











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






听觉感知:声音分类的迁移学习
2017年07月23日 由 xiaoshan.xiang 发表
197068
0
识别我们周围环境中的声音是我们人类每天很轻松就能做到的事情,但是对于计算机相当困难。如果计算机可以准确识别声音,它将会在机器人,安全和许多其他领域得到广泛应用。
最近有许多与计算机视觉有关的发展,通过深入学习和建立大型数据集如 ImageNet 来训练深入学习模型。
然而,听觉感知领域还没有完全赶上计算机视觉。谷歌三月份发布了AudioSet,这是一种大型的带注释的声音数据集。希望我们能看到声音分类和类似领域的主要改进。
在这篇文章中,我们将会研究如何利用图像分类方面的最新进展来改善声音分类。
我们的目标是使用机器学习对环境中的不同声音进行分类。对于这个任务,我们将使用一个名为UrbanSound8K的数据集。此数据集包含8732个音频文件。有10种不同类型的声音:
冷气机
汽车喇叭
儿童玩耍
狗吠声
钻孔
发动机空转
枪射击
手持式凿岩机
警笛
街头音乐
每个录音长度约为4s。数据集被组织成10个折叠。我们训练这些数据集,因为我们使用的脚本会自动生成验证集。这个数据集是一个很好的开始试验的规模,但最终我希望在AudioSet上训练一个模型。
有许多不同的特性可以训练我们的模型。在相关的语音识别领域中,通常使用mell -频率感知系数(MFCC)。MFCC的优点是它们是原始音频的一个非常稀疏的表示形式,通常在16khz的大多数研究数据集中取样。
然而,最近有一种直接针对原始数据的培训模式的转变。例如,DeepMind设计了一个名为WaveNet 的卷积架构来生成音频。这些WaveNets是基于原始音频进行培训的,它们不仅可以用于生成音频,还可以用于语音识别和其他分类任务。
能够在比MFCC功能更多的信息上对模型进行培训是件好事,但是WaveNets可以在计算上花费很高的成本,同时也可以运行。如果有一个特性保留了原始信号的大量信息,而且计算起来也很便宜,那该怎么办呢?
这是就是频谱图有用的地方。在听觉研究中,频谱图是在垂直轴表示频率,在水平轴表示时间的音频的图示,而第三维颜色表示每个时间点x频率位置处的声音的强度。
例如,这里是小提琴演奏的频谱图:
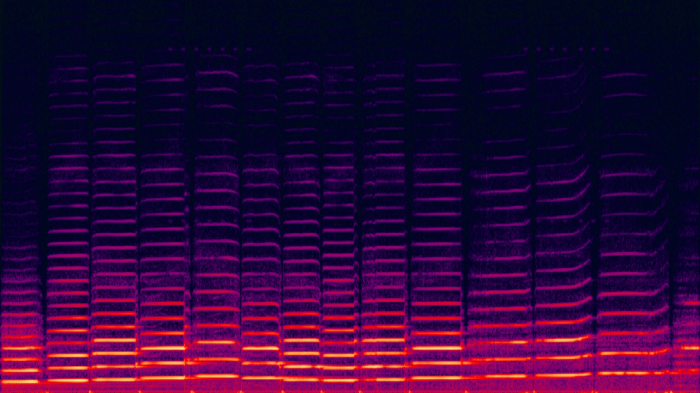
链接:CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=202335
在这个频谱图中,我们可以看到许多频率,是音符的基本频率的数倍。这些在音乐里被称为和音。频谱图中的垂直线是弓在拉小提琴拉时的短暂停顿。所以看起来谱图包含了很多有关不同声音的性质的信息。
使用频谱图的另一个好处就是我们现在把问题变成了一个图像分类,图像分类最近有了很多的突破。
这是有一个可以将每个wav文件转换成频谱图的脚本。每个频谱图存储在与其类别相对应的文件夹中。
现在声音被表示为图像,我们可以使用神经网络对它们进行分类。大多数图像处理任务选择的神经网络是卷积神经网络(CNN)。
使用UrbanSound8K数据集的问题是,它对于深度学习应用程序来说非常小。如果我们从头开始训练一个CNN,它可能会过度拟合数据,例如,它会记住在UrbanSound8K中狗吠声的所有声音,但无法概括出现实世界中其他狗狗的叫声。 这里有Aaqib Saeed博客上使用CNN的例子。然而,我们将采取不同的方法使用迁移学习。
