











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






必备基础:一文全面了解深度学习
2019年01月19日 由 浅浅 发表
594254
0
 我们生活在这样一个世界:无论好坏,我们总是被深度学习算法所包围。从社交网络过滤到自动驾驶汽车,再到电影推荐,金融欺诈检测,药物发现……深度学习影响着我们的生活和决策。
我们生活在这样一个世界:无论好坏,我们总是被深度学习算法所包围。从社交网络过滤到自动驾驶汽车,再到电影推荐,金融欺诈检测,药物发现……深度学习影响着我们的生活和决策。在这一文章中,将尽可能简单易懂地解释这些概念:深度学习,人工神经网络,卷积神经网络,梯度下降等。
什么是深度学习?
简单来说,它就是从例子中学习。
从非常基础的层面上说,深度学习是一种机器学习技术,它教计算机通过层过滤输入(图像,文本或声音形式的观察),以学习如何预测和分类信息。
深度学习的灵感来自人类大脑过滤信息的方式。
本质上,深度学习是机器学习系列的一部分,它基于学习数据表征,而不是特定于任务的算法。深度学习实际上与认知神经科学家在90年代早期提出的关于大脑发育的一系列理论密切相关。
就像在大脑中,或者更确切地说,在90年代由研究人员提出的关于人类新皮层发展的理论和模型中,神经网络使用分层过滤器的层次结构,每个层从前一层学习并且然后将其输出,传递给下一层。
深度学习试图模拟新皮层中神经元层的活动。

