











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






45个问题测出你的深度学习基本功!
2019年01月21日 由 荟荟 发表
304084
0
迟至2009年,深度学习还是一片有待拓荒的处女地,只有极少数人发现其中蕴藏的巨大潜力。而如今,深度学习已经广泛用于解决那些,曾经被认为不可能的任务。语音识别,图像识别,数据集里找模式,照片当中寻分类。文能生成字符串,武可自动开汽车。所以有必要熟悉一些深度学习的基础概念。本文将呈现45道关于深度学习的小测试,快来检测下你的基本功吧!
1.神经网络模型(Neural Network)因受人脑的启发而得名。
神经网络由许多神经元(Neuron)组成,每个神经元接受一个输入,处理它并给出一个输出。这里是一个真实的神经元的图解表示。下列关于神经元的陈述中哪一个是正确的?
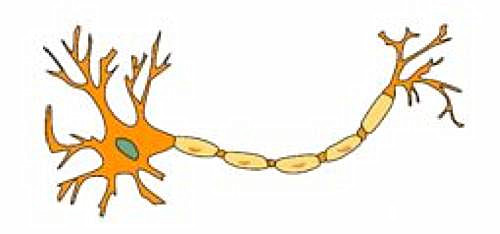 A.一个神经元只有一个输入和一个输出
A.一个神经元只有一个输入和一个输出
B.一个神经元有多个输入和一个输出
C.一个神经元有一个输入和多个输出
D.一个神经元有多个输入和多个输出
E,上述都正确
答案:(E) 一个神经元可以有一个或多个输入,和一个或多个输出。
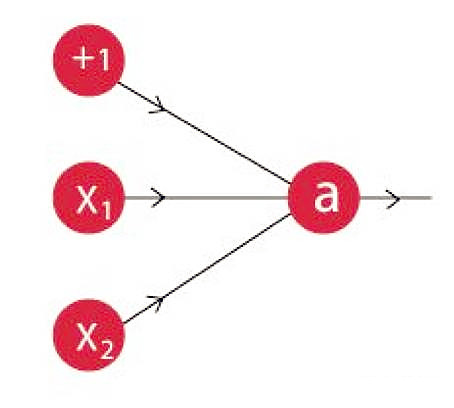
2.下图是一个神经元的数学表达
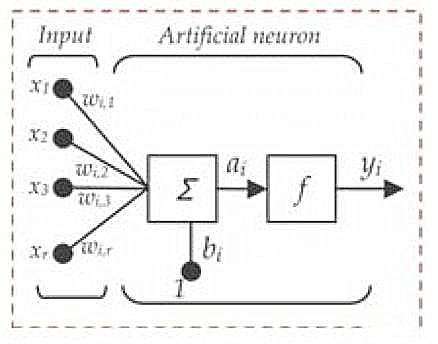
神经元的组成部分表示为:
- x1, x2,…, xN:表示神经元的输入。可以是输入层的实际观测值,也可以是某一个隐层(Hidden Layer)的中间值
- w1, w2,…,wN:表示每一个输入的权重
- bi:表示偏差单元(bias unit)。作为常数项加到激活函数的输入当中,和截距(Intercept)项相似
- a:代表神经元的激励(Activation),可以表示为
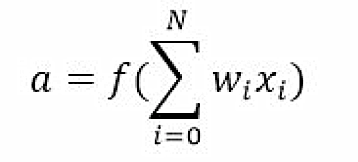
- y:神经元输出
考虑上述标注,线性等式(y = mx + c)可以被认为是属于神经元吗:
A.是
B.否
答案:(A) 一个不包含非线性的神经元可以看作是线性回归函数(Linear Regression Function)。
3.假设在一个神经元上实现和(AND)函数,下表是和函数的表述
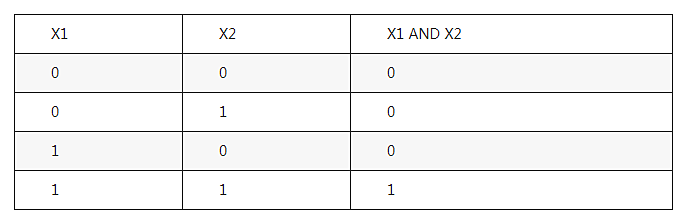
激活函数为:
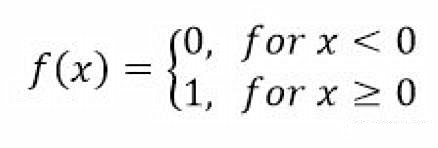
权重(Weights)和偏差(Bias)哪一组是正确的?
