











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Hive利用数十万人标记的数据,训练特定领域的AI模型
2018年11月19日 由 浅浅 发表
129668
0
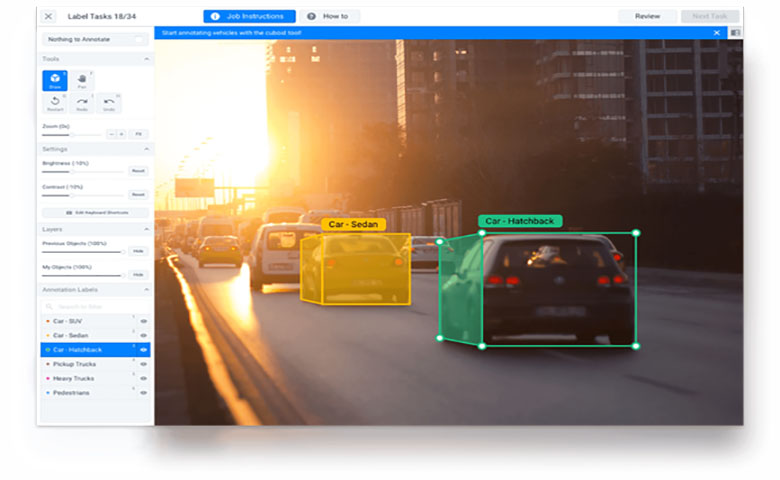 数据集是AI的生命线,它们使模型成为可能。但是,没有相应注释的数据则取决于正在运行的算法的类型(即监督VS无监督),或多或少是无用的。这就是为什么像Scale这样的样品标签创业公司筹集了数千万美元,并吸引了优步和通用汽车等客户。而Kevin Guo和Dmitriy Karpman共同创办了Hive,这是一家使用由数十万志愿者提供的注释数据来训练特定领域AI模型的创业公司。
数据集是AI的生命线,它们使模型成为可能。但是,没有相应注释的数据则取决于正在运行的算法的类型(即监督VS无监督),或多或少是无用的。这就是为什么像Scale这样的样品标签创业公司筹集了数千万美元,并吸引了优步和通用汽车等客户。而Kevin Guo和Dmitriy Karpman共同创办了Hive,这是一家使用由数十万志愿者提供的注释数据来训练特定领域AI模型的创业公司。拥有近100名员工的Hive在从PayPal的创始人Peter Thiel创始人基金和其他人那里筹集了超过3000万美元的风险投资之前,推出了旗舰产品Hive Data,Hive Predict和Hive Enterprise。
“我们建立了Hive,因为我们觉得虽然围绕AI和深度学习让人兴奋不已,但我们没有看到很多实际应用,”Guo在电话采访中表示,“时下炒作很多,但真正要解决的问题似乎并不明显。大多数都是些可以起作用的演示,但并不能作为真正的企业级方法。”
为此,Hive通过Hive Work(一个智能手机应用程序和网站)招募大量人类进行数据标记,指导他们完成分类图像和转录音频等任务。作为交换,Hive发放了一小笔奖励,每周数万美元(Guo说它可以使用“激增定价”来确保在必要时更快的周转时间,例如当Hive客户有特定项目时)。
该战略取得了成功。Hive在其贡献者社区中的30多个国家或地区拥有近700,000名用户,他们每天帮助处理大约一千万个标签,准确率达到99%(这种准确性部分归因于一个淘汰系统,它每隔一段时间就会进入“已知”任务,确保用户不会愚弄系统)。客户可以通过Hive Data来挖掘员工,Hive Data为许多垂直领域提供数据标记服务。
“获取训练数据来构建这些模型实际上非常重要。从某种意义上说,自动化的唯一方法就是招募大量的人力,这其实很具有讽刺意味,你可以拥有最好的框架,但如果没有良好的训练数据,你将无法获得良好的输出。我把它比作一个人类的头脑:你可以拥有最聪明的大脑,但如果你不教这个大脑猫狗之间的区别,并展示好的例子,它就永远不会认识到猫与狗之间的区别。”
Hive Work的输出还提供Hive Predict,为企业提供定制设计的计算机视觉模型,帮助企业实现业务流程自动化;Hive Enterprise,针对汽车,零售,安全和媒体等领域,提供从头开始构建的专有数据的定制深度学习模型。Hive使用基于谷歌开源TensorFlow框架的后端,通过API或云开发AI系统,或与集成合作伙伴合作设计内部部署解决方案。
到目前为止,凭借其内部服务器和网络基础设施,Hive创建了机器学习模型,可识别活动,预测年龄和性别,对汽车进行分类,确定相机传感器与感兴趣主体之间的距离,甚至可以检测爆炸等事件,电视节目中的枪声,战斗和广告。Guo拒绝透露Hive的任何客户的名字,但表示每个客户每个月都要发出数千万的API请求。
Hive的模型之一 Logo Model API会检测logo,但也会检测它们显示的产品或广告以及它们的持续时间。Hive声称,与Google Vision Cloud的5%召回率和66%的精确度相比,它具有的召回率为99%,精度98%。
Hive每周增加100个logo,目标是在2018年第四季度达到10,000。Guo补充道,“我们的质量标准远远高于其他,但我不希望Hive成为另一个过度炒作的AI公司。”

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消