迁移学习是我们在一个神经网络上接受过类似的数据集的训练,并重新训练了网络的最后几层来进行新的分类。这个想法是,网络的开始层正在解决诸如边缘检测和基本形状检测的问题,这将推广到其他类别。具体来说,Google已经发布了一个名为“Inception”的预培训模型,该模型已经接受了ImageNet数据集中分类图像的训练。事实上,Tensorflow已经有一个示例脚本,用于在新类别上重新训练Inception。
开始,我们将调整来自Tanticflow for Poet Google Codelab 的示例。
首先,运行此命令下载再培训脚本。
现在我们可以运行脚本来重新训练我们的频谱图
在另一个终端选项卡中,您可以运行
开始一个tensorboard,在浏览器中观察培训进度和准确性。在大约16k次迭代之后,验证集的精度达大约达到86%。对于一个相当初步的分类方法来说还是不错的。
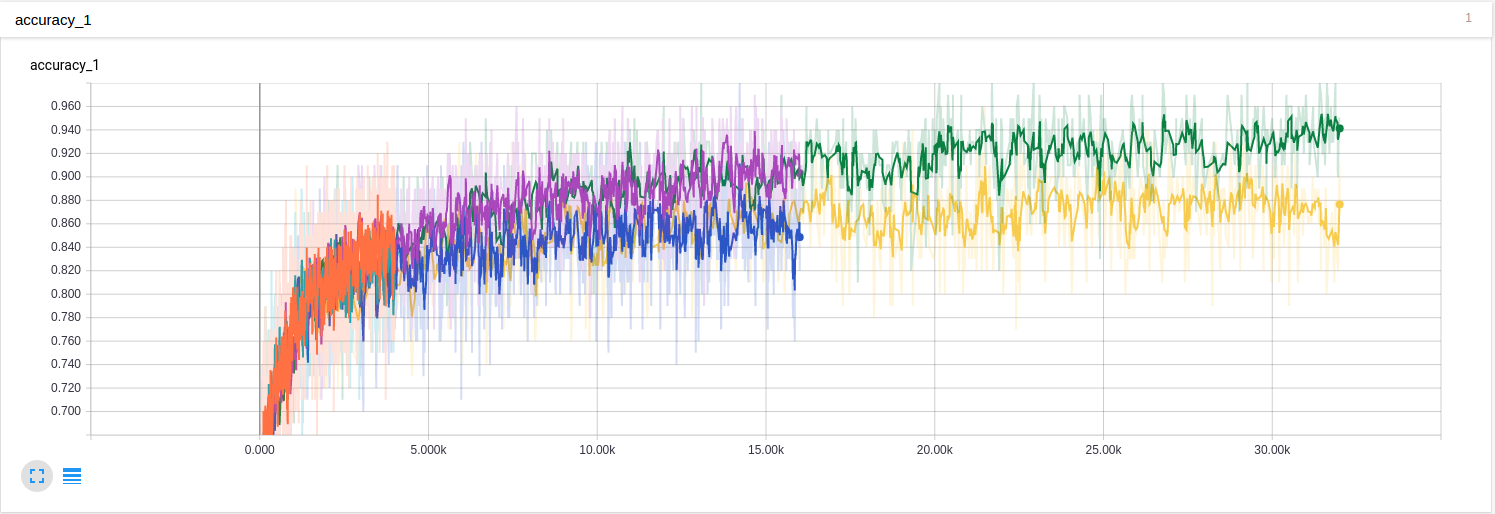
现在我们有一个分类声音的模型,可以将其应用于分类麦克风声音。Tensorflow再训练示例有用于标记图像的脚本。
我修改了这个脚本来标记麦克风的声音。首先,脚本使用pyaudio从麦克风播放音频,并使用webrtcvad包来检测麦克风是否存在声音。如果存在声音,则记录3秒钟,然后转换成谱图,最后标记。
脚本改编自该要旨,用于麦克风声音的记录,并且这要旨使用librosa生成频谱图,以及将label_image.py在tensorflow标注脚本。
在这篇文章中,我们看到了如何通过将迁移学习应用于图像分类域来分类声音。通过调整再培训的参数,或通过在光谱图上从头开始训练模型,绝对有改进的余地。我还希望训练一个模型来对声音进行分类,然后使用WaveNet 。
你可以在这里.查阅本教程的代码
本文为编译作品,作者 LUKAS GRASSE,原网站为
http://tatalab.ca/2017/07/17/transfer-learning-for-sound-classification/
最近有许多与计算机视觉有关的发展,通过深入学习和建立大型数据集如 ImageNet 来训练深入学习模型。
然而,听觉感知领域还没有完全赶上计算机视觉。谷歌三月份发布了AudioSet,这是一种大型的带注释的声音数据集。希望我们能看到声音分类和类似领域的主要改进。
在这篇文章中,我们将会研究如何利用图像分类方面的最新进展来改善声音分类。
在城市环境中分类声音
我们的目标是使用机器学习对环境中的不同声音进行分类。对于这个任务,我们将使用一个名为UrbanSound8K的数据集。此数据集包含8732个音频文件。有10种不同类型的声音:
冷气机
汽车喇叭
儿童玩耍
狗吠声
钻孔
发动机空转
枪射击
手持式凿岩机
警笛
街头音乐
每个录音长度约为4s。数据集被组织成10个折叠。我们训练这些数据集,因为我们使用的脚本会自动生成验证集。这个数据集是一个很好的开始试验的规模,但最终我希望在AudioSet上训练一个模型。
特性
有许多不同的特性可以训练我们的模型。在相关的语音识别领域中,通常使用mell -频率感知系数(MFCC)。MFCC的优点是它们是原始音频的一个非常稀疏的表示形式,通常在16khz的大多数研究数据集中取样。
然而,最近有一种直接针对原始数据的培训模式的转变。例如,DeepMind设计了一个名为WaveNet 的卷积架构来生成音频。这些WaveNets是基于原始音频进行培训的,它们不仅可以用于生成音频,还可以用于语音识别和其他分类任务。
能够在比MFCC功能更多的信息上对模型进行培训是件好事,但是WaveNets可以在计算上花费很高的成本,同时也可以运行。如果有一个特性保留了原始信号的大量信息,而且计算起来也很便宜,那该怎么办呢?