A. Bias = -1.5, w1 = 1, w2 = 1
B. Bias = 1.5, w1 = 2, w2 = 2
C. Bias = 1, w1 = 1.5, w2 = 1.5
D. 以上都不正确
答案:(A)
f(-1.5*1 + 1*0 + 1*0) = f(-1.5) = 0
f(-1.5*1 + 1*0 + 1*1) = f(-0.5) = 0
f(-1.5*1 + 1*1 + 1*0) = f(-0.5) = 0
f(-1.5*1 + 1*1+ 1*1) = f(0.5) = 1 带入测试值,A选项正确
4.多个神经元堆叠在一起构成了神经网络,我们举一个例子,用神经网络模拟同或门(XNOR)
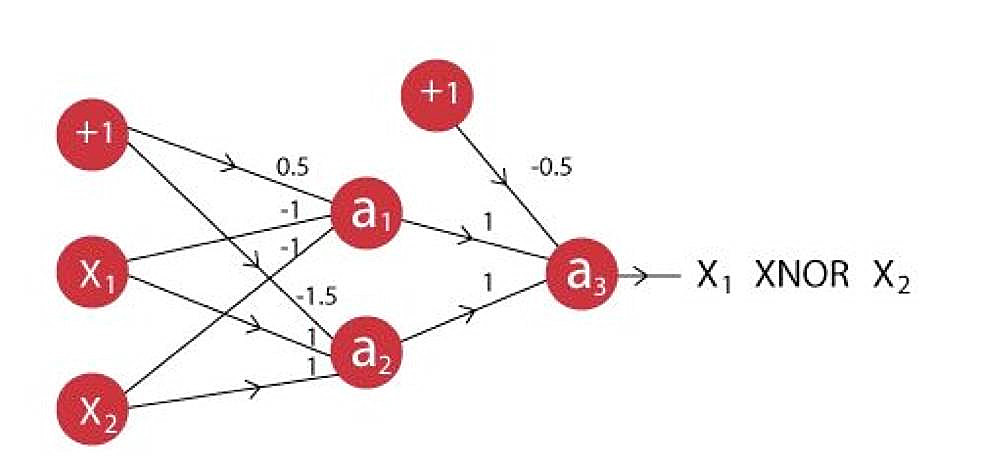
你可以看见最后一个神经元有两个输入。所有神经元的激活函数是:
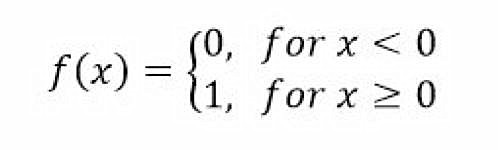
假设X1是0,X2是1,神经网络的输出是什么?
A.0
B.1
答案:(A)
a1输出: f(0.5*1 + -1*0 + -1*1) = f(-0.5) = 0
a2输出: f(-1.5*1 + 1*0 + 1*1) = f(-0.5) = 0
a3输出: f(-0.5*1 + 1*0 + 1*0) = f(-0.5) = 0
5.在一个神经网络里,知道每一个神经元的权重和偏差是最重要的一步。如果以某种方法知道了神经元准确的权重和偏差,你就可以近似任何函数。实现这个最佳的办法是什么?
A.随机赋值,祈祷它们是正确的
B.搜索所有权重和偏差的组合,直到得到最佳值
C.赋予一个初始值,通过检查跟最佳值的差值,然后迭代更新权重
D.以上都不正确
答案:(C) 选项C是对梯度下降的描述。
6.梯度下降算法的正确步骤是什么?
1.计算预测值和真实值之间的误差
2.迭代跟新,直到找到最佳权重
3.把输入传入网络,得到输出值
4.初始化随机权重和偏差
5.对每一个产生误差的神经元,改变相应的(权重)值以减小误差
A. 1, 2, 3, 4, 5
B. 5, 4, 3, 2, 1
C. 3, 2, 1, 5, 4
D. 4, 3, 1, 5, 2
答案:(D)
7.假设你有输入x,y,z,值分别是-2,5,-4。你有神经元q和f,函数分别为q = x + y,f = q * z。函数的图示如下图:
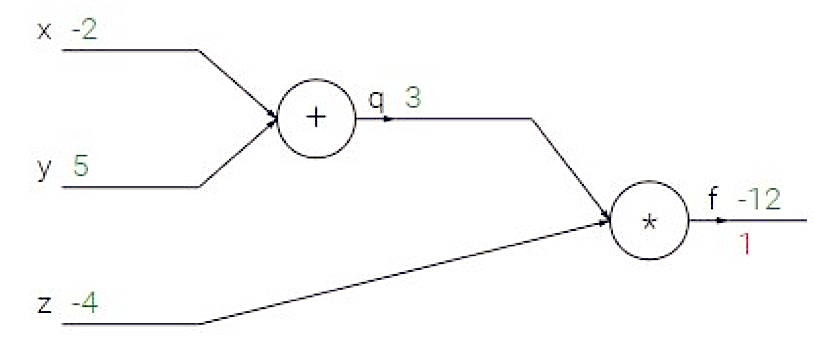
F对x,y和z的梯度分别是?
A. (-3,4,4)
B. (4,4,3)
C. (-4,-4,3)
D. (3,-4,-4)
答案:(C)
8.现在回顾之前的内容。我们学到了:
- 大脑是有很多叫做神经元的东西构成,神经网络是对大脑的粗糙的数学表达。
- 每一个神经元都有输入、处理函数和输出。
- 神经元堆叠起来形成了网络,用作近似任何函数。
- 为了得到最佳的神经网络,我们用梯度下降方法不断更新模型
给定上述关于神经网络的描述,什么情况下神经网络模型被称为深度学习模型?
A.加入更多层,使神经网络的深度增加
B.有维度更高的数据
C.当这是一个图形识别的问题时
D.以上都不正确
答案:(A) 更多层意味着网络更深。没有严格的定义多少层的模型才叫深度模型,目前如果有超过2层的隐层,那么也可以及叫做深度模型。
9.神经网络可以认为是多个简单函数的堆叠。假设我们想重复下图所示的决策边界
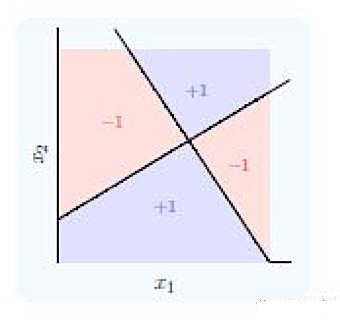
使用两个简单的输入h1和h2
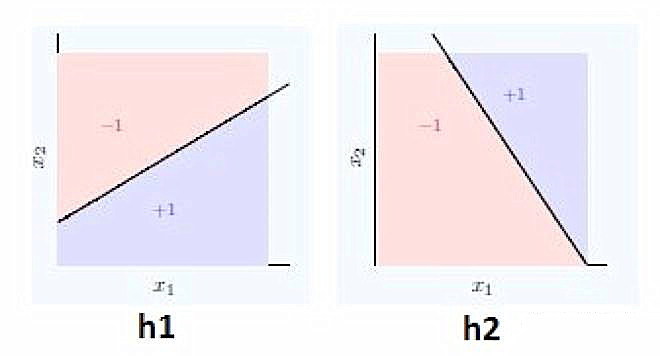
最终的等式是什么?