人类大脑中,大约有1000亿个神经元,每个神经元与大约10万个神经元相连。从本质上说,这就是我们想要创造的,在某种程度上,这对机器来说是可行的。
深度学习的目的是模仿人类大脑的工作方式。这在神经元,轴突,树突等方面意味着什么?嗯,神经元有胞体,树突和轴突。来自一个神经元的信号沿着轴突传播并转移到下一个神经元的树突。传递信号的那个连接被称为突触。
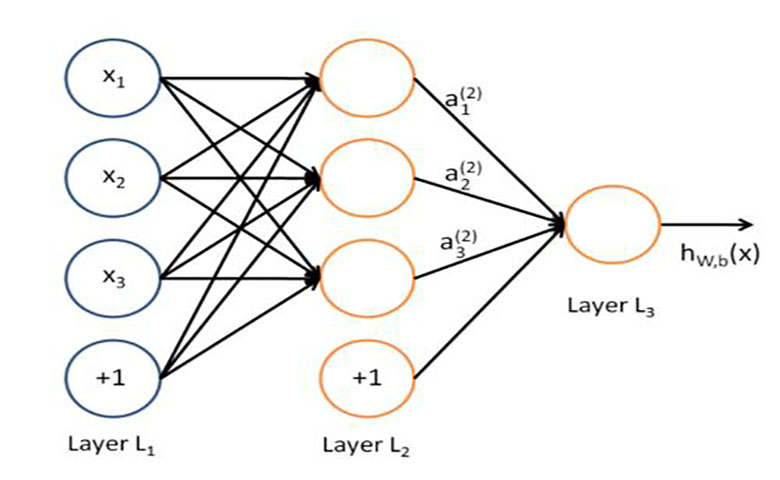
神经元本身是没用的,但是当拥有很多神经元时,它们会共同创造一些“魔法”。这就是深度学习算法背后的想法!你可以从观察中获得输入,将输入放入一个创建输出的图层,该输出又成为下一个图层的输入,依此类推。这种情况反复发生,直到最终输出信号。
因此神经元(或节点)获得信号或信号(输入值),其通过神经元,并传递输出信号。将输入层视为你的感官:看到的东西,气味,感觉等。这些是单次观察的自变量。此信息分为数字和计算机可以使用的二进制数据位(你需要对这些变量进行标准化或规范化,以使它们处于相同的范围内)。
输出值可以是怎样的?它可以是连续的(例如,价格),二进制的(是或否)或分类(猫,狗,驼鹿,刺猬,树懒等)。如果它是分类的,你想要记住你的输出值不仅仅是一个变量,而是几个输出变量。
另外,请记住,输出值始终与输入值中的相同单个观察值相关。例如,如果你的输入值是观察一个人的年龄,工资和车辆,那么输出值也会与同一个人的同一观察结果相关。
那么突触呢?每个突触都获得分配的权重,这对人工神经网络(ANN)至关重要。权重是人工神经网络学习的方式。通过调整权重,ANN决定信号传递的程度。当训练网络时,你将决定如何调整权重。
神经元内部会发生什么?首先,将它得到的所有值相加(计算加权和)。接下来,它应用激活函数,该函数是作用于该特定神经元的函数。由此,神经元理解它是否需要传递信号。
这个过程重复了数千到数十万次!
我们创建了一个人工神经网络,其中有输入值(我们已经知道的和我们想要预测的内容)和输出值(我们的预测)的节点,在这些节点之间,有一个(或多个)信息传播的隐藏层,在它到达输出前传播。这类似于你通过眼睛看到的信息被过滤后理解,而不是直接进入大脑。
深度学习模型可以是有监督的,半监督的和无监督的。
有监督的学习
你对心理学感兴趣吗?这本质上是概念学习,基于每个对象/想法/事件都具有公共特性的信念,你了解了什么是概念(例如对象、想法、事件等)。
这里的思想是,可以向你展示一组带有标记的示例对象,并学习根据你已经看到的内容对对象进行分类。你简化了已经学过的东西,把它压缩成一个例子的形式,然后你把这个简化的版本应用到以后的例子中。我们称之为从例子中学习。
简而言之,有监督的机器学习是学习一个函数的任务,该函数基于示例输入-输出对,将输入映射到输出。它适用于由训练样例组成的标记训练数据。每个示例都是一对由输入对象(通常是向量)和你想要的输出值(也称为监控信号)组成的对。
你的算法监督训练数据并生成推断函数,该函数可用于映射新示例。理想情况下,该算法将允许你对以前从未见过的示例进行分类。
基本上,它会查看带有标记的东西,并使用它从标记中学到的东西来预测其他东西的标签。
分类任务往往取决于监督学习。这些任务可能包括:
- 检测图像中的面部,身份和面部表情
- 识别图像中的物体,如停车标志,行人和车道标记
- 识别垃圾邮件
- 识别视频中的手势
- 检测语音并识别录音中的情绪
- 识别发言人
- 语音转文本
半监督学习
这个更像是你从父母明确告诉你(有标签的信息)与你自己学到的没有标记的东西相结合。半监督学习与监督学习的作用相同,但它能够利用有标记和未标记的数据进行训练。
在半监督学习中,你经常会查看大量未标记的数据和一些标记数据。有许多研究人员发现,这个过程可以提供比无监督学习更高的准确性,而无需标记数据花费的时间和成本。有时标记数据需要熟练的人来做转录音频文件或分析3D图像,这可能会使创建完全标记的数据集非常不可行,尤其是使用大量数据集的深度学习任务。
半监督学习可以被称为转导(推断给定数据的正确标签)或归纳(推断从X到Y的正确映射)。
为此,深度学习算法必须至少做出以下假设之一:
- 彼此接近的点可能共享标记(连续性假设)
- 形成集群的数据和聚集在一起的点可能共享一个标记(集群假设)
- 数据位于比输入空间更低的流形维度上(流形假设)
无监督学习(又名Hebbian学习)
无监督学习涉及学习数据集中元素之间的关系,并在没有标记帮助的情况下对数据进行分类。这可以采用许多算法形式,但它们都具有通过搜索隐藏的结构,特征和模式来模拟人类逻辑以分析新数据的相同目标。这些算法可以包括聚类(Clustering),异常检测,神经网络等。
聚类本质上是检测数据集内的相似性或异常,并且是无监督学习任务的一个很好的例子。通过比较文档,图像或声音的相似性和异常,聚类可以产生高度准确的搜索结果。它能够准确地检测异常和异常行为,对于安全和欺诈检测等应用非常有优势。
回到深度学习
深度学习架构已应用于社交网络过滤,图像识别,金融欺诈检测,语音识别,计算机视觉,医学图像处理,自然语言处理,视觉艺术处理,药物发现和设计,毒理学,生物信息学,客户关系管理,以及许多其他领域和概念。深度学习模型无处不在!
当然,还存在许多深度学习技术,如卷积神经网络,递归神经网络等。
深度学习和人工神经网络
现代深度学习架构大多数基于人工神经网络(ANN),并使用多层非线性处理单元进行特征提取和转换。每个连续层使用前一层的输出作为其输入。他们学到的东西构成了一个概念层次结构,每个层次都学会将其输入数据转换为抽象和复合的表征。
这意味着对于图像,例如,输入可能是像素矩阵,而第一层可能编码边框并组成像素,然后下一层可能排列边,再下一层可能编码鼻子和眼睛,然后可能会识别图像包含人脸……虽然你可能需要进行一些微调,但是深度学习过程会自行学习将哪些特性放置在哪个级别。
深度学习中的“深层”只是指数据转换的层数(它们具有实质的CAP,即从输入到输出的转换链)。对于前馈神经网络,CAP的深度是网络的深度和隐藏层的数量加1(输出层)。对于递归神经网络,一个信号可能会在一个层中传播不止一次,所以上限深度可能是无限的。大多数研究人员认为深度学习CAP depth >2。
卷积神经网络
卷积神经网络(CNN)是最流行的神经网络类型之一。CNN使用输入卷积来学习输入数据的特性,并使用2D卷积层,这意味着这种类型的网络非常适合处理2D图像。
CNN通过从图像中提取特征来工作,这意味着无需手动特征提取。这些特征没有经过训练,
当网络训练一组图像时,它们重新学习,这使得深度学习模型对于计算机视觉任务非常准确。CNN通过数十或数百个隐藏层进行特征检测学习,每一层都增加了学习特征的复杂性。
循环神经网络
卷积神经网络通常用于处理图像,而循环神经网络(RNN)用于处理语言。RNN不只是将信息从一个层过滤到下一个层,它们具有内置的反馈回路,其中一层的输出可能被反馈到它之前的层中。这实际上为网络提供了一种记忆。
生成对抗性网络
在生成对抗性网络(GAN)中,两个神经网络互相竞争。生成器网络试图创建令人信服的虚假数据,而鉴别器试图分辨虚假数据和真实数据之间的差异。
在每个训练周期中,生成器在创建假数据方面做得更好,鉴别器在识别假数据方面做得更好。通过在训练中让两者相互竞争,两种网络都得到了改善。
深度学习的未来
深度学习的未来充满了潜力。关于神经网络最显著的是它能够处理大量不同的数据。现在,我们生活在一个先进的智能传感器时代,这一点变得越来越重要,每时每秒都会收集到大量数据。
目前,我们每天都会生成庞大的数据。虽然传统计算机难以从如此多的数据中得出结论,但随着数据量的增加,深度学习实际上变得更加高效。神经网络能够在大量的非结构化数据中发现潜在的结构,例如原始媒体,它包含了世界上大多数数据。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消