











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






腾讯云 | 巧用机器学习定位云服务器故障
2019年01月03日 由 荟荟 发表
278401
0
导语
随着腾讯云业务的扩大,母机数量越来越多。为减少人力并实现母机故障的自动化定位,本文尝试利用机器学习算法,通过对历史故障母机的日志数据学习,训练模型实现自动化分析定位母机故障原因。
对于每一单母机故障我们都需要定位出背后真实的故障原因,以便对相应的部件进行更换以及统计各种部件故障率的情况,因此故障定位和分析消耗的人力也越来越多。希望能借助机器学习的方法对历史故障母机的日志数据进行学习,沉淀出一些模型出来实现自动化的分析新的母机故障的原因,进而提高母机工单的处理效率解放人力,同时也能分析出故障的一些规律,进而实现对故障的预测等。
1、对母机宕机故障进行自动化的分析,准确定位故障原因;
2、当故障分类准确率达到足够准确之后,能够不需要人工参与,实现自动化结单;
3、实时流式处理母机的各种数据,实现部分故障的预测。
1、dmesg :机器宕机前的最后一屏,含有netconsole数据;
2、mcelog :系统检查到硬件错误产生的日志;
3、sel :系统事件日志,是服务器传感器收集数据发现异常产生的日志。
主要步骤包括数据筛选、数据清洗、文本向量化、模型构建、结果分析等。
1)查看三类日志,分析是否每一种日志对故障定位都有存价值。剔除无价值的日志;
2)根据业务需求,选择特定的故障类别。因为某些故障的工单数量特别少,难以建立机器学习模型做分类;
3)保留三种日志不全为空的故障工单,完全无记录的工单是无法利用的;
4)根据工单编号ticket_id将日志及故障工单整合,工单和母机应该是一一对应的。
1)剔除特殊符号'#', '<', '>', '&', '@','!', '(', ')', '*', '_'等;
2)剔除日志的无用信息,如数字格式和英文格式的;
3)日志分开清洗,当不同日志的格式不一致时,需要区分对待分开清洗。
日志数据一般为文本数据,在构建文档分类模型时,需要将文本型数据转化成数值型数据。文本向量化(也叫做特征权重计算)常用以下三种方法。
1)布尔权重(Boolean vector),是最简单的权重计算方法。如果某特征词在文本中出现,其权重即为1,;不出现,即为0.这一简单粗暴的方法容易丢失文本内部具体信息,效果略差。但适用于一些采用二分类的模型,比如决策树和概率分类器。
2)频度权值(term frequence),是最直观的权重计算方法。单词在文本中出现的次数即为频度权重。这种方法的思想是,出现次数越多的特征单词,其重要性越大。

3)Tf-idf(Term Frequency-Inverse Document Frequency, 词频-逆文件频率),是应用最广泛的权值计算方法。单词在一条工单的日志中出现次数越多, 同时在所有工单中出现次数越少, 越能够代表该故障工单。
相比于频度权值,引入了IDF。IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。计算公式如下,分母之所以要加1,是为了避免分母为0
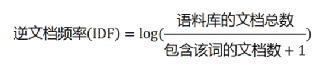
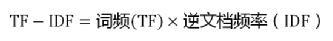
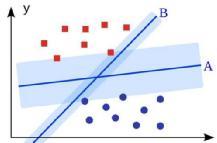
在已有数据(标记)的基础上构造出一个分类函数/分类模型, 即为一个决策面。
1)数据划分:随机分层抽样,划分训练集(70%)用于构建模型,测试集(30%)用于验证模型效果;
2)数据预处理:数据整合、数据清洗、文本分词等过程在训练集和测试集上是同样的处理方式,以确保最后的干净的训练集和测试数据的格式是统一的;
3)文本向量化:采用tf-idf将文本向量化,选择l2正则化,结合文档频率df和最大词频tf进行特征选择,选出若干个关键词;设置停用词['is', 'not', 'this', 'the', 'do', 'in']等;
4)模型构建:选取分类问题常用的算法构建模型,构建模型过程中不断参数调优,构建最佳的模型。
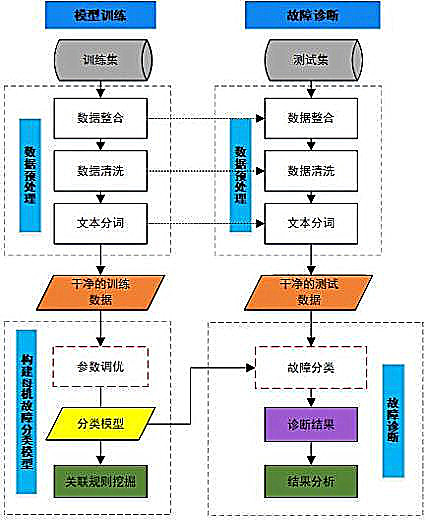
注:对于数量特别少的故障类型,如果依靠专家知识分析已有的工单日志能够一一正确区分的话,那么可以人为地抽象出独一无二的故障特征,并编写模块实现自动化分类。