A. (h1 AND NOT h2) OR (NOT h1 AND h2)
B. (h1 OR[supsystic-gallery id=null position=center] NOT h2) AND (NOT h1 OR h2)
C. (h1 AND h2) OR (h1 OR h2)
D. None of these
答案:(A) 你可以看见,巧妙地合并h1和h2可以很容易地得到复杂的等式。参见这本书的第九章。
10.卷积神经网络可以对一个输入完成不同种类的变换(旋转或缩放),这个表述正确吗?
A.正确
B.错误
答案:(B) 数据预处理(也就是旋转、缩放)步骤在把数据传入神经网络之前是必要的,神经网络自己不能完成这些变换。
答案:(A) Dropout可以认为是一种极端的Bagging,每一个模型都在单独的数据上训练,通过和其他模型对应参数的共享,模型的参数都进行了很强的正则化。参见这里。
12.下列哪哪一项在神经网络中引入了非线性
A.随机梯度下降
B.修正线性单元(ReLU)
C.卷积函数
D.以上都不正确
答案:(B) 修正线性单元是非线性的激活函数。
13.训练神经网络过程中,损失函数在一些时期(Epoch)不再减小
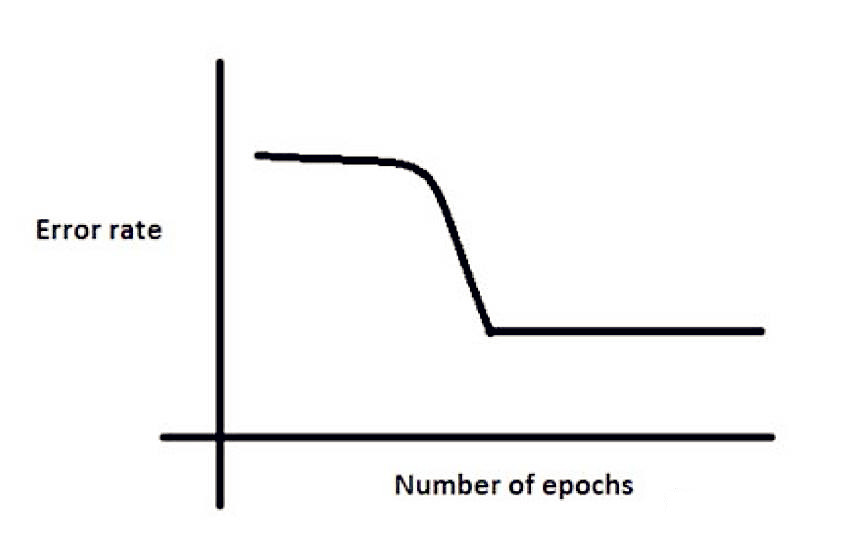
原因可能是:1.学习率(Learning rate)太低 2.正则参数太大 3.卡在了局部最小值。在你看来哪些是可能的原因?
A. 1 and 2
B. 2 and 3
C. 1 and 3
D. 都不是
答案:(D) 以上原因都可能造成这个结果。
14.下列哪项关于模型能力(model capacity)的描述是正确的?(指模型能近似复杂函数的能力)
A.隐层层数增加,模型能力增加
B.Dropout的比例增加,模型能力增加
C.学习率增加,模型能力增加
D.都不正确
答案:(A)
15.如果增加多层感知机(Multilayer Perceptron)的隐层层数,测试集的分类错误会减小。这种陈述正确还是错误?
A.正确
B.错误
答案:(B) 并不总是正确。过拟合可能会导致错误增加。
16.构建一个神经网络,将前一层的输出和它自身作为输入。
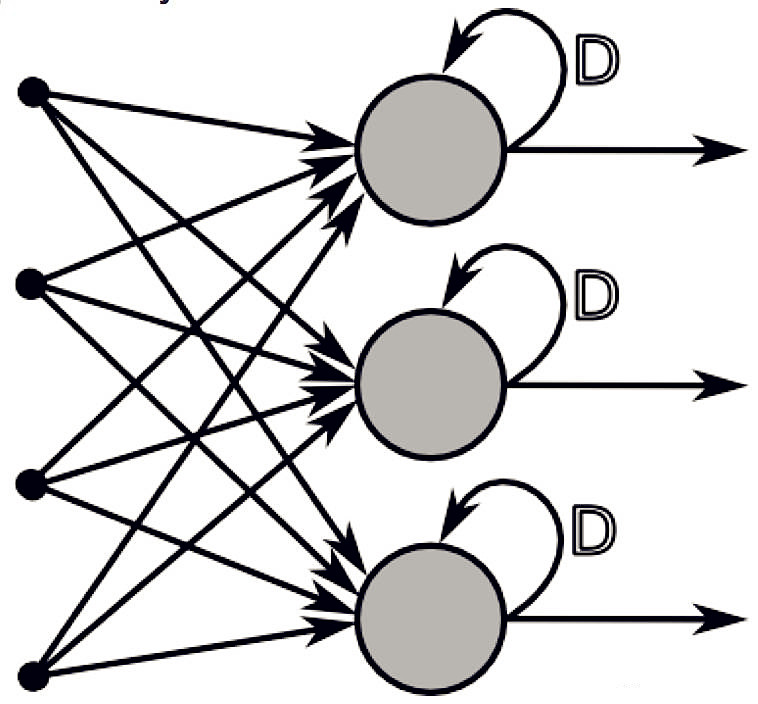
下列哪一种架构有反馈连接?
