个时间步,每个具有1个特征。
我们可以将标签保留为整数,但是当标签是独热编码时,神经网络能够最有效地训练。我们可以在numpy中使用以下方法快速对标签进行独热编码化:
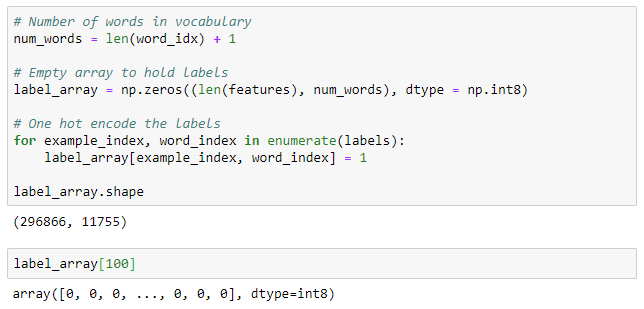
要查找label_array中与与行对应的单词,我们使用:
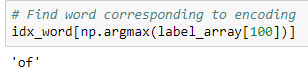
在将所有功能和标签格式化后,我们希望将它们分成训练和验证集(有关详细信息,请参阅notebook)。这里需要同时对特征和标签进行混洗,这样相同的摘要就不会都在一组中结束。
建立一个RNN
Keras是一个很棒的库:它让我们用几行可理解的Python代码构建最先进的模型。也许其他神经网络库更快或有更好的灵活性,但没有什么能够超越Keras的开发时间和易用性。
下面是一段简单的LSTM的代码:
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout, Masking, Embedding
model = Sequential()
# Embedding layer
model.add(
Embedding(input_dim=num_words,
input_length = training_length,
output_dim=100,
weights=[embedding_matrix],
trainable=False,
mask_zero=True))
# Masking layer for pre-trained embeddings
model.add(Masking(mask_value=0.0))
# Recurrent layer
model.add(LSTM(64, return_sequences=False,
dropout=0.1, recurrent_dropout=0.1))
# Fully connected layer
model.add(Dense(64, activation='relu'))
# Dropout for regularization
model.add(Dropout(0.5))
# Output layer
model.add(Dense(num_words, activation='softmax'))
# Compile the model
model.compile(
optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
我们正在使用Keras的Sequential接口,这意味着我们一次构建一个网络层。层如下:
- Embedding每个输入单词映射为100维向量。它可以使用我们在weights参数中提供的预训练的权重。如果我们不想更新Embedding,可以将trainable设置False。
- Masking层用来屏蔽任何没有经过预训练的嵌入的词,以全零表示。在训练嵌入时不应使用此层。
- 网络的核心:一层LSTM有dropout的单元以防止过拟合。由于我们只使用一个LSTM层,因此不返回序列,因为使用两个或更多层,需要返回序列。
- 具有relu激活函数的完全连接稠密层(Dense)。这为网络增加了额外的代表能力。
- Dropout层,以防止过拟合训练数据。
- Dense层,完全连接的输出层。这使得词汇中的每个单词都使用softmax激活产生概率。
模型使用Adam优化器(随机梯度下降的变体)进行编译,并使用categorical_crossentropy损失进行训练。在训练期间,网络将尝试通过调整可训练参数(权重)来最小化对数损失。并且,参数的梯度使用反向传播计算,使用优化器进行更新。由于我们使用的是Keras,因此我们不必去想在底层发生了什么,只需要正确设置网络。
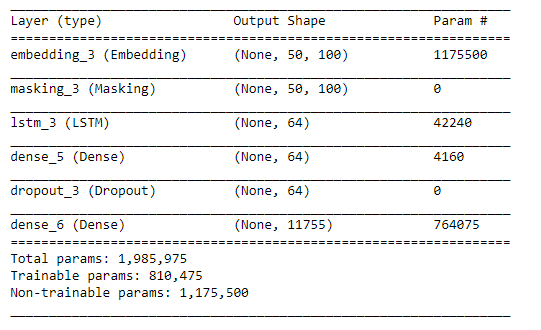
LSTM网络布局
在不更新嵌入的情况下,在网络中训练的参数少了很多。层的输入是(None, 50,100)意味着对于每个批次(第一个维度),每个序列具有50个时间步(单词),每个序列在嵌入后具有100个特征。LSTM层的输入总是具有(batch_size, timesteps, feature)形状。
同样,构建此网络的方法有很多种,notebook中还包含其他几种方法。例如,我们可以使用两个相互叠加的LSTM层,一个双向的LSTM层(从两个方向处理序列),或者使用更多Dense层。但我觉得上面的设置运行良好。
预训练嵌入
一旦建立了网络,我们仍然必须为其提供预训练的字嵌入。还有,你可以在网上找到大量的嵌入训练的不同语料库(大量文本)。们使用的是斯坦福大学提供的,它有100、200或300个维度(我们用100)。这些嵌入来自GloVe(Global Vectors for Word Representation)算法,并在维基百科上进行了训练。
尽管预训练好的嵌入包含的单词有400,000个,我们的词汇中也会包含一些别的单词。当我们用嵌入来表示这些单词时,它们将具有全零的100维向量。可以通过训练我们自己的嵌入或通过将Embedding层的trainable参数设置为True(并移除Masking层)来克服此问题。
使用以下代码,我们可以快速地从磁盘加载预训练好的嵌入并构造嵌入矩阵:
# Load in embeddings
glove_vectors = '/home/ubuntu/.keras/datasets/glove.6B.100d.txt'
glove = np.loadtxt(glove_vectors, dtype='str', comments=None)
# Extract the vectors and words
vectors = glove[:, 1:].astype('float')
words = glove[:, 0]
# Create lookup of words to vectors
word_lookup = {word: vector for word, vector in zip(words, vectors)}
# New matrix to hold word embeddings
embedding_matrix = np.zeros((num_words, vectors.shape[1]))
for i, word in enumerate(word_idx.keys()):
# Look up the word embedding
vector = word_lookup.get(word, None)
# Record in matrix
if vector is not None:
embedding_matrix[i + 1, :] = vector
这样做是为词汇表中的每个单词分配一个100维向量。如果单词没有预训练的嵌入,则该向量是全零。