故障诊断阶段,将构建好的模型运用到测试集上,对故障诊断结果分析。以决策树建立故障诊断模型,可见在训练集上的效果可达98.94%,测试集上可达90.24%。
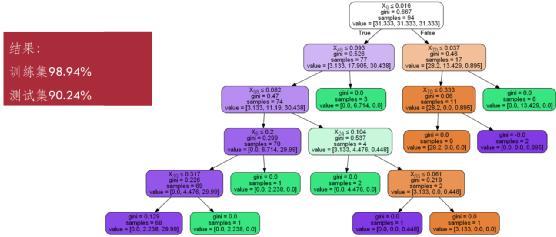
为进一步提高模型性能,一方面应具体分析训练集和测试集上被错误分类的故障工单,查看三种日志的内容并查找问题;另一方面,可增加更多的数据用于构建模型,一般而言,数据量越大,模型越接近。
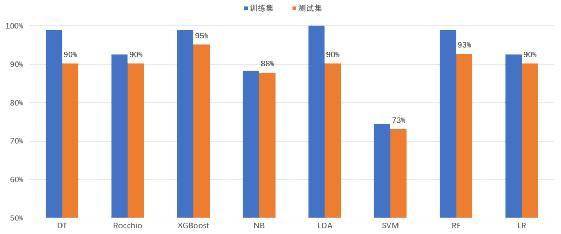
不同算法:尝试采用不同的文本分类算法用于故障分类,测试效果能反映出该算法对当前问题的适用性。如下,笔者采用了8种算法进行对比,并对结果进行总结分析。

关联规则:左键 ->右键,左键的组合导致右键的发生。引入关联规则挖掘,可进一步分析日志中关键词的出现,可以如何判定某一类故障的发生。譬如当{'TSC', 'CPU', 'Hardware', 'Error'}等词同时出现时,可理解为当这些关键词出现时,有89.1%的置信度人为发生了硬件故障-内存故障。
从工程实践的角度出发,笔者提出以下几种可能的解决方案,以作为对上面方法步骤的补充:
1.故障分级:将故障划分等级,如一级故障(硬件故障-软件故障),二级故障为硬件故障下更具体的故障类型。当直接对所有二级故障做分类效果不理想时,可先考虑对一级故障做分类,再对二级故障做分类,实现故障分级的效果。
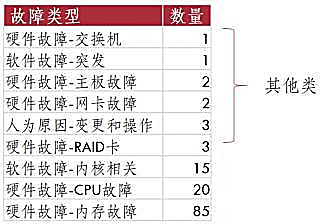
2.数据不平衡:即不同类别的故障工单在数量级上不一致,数据量上相差较大,使得分类模型偏向于数量多的故障。考虑到故障工单数据不平衡的问题,可考虑将数目少的归总为一类——其他类。示例如下,九分类问题可被转化为四分类问题。但是,在工单数量严重不平衡而且故障类别多的情况下,这种归总少类样本为其他类的方法,使得模型分类效果具有较大的随机性。
3.多字特征词:原理即将文本内容按字节流进行大小为N的滑动窗口操作,形成长度为N的字节片段序列,以自动产生多字特征词。相比于分开存在,几个单词的连续出现可能会有产生不一样的意义,对分类产生影响。
4.布尔权重:CPU发生故障时,CPU多核故障和单核故障属于同一类,但多核故障会记录每一个核的情况,导致某些关键词或者格式重复出现,使得模型对于两者的相似性降低。此时,可考虑使用布尔权重代替tf-idf进行文本向量化。
由于文本分类涵盖的内容较多,本文尽可能从简出发,阐述母机日志分析的大体流程,以及工程实践上的解决方案,以供交流。对于文本分类特征选择,模型参数调优和数据不平衡的更为详细的解决方法,笔者将在后续跟进。
随着腾讯云业务的扩大,母机数量越来越多。为减少人力并实现母机故障的自动化定位,本文尝试利用机器学习算法,通过对历史故障母机的日志数据学习,训练模型实现自动化分析定位母机故障原因。
背景
对于每一单母机故障我们都需要定位出背后真实的故障原因,以便对相应的部件进行更换以及统计各种部件故障率的情况,因此故障定位和分析消耗的人力也越来越多。希望能借助机器学习的方法对历史故障母机的日志数据进行学习,沉淀出一些模型出来实现自动化的分析新的母机故障的原因,进而提高母机工单的处理效率解放人力,同时也能分析出故障的一些规律,进而实现对故障的预测等。
目标
1、对母机宕机故障进行自动化的分析,准确定位故障原因;
2、当故障分类准确率达到足够准确之后,能够不需要人工参与,实现自动化结单;
3、实时流式处理母机的各种数据,实现部分故障的预测。
数据
1、dmesg :机器宕机前的最后一屏,含有netconsole数据;
2、mcelog :系统检查到硬件错误产生的日志;
3、sel :系统事件日志,是服务器传感器收集数据发现异常产生的日志。
方法步骤
主要步骤包括数据筛选、数据清洗、文本向量化、模型构建、结果分析等。
数据筛选
1)查看三类日志,分析是否每一种日志对故障定位都有存价值。剔除无价值的日志;
2)根据业务需求,选择特定的故障类别。因为某些故障的工单数量特别少,难以建立机器学习模型做分类;
3)保留三种日志不全为空的故障工单,完全无记录的工单是无法利用的;
4)根据工单编号ticket_id将日志及故障工单整合,工单和母机应该是一一对应的。
数据清洗
1)剔除特殊符号'#', '<', '>', '&', '@','!', '(', ')', '*', '_'等;
2)剔除日志的无用信息,如数字格式和英文格式的;
3)日志分开清洗,当不同日志的格式不一致时,需要区分对待分开清洗。
文本向量化