A.循环神经网络
B.卷积神经网络
C.限制玻尔兹曼机
D.都不是
答案:(A)
17.在感知机中(Perceptron)的任务顺序是什么?
1.初始化随机权重
2.去到数据集的下一批(batch)
3.如果预测值和输出不一致,改变权重
4.对一个输入样本,计算输出值
A. 1, 2, 3, 4
B. 4, 3, 2, 1
C. 3, 1, 2, 4
D. 1, 4, 3, 2
答案:(D) 顺序D是正确的。
18.假设你需要改变参数来最小化代价函数(cost function),可以使用下列哪项技术?
A.穷举搜索
B.随机搜索
C.Bayesian优化
D.以上任意一种
答案:(D) 以上任意种技术都可以用来更新参数。
19.在哪种情况下,一阶梯度下降不一定正确工作(可能会卡住)?
A.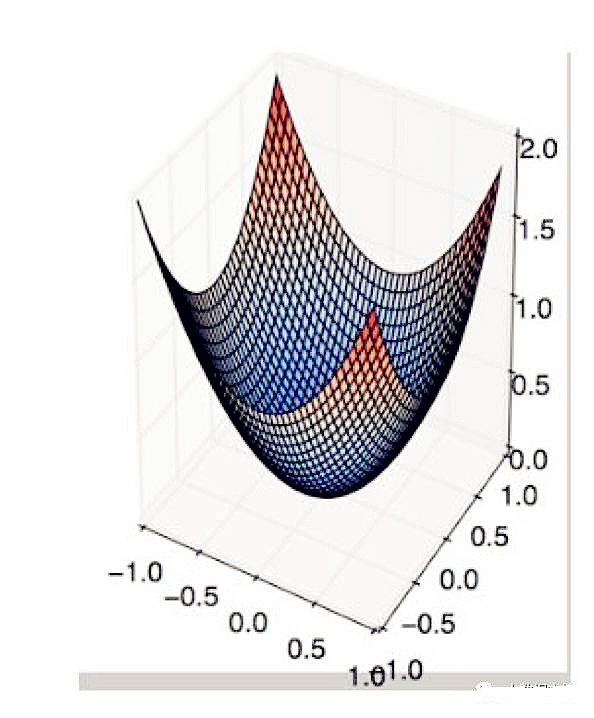 B.
B.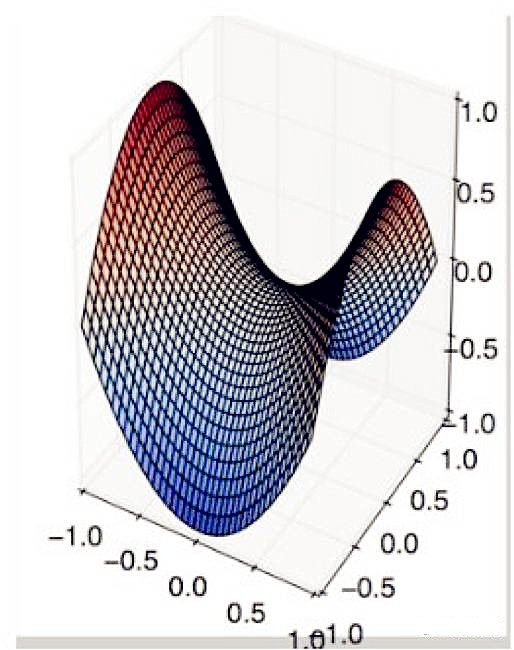
C.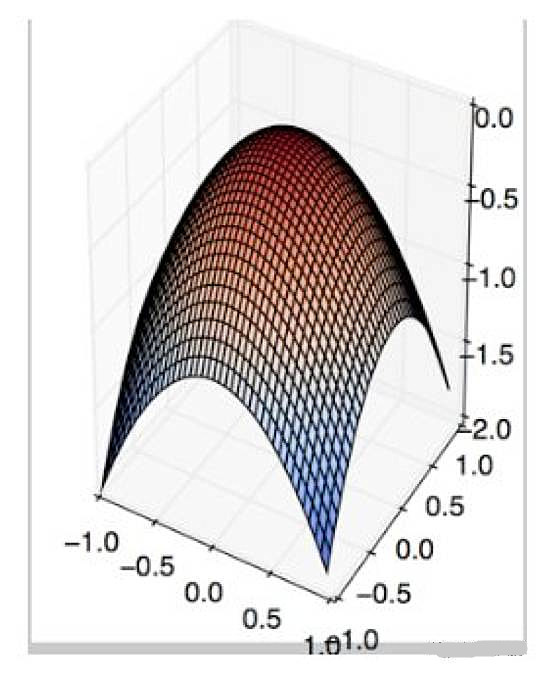
D. 以上都不正确
答案:(B) 这是鞍点(Saddle Point)的梯度下降的经典例子。
20.训练好的三层卷积神经网络的精确度(Accuracy)vs 参数数量(比如特征核的数量)的图示如下。
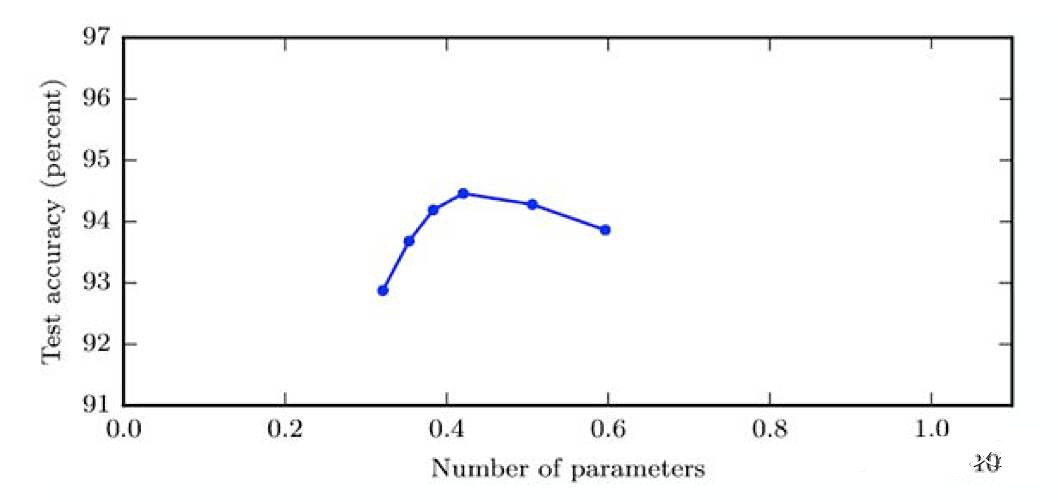
从图中趋势可见,如果增加神经网络的宽度,精确度会增加到一个阈值,然后开始降低。这一现象的可能是什么原因是造成的?