这是就是频谱图有用的地方。在听觉研究中,频谱图是在垂直轴表示频率,在水平轴表示时间的音频的图示,而第三维颜色表示每个时间点x频率位置处的声音的强度。
例如,这里是小提琴演奏的频谱图:
链接:CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=202335
在这个频谱图中,我们可以看到许多频率,是音符的基本频率的数倍。这些在音乐里被称为和音。频谱图中的垂直线是弓在拉小提琴拉时的短暂停顿。所以看起来谱图包含了很多有关不同声音的性质的信息。
使用频谱图的另一个好处就是我们现在把问题变成了一个图像分类,图像分类最近有了很多的突破。
这是有一个可以将每个wav文件转换成频谱图的脚本。每个频谱图存储在与其类别相对应的文件夹中。
使用卷积神经网络
现在声音被表示为图像,我们可以使用神经网络对它们进行分类。大多数图像处理任务选择的神经网络是卷积神经网络(CNN)。
使用UrbanSound8K数据集的问题是,它对于深度学习应用程序来说非常小。如果我们从头开始训练一个CNN,它可能会过度拟合数据,例如,它会记住在UrbanSound8K中狗吠声的所有声音,但无法概括出现实世界中其他狗狗的叫声。 这里有Aaqib Saeed博客上使用CNN的例子。然而,我们将采取不同的方法使用迁移学习。
迁移学习是我们在一个神经网络上接受过类似的数据集的训练,并重新训练了网络的最后几层来进行新的分类。这个想法是,网络的开始层正在解决诸如边缘检测和基本形状检测的问题,这将推广到其他类别。具体来说,Google已经发布了一个名为“Inception”的预培训模型,该模型已经接受了ImageNet数据集中分类图像的训练。事实上,Tensorflow已经有一个示例脚本,用于在新类别上重新训练Inception。
开始,我们将调整来自Tanticflow for Poet Google Codelab 的示例。
首先,运行此命令下载再培训脚本。
curl -O https://raw.githubusercontent.com/tensorflow/tensorflow/r1.1/tensorflow/examples/image_retraining/retrain.py
现在我们可以运行脚本来重新训练我们的频谱图
python retrain.py \
--bottleneck_dir=bottlenecks \
--how_many_training_steps=8000 \
--model_dir=inception \
--summaries_dir=training_summaries/basic \
--output_graph=retrained_graph.pb \
--output_labels=retrained_labels.txt \
--image_dir=spectrograms
在另一个终端选项卡中,您可以运行
tensorboard --logdir training_summaries
开始一个tensorboard,在浏览器中观察培训进度和准确性。在大约16k次迭代之后,验证集的精度达大约达到86%。对于一个相当初步的分类方法来说还是不错的。
分类来自麦克风的声音
现在我们有一个分类声音的模型,可以将其应用于分类麦克风声音。Tensorflow再训练示例有用于标记图像的脚本。
我修改了这个脚本来标记麦克风的声音。首先,脚本使用pyaudio从麦克风播放音频,并使用webrtcvad包来检测麦克风是否存在声音。如果存在声音,则记录3秒钟,然后转换成谱图,最后标记。
脚本改编自该要旨,用于麦克风声音的记录,并且这要旨使用librosa生成频谱图,以及将label_image.py在tensorflow标注脚本。
下一步
在这篇文章中,我们看到了如何通过将迁移学习应用于图像分类域来分类声音。通过调整再培训的参数,或通过在光谱图上从头开始训练模型,绝对有改进的余地。我还希望训练一个模型来对声音进行分类,然后使用WaveNet 。
你可以在这里.查阅本教程的代码
本文为编译作品,作者 LUKAS GRASSE,原网站为
http://tatalab.ca/2017/07/17/transfer-learning-for-sound-classification/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消