











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






亚马逊利用神经TTS系统,仅需几个小时即可模拟独特的讲话风格
2018年11月20日 由 浅浅 发表
659857
0
 厌倦了Alexa沉稳,单调的语调?现在,由于一种新的AI技术,亚马逊可能很快就能够将新的讲话风格推广到其语音助手。
厌倦了Alexa沉稳,单调的语调?现在,由于一种新的AI技术,亚马逊可能很快就能够将新的讲话风格推广到其语音助手。在一篇新发表的论文“Effect of data reduction on sequence-to-sequence neural TTS”和随附的博客文章中,亚马逊详细介绍了一种文本到语音(TTS)系统,该系统可以学习采用一种新的讲话风格,比如新闻播音员的风格。只需几个小时的训练,就可以像新闻播报员那样讲话。传统方法需要聘请配音演员,并以目标风格朗读数十小时。
“对于用户而言,神经网络产生的合成语音听起来比通过连接方法产生的语音更自然,这种方法将存储在音频数据库中的短语音片段串联起来,”亚马逊应用科学经理Trevor Wood写道,“随着我们的系统提供的灵活性增加,我们可以轻松改变合成语音的讲话风格。”
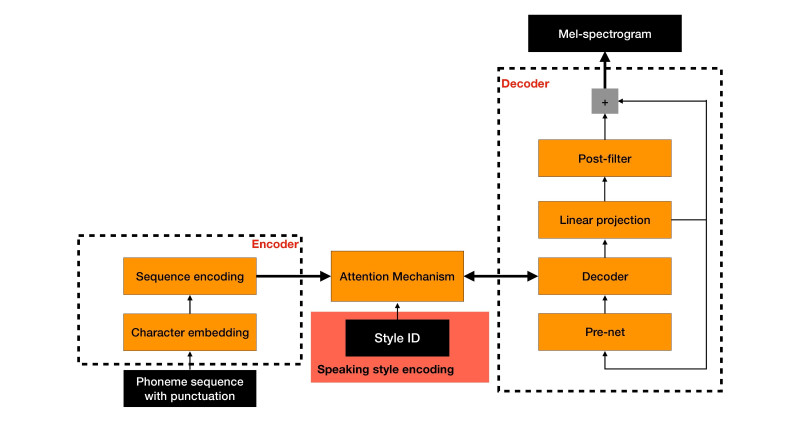
NTTS架构
亚马逊的AI模型,称为神经TTS,或简称NTTS,由两部分组成。第一部分是一个生成神经网络,它转化音素序列,区分一个词和另一个词的声音单位到声谱图(一种声音频率谱,视觉表示随时间变化)的序列中,如pad和patp中的p,b,d和t。
第二个部分是声音编码器,它可以转换那些频谱图成一个连续的音频信号,特别是有频带的mel-spectrogram,强调人脑在处理语音时使用的特征。
Wood指出,现象到光谱图解释器网络是序列到序列的,这意味着它不仅仅从相应的输入计算输出,而且考虑它在输出序列中的位置。除了“风格编码”之外,亚马逊的科学家使用现象序列和相应的mel-spectrogram序列对其进行训练,后者确定了训练示例中使用的特定讲话风格。
模型的输出被输入声音编码器,产生高质量的语音波形。独特的是,声音编码器可以从任何扬声器中获取mel-spectrogram,无论它们是否在训练时间内被看到,并且它不需要使用扬声器编码。
结果,一种模型训练方法,结合了大量中性风格的语音数据,只需几小时的所需风格的补充数据,以及能够区分语音元素的AI系统,既是独立的讲话风格,风格又独特。
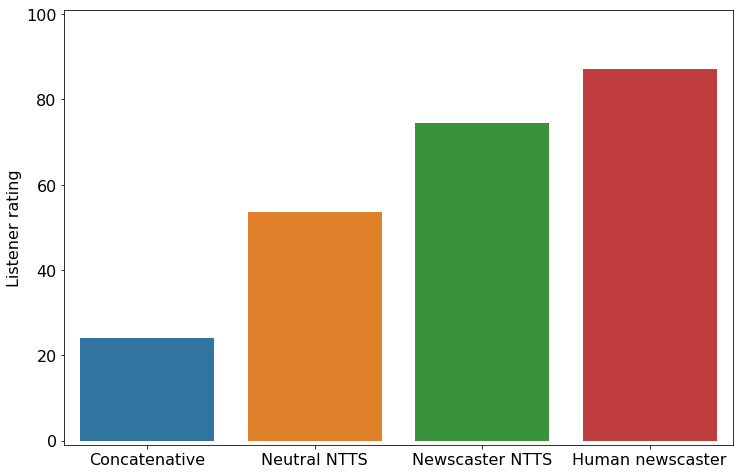
亚马逊倾听者调查结果
“当在操作过程中呈现讲话风格的代码时,网络会预测适合该风格的韵律模式,并将其应用于单独生成的,风格不可知的表示,”Wood解释道,“通过相对较少的额外训练数据实现的高质量性能,可以快速扩展演讲风格。”
根据亚马逊的研究,听众更倾向于使用NTTS产生的声音,而不是通过连接合成的声音。
Wood表示,“对中性NTTS的偏好,反映了用神经生成方法将一般语音合成质量提高的广泛报道,NTTS新闻播音员语音的进一步改进,反映了我们系统能够捕捉与文本相关的风格。”这项新的研究是在Alexa的耳语模式首次亮相之后进行的。
论文:arxiv.org/abs/1811.06315

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消