A.即便核数量(number of kernels)增加,只有一部分核被用于预测
B.当核数量增加,神经网络的预测功效(Power)降低
C.当核数量增加,其相关性增加,导致过拟合
D.以上都不正确
答案:(C) 如C选项指出的那样,可能的原因是核之间的相关性。
21.假设我们有一个隐层神经网络,如上所示。隐层在这个网络中用于降维。现在我们并不是采用这个隐层,而是使用例如主成分分析(Principal Component Analysis, PCA)的降维技术。
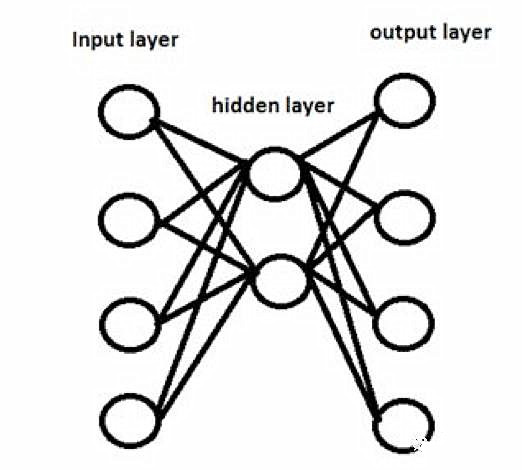
使用降维技术的网络与隐层网络总是有相同的输出吗?
A.是
B.否
答案:(B) 因为PCA用于相关特征而隐层用于有预测能力的特征
22.可以用神经网络对函数(y=1/x)建模吗?
A.是
B.否
答案:(A) 选项A是正确的,因为激活函数可以是互反函数
23.下列哪个神经网络结构会发生权重共享?
A.卷积神经网络
B.循环神经网络
C.全连接神经网络
D.选项A和B
答案:(D)
24.批规范化是有帮助的,因为
A.在将所有的输入传递到下一层之前对其进行归一化(更改)
B.它将返回归一化的权重平均值和标准差
C.它是一种非常有效的反向传播技术
D.这些均不是
答案:(A) 要详细了解批规范化,请参阅此视频。
25.我们不是想要绝对零误差,而是设置一个称为贝叶斯(bayes)误差(我们希望实现的误差)的度量。使用贝叶斯(bayes)误差的原因是什么?
A.输入变量可能不包含有关输出变量的完整信息
B.系统(创建输入-输出映射)可以是随机的
C.有限的训练数据
D.所有
答案:(D) 想在现实中实现准确的预测,是一个神话,所以我们的希望应该放在实现一个“可实现的结果”上。
26.在监督学习任务中,输出层中的神经元的数量应该与类的数量(其中类的数量大于2)匹配。对或错?
A.正确
B.错误
答案:(B) 它取决于输出编码。如果是独热编码(one-hot encoding) 则正确。但是你可以有两个输出囊括四个类,并用二进制值表示出来(00,01,10,11)。
27.在神经网络中,以下哪种技术用于解决过拟合?
A.Dropout
B.正则化
C.批规范化
D.所有
答案:(D) 所有的技术都可以用于处理过拟合。
28.Y = ax^2 + bx + c(二次多项式)
这个方程可以用具有线性阈值的单个隐层的神经网络表示吗?
A.是
B.否
答案:(B) 答案为否。因为简单来说,有一个线性阈值限制神经网络就会使它成为一个相应的线性变换函数。
29.神经网络中的死神经元(dead unit)是什么?
A.在训练任何其它相邻单元时,不会更新的单元
B.没有完全响应任何训练模式的单元
C.产生最大平方误差的单元
D.以上均不符合
答案:(A)
30.以下哪项是对早期停止的最佳描述?
A.训练网络直到达到误差函数中的局部最小值
B.在每次训练期后在测试数据集上模拟网络,当泛化误差开始增加时停止训练
C.在中心化权重更新中添加一个梯度下降加速算子,以便训练更快地收敛
D.更快的方法是反向传播,如‘Quickprop’算法
答案:(B)
31.如果我们使用的学习率太大该怎么办?