日志数据一般为文本数据,在构建文档分类模型时,需要将文本型数据转化成数值型数据。文本向量化(也叫做特征权重计算)常用以下三种方法。
1)布尔权重(Boolean vector),是最简单的权重计算方法。如果某特征词在文本中出现,其权重即为1,;不出现,即为0.这一简单粗暴的方法容易丢失文本内部具体信息,效果略差。但适用于一些采用二分类的模型,比如决策树和概率分类器。
2)频度权值(term frequence),是最直观的权重计算方法。单词在文本中出现的次数即为频度权重。这种方法的思想是,出现次数越多的特征单词,其重要性越大。
3)Tf-idf(Term Frequency-Inverse Document Frequency, 词频-逆文件频率),是应用最广泛的权值计算方法。单词在一条工单的日志中出现次数越多, 同时在所有工单中出现次数越少, 越能够代表该故障工单。
相比于频度权值,引入了IDF。IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。计算公式如下,分母之所以要加1,是为了避免分母为0
模型构建
在已有数据(标记)的基础上构造出一个分类函数/分类模型, 即为一个决策面。
1)数据划分:随机分层抽样,划分训练集(70%)用于构建模型,测试集(30%)用于验证模型效果;
2)数据预处理:数据整合、数据清洗、文本分词等过程在训练集和测试集上是同样的处理方式,以确保最后的干净的训练集和测试数据的格式是统一的;
3)文本向量化:采用tf-idf将文本向量化,选择l2正则化,结合文档频率df和最大词频tf进行特征选择,选出若干个关键词;设置停用词['is', 'not', 'this', 'the', 'do', 'in']等;
4)模型构建:选取分类问题常用的算法构建模型,构建模型过程中不断参数调优,构建最佳的模型。
注:对于数量特别少的故障类型,如果依靠专家知识分析已有的工单日志能够一一正确区分的话,那么可以人为地抽象出独一无二的故障特征,并编写模块实现自动化分类。
结果分析
故障诊断阶段,将构建好的模型运用到测试集上,对故障诊断结果分析。以决策树建立故障诊断模型,可见在训练集上的效果可达98.94%,测试集上可达90.24%。
为进一步提高模型性能,一方面应具体分析训练集和测试集上被错误分类的故障工单,查看三种日志的内容并查找问题;另一方面,可增加更多的数据用于构建模型,一般而言,数据量越大,模型越接近。
不同算法:尝试采用不同的文本分类算法用于故障分类,测试效果能反映出该算法对当前问题的适用性。如下,笔者采用了8种算法进行对比,并对结果进行总结分析。
关联规则:左键 ->右键,左键的组合导致右键的发生。引入关联规则挖掘,可进一步分析日志中关键词的出现,可以如何判定某一类故障的发生。譬如当{'TSC', 'CPU', 'Hardware', 'Error'}等词同时出现时,可理解为当这些关键词出现时,有89.1%的置信度人为发生了硬件故障-内存故障。
解决方案补充
从工程实践的角度出发,笔者提出以下几种可能的解决方案,以作为对上面方法步骤的补充:
1.故障分级:将故障划分等级,如一级故障(硬件故障-软件故障),二级故障为硬件故障下更具体的故障类型。当直接对所有二级故障做分类效果不理想时,可先考虑对一级故障做分类,再对二级故障做分类,实现故障分级的效果。
2.数据不平衡:即不同类别的故障工单在数量级上不一致,数据量上相差较大,使得分类模型偏向于数量多的故障。考虑到故障工单数据不平衡的问题,可考虑将数目少的归总为一类——其他类。示例如下,九分类问题可被转化为四分类问题。但是,在工单数量严重不平衡而且故障类别多的情况下,这种归总少类样本为其他类的方法,使得模型分类效果具有较大的随机性。
3.多字特征词:原理即将文本内容按字节流进行大小为N的滑动窗口操作,形成长度为N的字节片段序列,以自动产生多字特征词。相比于分开存在,几个单词的连续出现可能会有产生不一样的意义,对分类产生影响。
4.布尔权重:CPU发生故障时,CPU多核故障和单核故障属于同一类,但多核故障会记录每一个核的情况,导致某些关键词或者格式重复出现,使得模型对于两者的相似性降低。此时,可考虑使用布尔权重代替tf-idf进行文本向量化。
后续
由于文本分类涵盖的内容较多,本文尽可能从简出发,阐述母机日志分析的大体流程,以及工程实践上的解决方案,以供交流。对于文本分类特征选择,模型参数调优和数据不平衡的更为详细的解决方法,笔者将在后续跟进。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消