











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






旷视科技再现硬实力——首个深度学习GIF质量增强方法被提出
2019年01月16日 由 荟荟 发表
286231
0
图形交换格式(GIF)是一种高度可移植的图形格式,在Internet上无处不在。尽管它们的尺寸小,但将视频转化为GIF图像通常包含不期望的视觉伪像,例如平面颜色区域,伪轮廓,色移和点状图案。在本文中,旷视提出了GIF2Video,这是第一个用于提高GIF视觉质量的方法。主要通过颜色反量化和插帧(frame interpolation)两方面。首先旷视提出了一种用于颜色去量化的新型CNN架构,它基于多步色彩校正的组合架构。然后,将SuperSlomo网络(SuperSlomo 是新近提出的一种神经网络,专为变长式多帧插值)用于GIF帧的时间插值。最后为培训和评估引入了两个大型数据集,即GIF-Faces和GIF-Moments。实验结果表明,该方法可以显著提高GIF的视觉质量,并优于直接基线和最先进的方法。
论文链接:https://arxiv.org/pdf/1901.02840.pdf
其实早在18年,旷视就被任命牵头承办国家重点计划研发项目“下一代深度学习理论、方法与关键技术”。据悉,该项目共有 5 个子课题,其中由旷视科技承办的课题为“深度学习工作机理的理论框架与分析方法”请见下图:
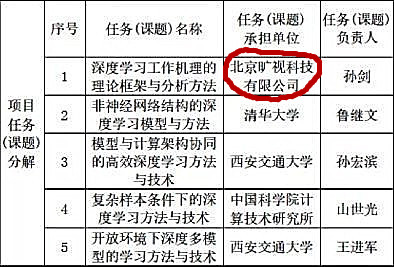
旷视是中国最早用深度学习的方法的科技企业之一,2015年旷视科技推出自研深度学习引擎 MegBrain 及深度学习平台 Brain++,实现内部深度学习的计算和数据资源管理自动化,以及算法训练流程化 。在自有的深度学习引擎和基础数据架构之上,旷视研究院还将持续围绕分类、检测和分割等图像识别的核心问题,以及云端、移动端、芯片等不同平台的深度学习模型实现算法创新,使其最终能够服务于平台化的产品、改善产品体验和品质。可以说,在深度学习技术方面,旷视科技有着其他AI企业不可替代的独特优势。
ICCV 2017 旷视科技打破谷歌、微软垄断,成为第一个问鼎 COCO 冠军的中国公司,CVPR 2018 旷视科技更是全面进击,具体汇总如下:







而据ECCV 2018 官网信息,旷视科技共有 10 篇接收论文。从内容上看,论文涵盖 CV 技术的多个层面,小到一个新表示的提出,大到一个新模型的设计,乃至神经网络设计原则和新任务、新方法的制定,甚至弱监督学习的新探索,不一而足。具体而言,旷视科技在以下技术领域实现新突破:
神经网络架构设计领域,ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design 不仅授之以鱼,还授之以渔,针对移动端深度学习提出第二代卷积神经网络 ShuffleNet V2,实现速度与精度的最优权衡,同时给出了神经网络架构的四个实用设计准则。这无疑将加速推进由深度学习驱动的计算机视觉技术在移动端的全面落地。此外,论文还提出网络架构设计应该考虑直接指标,比如速度,而不是间接指标,比如 FLOPs。
通用物体检测方面,旷视科技通过设计 1)新型骨干网络 DetNet 和 2)目标定位新架构 IoU-Net 推动该领域的发展。
DetNet: A Backbone network for Object Detection 的设计灵感源自图像分类与物体检测任务之间存在的落差。详细讲,DetNet 针对不同大小和尺度的物体而像 FPN 一样使用了更多的 stage;即便如此,在保留更大的特征图分辨率方面,它依然优于 ImageNet 预训练模型。但是,这会增加神经网络的计算和内存成本。为保证效率,旷视研究员又引入低复杂度的 Dilated Bottleneck,兼得较高的分辨率和较大的感受野。DetNet 不仅针对分类任务做了优化,对定位也很友好,并在 COCO 上的物体检测和实例分割任务中展现了出色的结果。