A.网络将收敛
B.网络将无法收敛
C.不确定
答案:(B) 选项B正确,因为错误率会变得不稳定并且达到非常大的值
32.图1所示的网络用于训练识别字符H和T,如下所示:
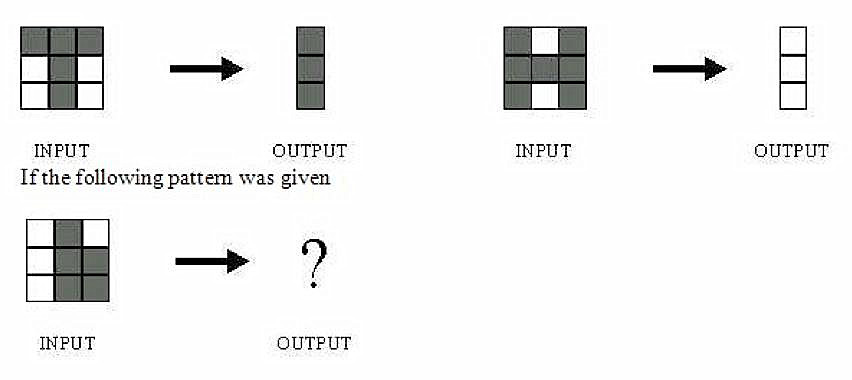
下面哪些是可能的输出?
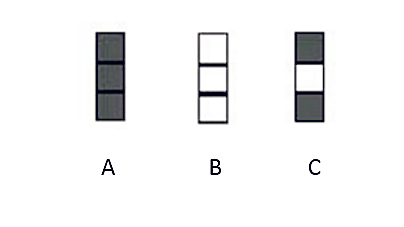
A.A
B.B
C.C
D.可能是A或B,取决于神经网络的权重
答案:(D) 不知道神经网络的权重和偏差是什么,则无法评论它将会给出什么样的输出。
33.假设在ImageNet数据集(对象识别数据集)上训练卷积神经网络。然后给这个训练模型一个完全白色的图像作为输入。这个输入的输出概率对于所有类都是相等的。对或错?
A.正确
B.错误
答案:(B) 将存在一些不为白色像素激活的神经元作为输入,所以类不会相等。
34.当在卷积神经网络中添加池化层(pooling layer)时,变换的不变性保持稳定,这样的理解是否正确?
A.正确
B.错误
答案:(A) 使用池化时会导致出现不变性。
35.当数据太大而不能同时在RAM中处理时,哪种梯度技术更有优势?
A.全批量梯度下降(Full Batch Gradient Descent )
B.随机梯度下降(Stochastic Gradient Descent)
答案:(B)
36.该图表示,使用每个训练时期的激活函数,-训练有四个隐藏层的神经网络梯度流。神经网络遭遇了梯度消失问题。
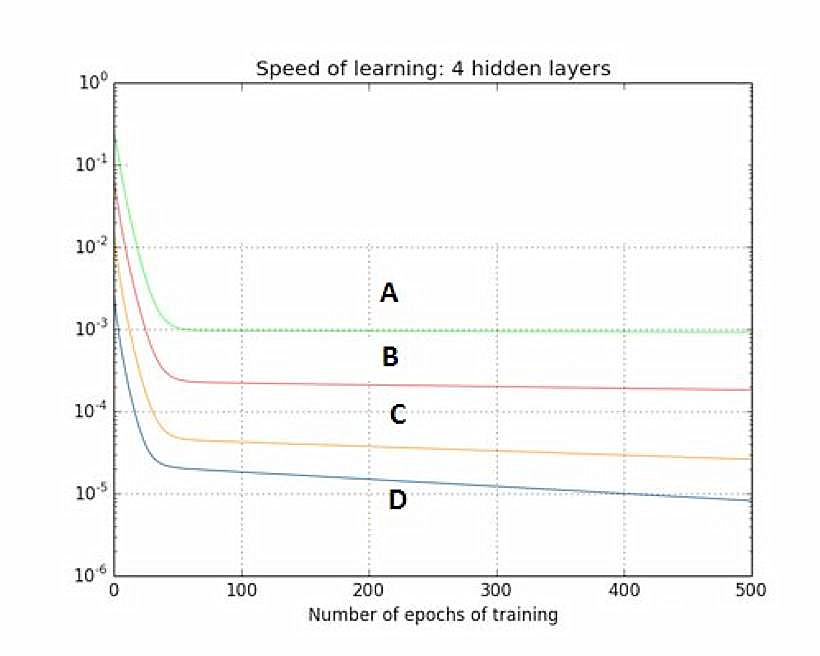
下列哪项正确?
A.隐藏层1对应于D,隐藏层2对应于C,隐藏层3对应于B,隐藏层4对应于A
B.隐藏层1对应于A,隐藏层2对应于B,隐藏层3对应于C,隐藏层4对应于D
答案:(A) 这是对消失梯度描述的问题。由于反向传播算法进入起始层,学习能力降低。
37.对于分类任务,我们不是将神经网络中的随机权重初始化,而是将所有权重设为零。下列哪项是正确的?