为了探索嵌入,我们可以使用余弦相似性来找到嵌入空间中最接近给定查询词的单词:
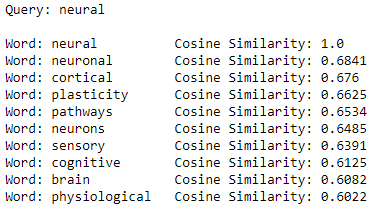
学习嵌入,这意味着表示只适用于一个任务。当使用预训练的嵌入时,我们希望嵌入式学习的任务足够接近我们的任务,因此嵌入是有意义的。如果这些嵌入是通过tweets进行训练的,我们可能不会期望它们能够很好地工作,但由于它们接受过维基百科数据的训练,因此它们推广到适用于很多语言处理任务。
如果你有大量数据和计算机时间,通常最好为特定任务学习自己的嵌入。在notebook中我采用了这两种方法,学习嵌入的性能稍好一些。
训练模型
通过准备训练和验证数据,构建网络以及加载嵌入,我们基本已经准备好为我们的模型学习如何编写专利摘要。然而,在训练神经网络时,最好的步骤是以Keras回调的形式使用ModelCheckpoint和EarlyStopping:
- 模型检查点(Model Checkpoint):将最佳模型(通过验证损失度量)保存在磁盘上,以使用最好的模型
- 提前停止(Early Stopping):当验证损失不再减少时停止训练
使用提前停止意味着我们不会过拟合训练数据,不会浪费时间去训练那些不能提高性能的额外周期。模型检查点意味着我们可以访问最佳模型,如果我们的训练在1000个周期中断,我们也不会失去所有进展!
from keras.callbacks import EarlyStopping, ModelCheckpoint
# Create callbacks
callbacks = [EarlyStopping(monitor='val_loss', patience=5),
ModelCheckpoint('../models/model.h5'), save_best_only=True,
save_weights_only=False)]
然后可以使用以下代码训练模型:
history = model.fit(X_train, y_train,
batch_size=2048, epochs=150,
callbacks=callbacks,
validation_data=(X_valid, y_valid))
在亚马逊p2.xlarge上,这需要1个多小时才能完成。训练完成后,我们加载保存的最佳模型,并使用验证数据进行最终评估。
from keras import load_model
# Load in model and evaluate on validation data
model = load_model('../models/model.h5')
model.evaluate(X_valid, y_valid)
总体而言,使用预训练词嵌入的模型实现了23.9%的验证准确性。这是非常不错,因为我们作为一个人类,也很难预测这些摘要中的下一个词!对最常用词(“the”)的猜测的准确率约为8%。notebook中所有模型的指标如下所示:

最好的模型使用的预训练嵌入与如上所示的架构相同。我鼓励任何人尝试使用不同模型的训练!
专利摘要生成
当然,虽然高指标很好,但重要的是网络是否可以产生合理的专利摘要。使用最佳模型,我们可以探索模型生成能力。如果你想在自己的硬件上运行它,你可以在GitHub上找到notebook和预训练好的模型(models)。
为了产生输出,我们使用从专利摘要中选择的随机序列为网络的‘种子“,使其预测下一个单词,将预测添加到序列中,并继续对我们想要的单词进行预测。部分结果如下:

为输出的一个重要参数是多样性的预测。我们不使用具有最高概率的预测词,而是将多样性注入到预测中,然后选择具有与更多样化预测成正比的概率的下一个词。很高的多样性使生成的输出开始看似随机,而很低的多样性,网络可以进入输出的循环。

输出也不错!有些时候很难确定哪个是计算机生成的,哪个是机器生成的。有一部分原因在于专利摘要的性质,大多数时候,摘要看起来并不像是人类写的。
网络的另一个用途是用我们自己的起始序列播种它。我们可以使用我们想要的任何文本,并看看网络会怎么生成:

当然,结果并不完全可信,但它们确实类似于英语。
人还是机器?
作为RNN的最终测试,我创建了一个游戏来猜测是人还是模型在生成输出。这是第一个示例,其中两个选项来自计算机,一个来自人类:

你会怎么猜?答案是第二个是人类写的实际摘要(嗯,实际上我不确定这些摘要是由人写的)。这是另一个示例:

这一次,第三个是人写的。
我们可以使用其他步骤来解释模型,例如找到不同的输入序列会激活哪些神经元。我们还可以查看学习嵌入(或使用Projector工具将其可视化),这些我们下次讨论。我们现在知道如何实现一个有效模拟人类文本的RNN。
结论
注意,要认识到RNN没有语言理解的概念。它实际上是一种非常复杂的模式识别机器。尽管如此,与马尔可夫链或频率分析等方法不同,RNN基于序列中的元素排序进行预测。从哲学角度讲,你或许可以认为人类只是极端模式识别机器,因此RNN只是像人类这样的机器一样运作。
RNN的使用范围远远超出了文本生成到机器翻译,图像字幕和身份识别。虽然我们在这里介绍的这个应用程序不会取代任何人类,但可以想象,通过更多的训练数据和更大的模型,神经网络将能够合成新的,更合理的专利摘要。
双向LSTM单元
我们很容易陷入细节或复杂技术背后的理论,但学习数据科学工具时,更有效的方法是研究和构建应用程序。等你知道了这种技术的能力,以及它在实践中是如何工作的,你可以再回过头来研究这个理论。我们大多数人不会设计神经网络,但值得学习如何有效地使用它们。这意味着收起你的书本,敲打键盘,编写自己的网络。
GitHub:https://github.com/WillKoehrsen/recurrent-neural-networks
更多内容:
RNN示例项目从开发到部署(二):将Keras深度学习模型部署为Web应用程序
RNN示例项目从开发到部署(三):在AWS上部署深度学习模型









