











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌开源AI新模型,区分语音准确度达到92%
2018年11月13日 由 浅浅 发表
547711
0
 Speaker diarization即根据谁说什么,以及什么时候说,将语音样本划分为独特的,同质的片段的过程,对机器来说不像人类那么容易,并且训练机器学习算法来执行它很难。具有鲁棒性的Diarization系统必须能够将新个体与之前未遇到的语音段相关联。
Speaker diarization即根据谁说什么,以及什么时候说,将语音样本划分为独特的,同质的片段的过程,对机器来说不像人类那么容易,并且训练机器学习算法来执行它很难。具有鲁棒性的Diarization系统必须能够将新个体与之前未遇到的语音段相关联。但谷歌的AI研究部门已在性能模型方面取得了不错的进展。在一篇新论文“Fully Supervised Speaker Diarization”和随附的博客文章中,研究人员描述了一种新的AI系统,该系统以更有效的方式利用受监督的说话者标签。
该论文的作者声称核心算法实现了对于实时应用程序而言足够低的在线分类错误率(DER),在NIST SRE 2000 CALLHOME基准测试中为7.6%,而谷歌之前的方法为8.8%DER。
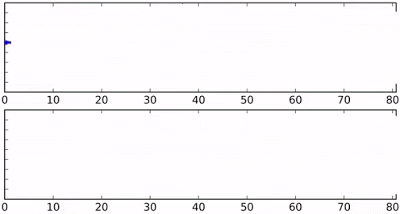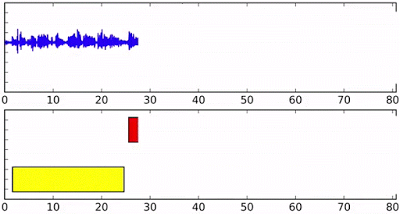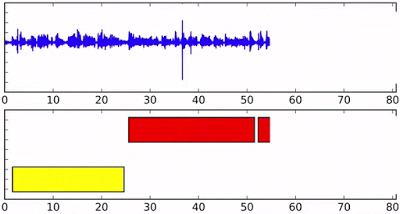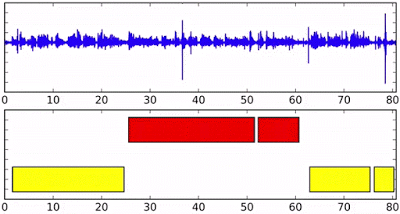
在流媒体音频上的Speaker diarization,底部轴不同的颜色表示不同的说话者。
谷歌研究人员的新方法通过递归神经网络(RNN)模拟说话者的嵌入(即单词和短语的数学表示),RNN是一种机器学习模型,可以使用其内部状态来处理输入序列。每个发言者都以自己的RNN实例开始,该实例在给定新嵌入的情况下不断更新RNN状态,使系统能够学习在说话者者和话语之间共享的高级知识。
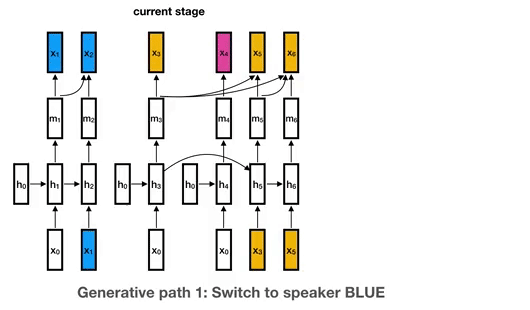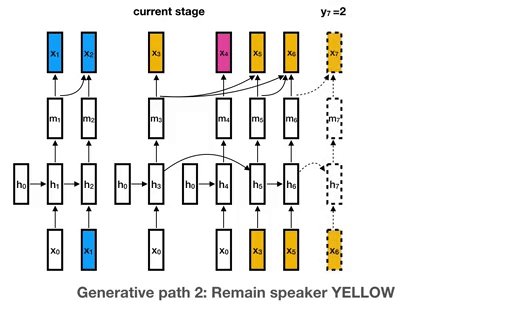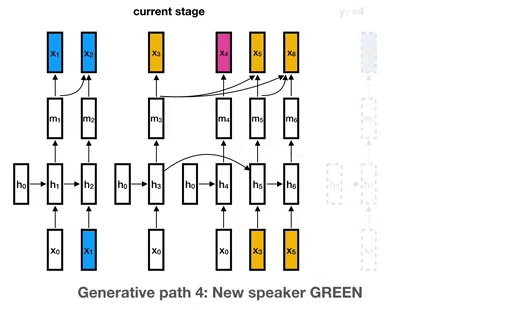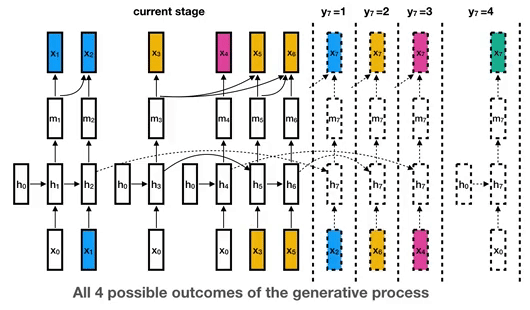
模型的生成过程。颜色表示说话者分段标签。
“由于该系统的所有组件都可以监督的方式学习,因此在可以获得具有高质量时间标记的说话者标签的训练数据的情况下,它优于无监督系统,”研究人员在论文中写道,“我们的系统受到全面监督,并且能够从带有时间标记的说话者标签的示例中学习。”
在未来的工作中,团队计划优化模型,以便它可以集成上下文信息以执行离线解码,他们期望这将进一步减少DER。他们还希望直接对声学特征进行建模,以便整个说话者系统可以进行端到端的训练。
论文:arxiv.org/abs/1810.04719
代码:github.com/google/uis-rnn

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消