A.没有任何问题,神经网络模型将正常训练
B.神经网络模型可以训练,但所有的神经元最终将识别同样的事情
C.神经网络模型不会进行训练,因为没有净梯度变化
D.这些均不会发生
答案:(B)
38.开始时有一个停滞期,这是因为神经网络在进入全局最小值之前陷入局部最小值。
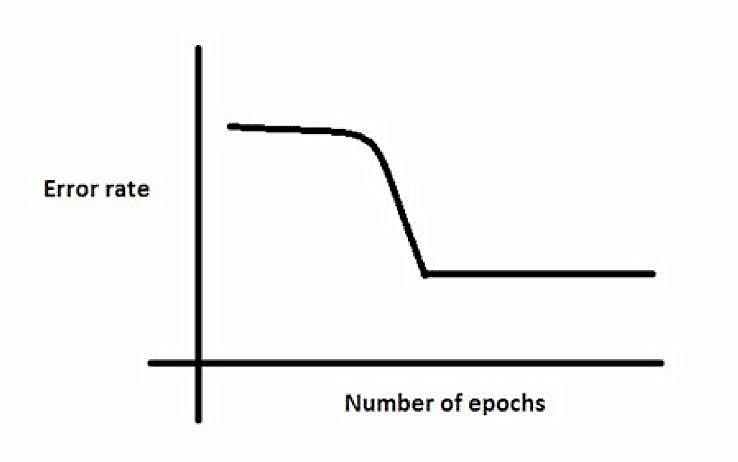
为了避免这种情况,下面的哪个策略有效?
A.增加参数的数量,因为网络不会卡在局部最小值处
B.在开始时把学习率降低10倍,然后使用梯度下降加速算子(momentum)
C.抖动学习速率,即改变几个时期的学习速率
D.以上均不是
答案:(C) 选项C可以将陷于局部最小值的神经网络提取出来。
39.对于图像识别问题(比如识别照片中的猫),神经网络模型结构更适合解决哪类问题?
A.多层感知器
B.卷积神经网络
C.循环神经网络
D.感知器
答案:(B) 卷积神经网络将更好地适用于图像相关问题,因为考虑到图像附近位置变化的固有性质。
40.假设在训练时,你遇到这个问题。在几次迭代后,错误突然增加。
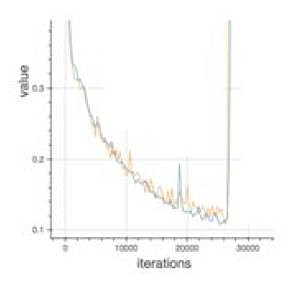
您确定数据一定有问题。您将数据描绘出来,找到了原始数据有点偏离,这可能是导致出现问题的地方。

你将如何应对这个挑战?
A.归一化
B.应用PCA然后归一化
C.对数据进行对数变换
D.以上这些都不符合
答案:(B) 首先您将相关的数据去掉,然后将其置零。
41.以下哪项是神经网络的决策边界?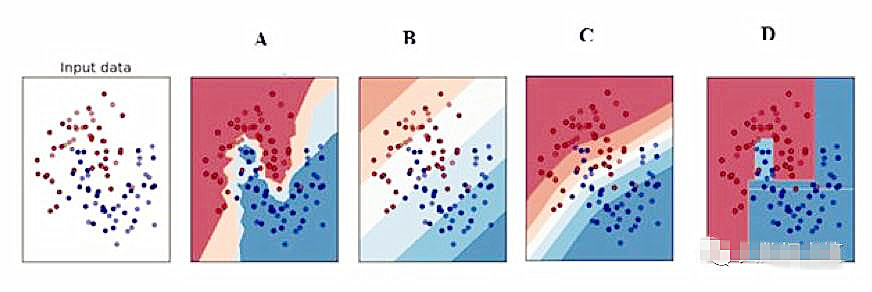
A.B
B.A
C.D
D.C
E.以上所有
答案:(E) 神经网络被称为通用函数拟合器(universal function approximator),所以它理论上可以表示任何决策边界。
42.在下面的图中,我们观察到错误有许多“起伏”,我们该为此而担心吗?
A.是,因为这意味着神经网络的学习速率有问题。
B.否,只要训练和验证错误累积减少,我们就不必担心。
答案:(B) 选项B是正确的,为了减少这些“起伏”,可以尝试增加批尺寸(batch size)
43.什么是影响神经网络的深度选择的因素?
1.神经网络的类型,例如:多层感知机(Multi-Layer Perceptrons, MLP),卷积神经网络(Convolutional Neural Networks, CNN)
2.输入数据
3.计算能力,即硬件和软件能力
4.学习率
5.输出函数映射
A. 1, 2, 4, 5
B. 2, 3, 4, 5
C. 1, 3, 4, 5
D. 以上均是
答案:(D) 所有上述因素对于选择神经网络模型的深度都是重要的。
44.考虑这种情况:您尝试解决的问题有少量的数据。幸运的是,您有一个之前训练过的针对类似问题的神经网络模型。您将使用以下哪种方法来使用该预先训练的模型?
A.对于新的数据集重新训练模型
B.在每一层评估模型如何执行,只选择其中的一些
C.只微调最后几层
D.冻结除最后一层之外的所有层,重新训练最后一层
答案:(D) 如果数据集大部分相似,最好的方法是只训练最后一层,因为前面的所有层都用于特征提取。
45.增大卷积核的大小必然会提高卷积神经网络的性能。
A.正确
B.错误
答案:(B) 增加核函数的大小不一定会提高性能。这个问题在很大程度上取决于数据集。
1.神经网络模型(Neural Network)因受人脑的启发而得名。
神经网络由许多神经元(Neuron)组成,每个神经元接受一个输入,处理它并给出一个输出。这里是一个真实的神经元的图解表示。下列关于神经元的陈述中哪一个是正确的?