Acquisition of Localization Confidence for Accurate Object Detection(IoU-Net)实现了作为计算机视觉基石的目标检测技术的底层性原创突破。具体而言,通过学习预测与对应真实目标的 IoU,IoU-Net 可检测到的边界框的「定位置信度」,实现一种 IoU-guided NMS 流程,从而防止定位更准确的边界框被抑制。IoU-Net 很直观,可轻松集成到多种不同的检测模型中,大幅提升定位准确度。MS COCO 实验结果表明了该方法的有效性和实际应用潜力。研究员同时希望这些新视角可以启迪未来的目标检测工作。
旷视科技语义分割领域的论文占比最高:1)实现实时语义分割的双向网络 BiSeNet;2)优化解决语义分割特征融合问题的新方法 ExFuse;以及 3)通过实例级显著性检测和图划分实现弱监督语义分割的新方法。
BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation 的提出基于三种主流的实时语义分割模型加速方法,并在特征融合模块和注意力优化模块的帮助下,把实时语义分割的性能推进到一个新高度。
ExFuse: Enhancing Feature Fusion for Semantic Segmentation 针对语义分割主流方法直接融合高低特征不奏效的问题而提出,创新性地在低级特征引入语义信息,在高级特征嵌入空间信息,优化解决特征融合的问题。
Associating Inter-Image Salient Instances for Weakly Supervised Semantic Segmentation 通过整合显著性检测和图划分算法,提出一种新型弱监督学习方法,加速语义分割发展,其最大亮点是既利用每个显著性实例的内在属性,又挖掘整个数据集范围内不同显著性实例的相互关系。
旷视科技借助统一感知解析网络 UPerNet 来优化场景理解问题。Unified Perceptual Parsing for Scene Understanding 提出名为统一感知解析 UPP 的新任务,要求机器视觉系统从一张图像中识别出尽可能多的视觉概念;又提出多任务框架 UPerNet,开发训练策略以学习混杂标注。UPP 基准测试结果表明,UPerNet 可有效分割大量的图像概念。
不难看出,深度学习技术和人工智能的快速发展已经牵引着企业乃至全球的目光,并逐渐成为国家竞争硬实力的关键因素。
更多旷视科技深度学习类职位信息,请关注:旷视科技企业招聘 http://megvii.b.atyun.com
论文链接:https://arxiv.org/pdf/1901.02840.pdf
关于旷视深度学习技术
其实早在18年,旷视就被任命牵头承办国家重点计划研发项目“下一代深度学习理论、方法与关键技术”。据悉,该项目共有 5 个子课题,其中由旷视科技承办的课题为“深度学习工作机理的理论框架与分析方法”请见下图:
旷视是中国最早用深度学习的方法的科技企业之一,2015年旷视科技推出自研深度学习引擎 MegBrain 及深度学习平台 Brain++,实现内部深度学习的计算和数据资源管理自动化,以及算法训练流程化 。在自有的深度学习引擎和基础数据架构之上,旷视研究院还将持续围绕分类、检测和分割等图像识别的核心问题,以及云端、移动端、芯片等不同平台的深度学习模型实现算法创新,使其最终能够服务于平台化的产品、改善产品体验和品质。可以说,在深度学习技术方面,旷视科技有着其他AI企业不可替代的独特优势。
ICCV 2017 旷视科技打破谷歌、微软垄断,成为第一个问鼎 COCO 冠军的中国公司,CVPR 2018 旷视科技更是全面进击,具体汇总如下:
1.旷视(Face++)研究院发表了《ShuffleNet:一种极高效的移动端卷积神经网络》
2.旷视科技Face++提出用于语义分割的判别特征网络DFN
3.旷视科技Face++提出RepLoss,优化解决密集遮挡问题
4.旷视科技Face++新方法——通过角点定位和区域分割检测场景文本
5.旷视科技Face++率先提出DocUNet 可复原扭曲的文档图像
6.旷视科技人体姿态估计冠军论文——级联金字塔网络CPN
7.旷视科技物体检测冠军论文——大型 mini-batch 检测器MegDet
而据ECCV 2018 官网信息,旷视科技共有 10 篇接收论文。从内容上看,论文涵盖 CV 技术的多个层面,小到一个新表示的提出,大到一个新模型的设计,乃至神经网络设计原则和新任务、新方法的制定,甚至弱监督学习的新探索,不一而足。具体而言,旷视科技在以下技术领域实现新突破:
神经网络架构设计领域,ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design 不仅授之以鱼,还授之以渔,针对移动端深度学习提出第二代卷积神经网络 ShuffleNet V2,实现速度与精度的最优权衡,同时给出了神经网络架构的四个实用设计准则。这无疑将加速推进由深度学习驱动的计算机视觉技术在移动端的全面落地。此外,论文还提出网络架构设计应该考虑直接指标,比如速度,而不是间接指标,比如 FLOPs。
通用物体检测方面,旷视科技通过设计 1)新型骨干网络 DetNet 和 2)目标定位新架构 IoU-Net 推动该领域的发展。
DetNet: A Backbone network for Object Detection 的设计灵感源自图像分类与物体检测任务之间存在的落差。详细讲,DetNet 针对不同大小和尺度的物体而像 FPN 一样使用了更多的 stage;即便如此,在保留更大的特征图分辨率方面,它依然优于 ImageNet 预训练模型。但是,这会增加神经网络的计算和内存成本。为保证效率,旷视研究员又引入低复杂度的 Dilated Bottleneck,兼得较高的分辨率和较大的感受野。DetNet 不仅针对分类任务做了优化,对定位也很友好,并在 COCO 上的物体检测和实例分割任务中展现了出色的结果。
Acquisition of Localization Confidence for Accurate Object Detection(IoU-Net)实现了作为计算机视觉基石的目标检测技术的底层性原创突破。具体而言,通过学习预测与对应真实目标的 IoU,IoU-Net 可检测到的边界框的「定位置信度」,实现一种 IoU-guided NMS 流程,从而防止定位更准确的边界框被抑制。IoU-Net 很直观,可轻松集成到多种不同的检测模型中,大幅提升定位准确度。MS COCO 实验结果表明了该方法的有效性和实际应用潜力。研究员同时希望这些新视角可以启迪未来的目标检测工作。
旷视科技语义分割领域的论文占比最高:1)实现实时语义分割的双向网络 BiSeNet;2)优化解决语义分割特征融合问题的新方法 ExFuse;以及 3)通过实例级显著性检测和图划分实现弱监督语义分割的新方法。
BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation 的提出基于三种主流的实时语义分割模型加速方法,并在特征融合模块和注意力优化模块的帮助下,把实时语义分割的性能推进到一个新高度。
ExFuse: Enhancing Feature Fusion for Semantic Segmentation 针对语义分割主流方法直接融合高低特征不奏效的问题而提出,创新性地在低级特征引入语义信息,在高级特征嵌入空间信息,优化解决特征融合的问题。
Associating Inter-Image Salient Instances for Weakly Supervised Semantic Segmentation 通过整合显著性检测和图划分算法,提出一种新型弱监督学习方法,加速语义分割发展,其最大亮点是既利用每个显著性实例的内在属性,又挖掘整个数据集范围内不同显著性实例的相互关系。
旷视科技借助统一感知解析网络 UPerNet 来优化场景理解问题。Unified Perceptual Parsing for Scene Understanding 提出名为统一感知解析 UPP 的新任务,要求机器视觉系统从一张图像中识别出尽可能多的视觉概念;又提出多任务框架 UPerNet,开发训练策略以学习混杂标注。UPP 基准测试结果表明,UPerNet 可有效分割大量的图像概念。
不难看出,深度学习技术和人工智能的快速发展已经牵引着企业乃至全球的目光,并逐渐成为国家竞争硬实力的关键因素。
更多旷视科技深度学习类职位信息,请关注:旷视科技企业招聘 http://megvii.b.atyun.com

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消