











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌等研究团队利用AI,使插入的对象更逼真地融入场景
2018年12月11日 由 浅浅 发表
616578
0
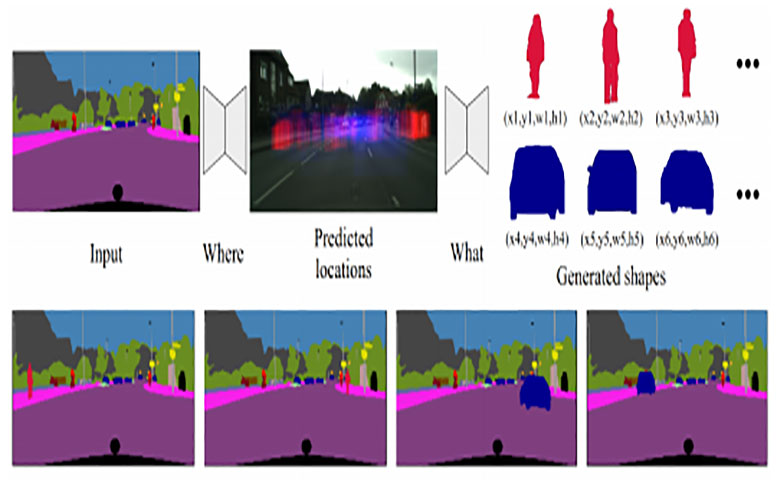 对于计算机来说,使用后期制作软件在场景中放置事物,并且让其观感逼真并不容易。它不仅需要确定所述对象的适当位置,还需要尝试预测对象在目标位置的外观,包括比例,遮挡,姿势,形状等。
对于计算机来说,使用后期制作软件在场景中放置事物,并且让其观感逼真并不容易。它不仅需要确定所述对象的适当位置,还需要尝试预测对象在目标位置的外观,包括比例,遮挡,姿势,形状等。幸运的是,AI能够在这一情境下提供帮助。NeurIPS 2018会议中的一篇论文“Context-Aware Synthesis and Placement of Object Instances”,由首尔国立大学,加州大学默塞德分校和Google AI的研究人员共同完成,描述了一个系统,学习将物体以“语义连贯”的形象插入系统,并且结果令人信服。
研究人员写道,在符合场景语义的图像中插入对象是一项具有挑战性和趣味性的任务。这项任务与许多实际应用密切相关,包括图像合成、AR和VR内容编辑以及领域随机化。这样的对象插入模型有助于促进许多图像编辑和场景解析应用程序的进步。
它们的端部到端框架包括利用GAN的两个模块,第一个用于确定插入的对象位置,另一个确定插入的对象是怎样的。因为系统同时对插入的图像建模分布,所以它使两个模块能够相互通信并优化。
论文作者表示,“这项工作的主要技术新颖之处在于构建了一个端到端的可训练神经网络,可以从新对象的联合分布中对其可能的位置和形状进行采样。合成的对象实例既可以作为基于GAN的方法的输入,也可以从现有数据集中检索最近的片段,从而生成新的图像。”
正如研究者所解释的那样,在这种情况下,生成器可以预测“合理”的位置,以生成具有“语义连贯”的比例,姿势和形状的对象蒙版,特别是对象在场景中的分布方式,以及如何自然地插入对象,使其看起来像是场景的一部分。
随着时间的推移,在训练过程中,AI系统根据场景的不同,学习不同对象类别的分布,例如,在城市街道的图像中,人们通常在人行道上,而汽车在公路上。
在测试中,研究人员的模型通过插入逼真形状的物体,使模型优于基线。当图像识别器 YOLOv3应用于AI生成的图像时,它能够通过0.79召回率来检测合成对象。更有说服力的是,在对Mechanical Turk进行的调查中,43%的人认为AI生成的物体是真实的。
研究人员表示,“这表明我们的方法能够执行对象合成和插入任务,由于我们的方法结合考虑模型的位置和样式,因此它可以用于解决其他计算机视觉问题。未来,我们研究的范围之一就是处理对象之间的遮挡。”
论文:papers.nips.cc/paper/8240-context-aware-synthesis-and-placement-of-object-instances.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消