A.一个神经元只有一个输入和一个输出B.一个神经元有多个输入和一个输出
C.一个神经元有一个输入和多个输出
D.一个神经元有多个输入和多个输出
E,上述都正确
答案:(E) 一个神经元可以有一个或多个输入,和一个或多个输出。
2.下图是一个神经元的数学表达
神经元的组成部分表示为:
- x1, x2,…, xN:表示神经元的输入。可以是输入层的实际观测值,也可以是某一个隐层(Hidden Layer)的中间值
- w1, w2,…,wN:表示每一个输入的权重
- bi:表示偏差单元(bias unit)。作为常数项加到激活函数的输入当中,和截距(Intercept)项相似
- a:代表神经元的激励(Activation),可以表示为
- y:神经元输出
考虑上述标注,线性等式(y = mx + c)可以被认为是属于神经元吗:
A.是
B.否
答案:(A) 一个不包含非线性的神经元可以看作是线性回归函数(Linear Regression Function)。
3.假设在一个神经元上实现和(AND)函数,下表是和函数的表述
激活函数为:
权重(Weights)和偏差(Bias)哪一组是正确的?
A. Bias = -1.5, w1 = 1, w2 = 1
B. Bias = 1.5, w1 = 2, w2 = 2
C. Bias = 1, w1 = 1.5, w2 = 1.5
D. 以上都不正确
答案:(A)
f(-1.5*1 + 1*0 + 1*0) = f(-1.5) = 0
f(-1.5*1 + 1*0 + 1*1) = f(-0.5) = 0
f(-1.5*1 + 1*1 + 1*0) = f(-0.5) = 0
f(-1.5*1 + 1*1+ 1*1) = f(0.5) = 1 带入测试值,A选项正确
4.多个神经元堆叠在一起构成了神经网络,我们举一个例子,用神经网络模拟同或门(XNOR)
你可以看见最后一个神经元有两个输入。所有神经元的激活函数是:
假设X1是0,X2是1,神经网络的输出是什么?
A.0
B.1
答案:(A)
a1输出: f(0.5*1 + -1*0 + -1*1) = f(-0.5) = 0
a2输出: f(-1.5*1 + 1*0 + 1*1) = f(-0.5) = 0
a3输出: f(-0.5*1 + 1*0 + 1*0) = f(-0.5) = 0
5.在一个神经网络里,知道每一个神经元的权重和偏差是最重要的一步。如果以某种方法知道了神经元准确的权重和偏差,你就可以近似任何函数。实现这个最佳的办法是什么?
A.随机赋值,祈祷它们是正确的
B.搜索所有权重和偏差的组合,直到得到最佳值
C.赋予一个初始值,通过检查跟最佳值的差值,然后迭代更新权重
D.以上都不正确
答案:(C) 选项C是对梯度下降的描述。
6.梯度下降算法的正确步骤是什么?
1.计算预测值和真实值之间的误差
2.迭代跟新,直到找到最佳权重
3.把输入传入网络,得到输出值
4.初始化随机权重和偏差
5.对每一个产生误差的神经元,改变相应的(权重)值以减小误差
A. 1, 2, 3, 4, 5
B. 5, 4, 3, 2, 1
C. 3, 2, 1, 5, 4
D. 4, 3, 1, 5, 2
答案:(D)
7.假设你有输入x,y,z,值分别是-2,5,-4。你有神经元q和f,函数分别为q = x + y,f = q * z。函数的图示如下图:
F对x,y和z的梯度分别是?
A. (-3,4,4)
B. (4,4,3)
C. (-4,-4,3)
D. (3,-4,-4)
答案:(C)
8.现在回顾之前的内容。我们学到了:
- 大脑是有很多叫做神经元的东西构成,神经网络是对大脑的粗糙的数学表达。
- 每一个神经元都有输入、处理函数和输出。
- 神经元堆叠起来形成了网络,用作近似任何函数。
- 为了得到最佳的神经网络,我们用梯度下降方法不断更新模型
给定上述关于神经网络的描述,什么情况下神经网络模型被称为深度学习模型?
A.加入更多层,使神经网络的深度增加
B.有维度更高的数据
C.当这是一个图形识别的问题时
D.以上都不正确
答案:(A) 更多层意味着网络更深。没有严格的定义多少层的模型才叫深度模型,目前如果有超过2层的隐层,那么也可以及叫做深度模型。
9.神经网络可以认为是多个简单函数的堆叠。假设我们想重复下图所示的决策边界
使用两个简单的输入h1和h2
最终的等式是什么?
A. (h1 AND NOT h2) OR (NOT h1 AND h2)
B. (h1 OR[supsystic-gallery id=null position=center] NOT h2) AND (NOT h1 OR h2)
C. (h1 AND h2) OR (h1 OR h2)
D. None of these
答案:(A) 你可以看见,巧妙地合并h1和h2可以很容易地得到复杂的等式。参见这本书的第九章。
10.卷积神经网络可以对一个输入完成不同种类的变换(旋转或缩放),这个表述正确吗?
A.正确
B.错误
答案:(B) 数据预处理(也就是旋转、缩放)步骤在把数据传入神经网络之前是必要的,神经网络自己不能完成这些变换。
11.下列哪一种操作实现了和神经网络中Dropout类似的效果?
A. Bagging
B. Boosting
C. 堆叠(Stacking)
答案:(A) Dropout可以认为是一种极端的Bagging,每一个模型都在单独的数据上训练,通过和其他模型对应参数的共享,模型的参数都进行了很强的正则化。参见这里。
12.下列哪哪一项在神经网络中引入了非线性
A.随机梯度下降
B.修正线性单元(ReLU)
C.卷积函数
D.以上都不正确
答案:(B) 修正线性单元是非线性的激活函数。
13.训练神经网络过程中,损失函数在一些时期(Epoch)不再减小
原因可能是:1.学习率(Learning rate)太低 2.正则参数太大 3.卡在了局部最小值。在你看来哪些是可能的原因?
A. 1 and 2
B. 2 and 3
C. 1 and 3
D. 都不是
答案:(D) 以上原因都可能造成这个结果。
14.下列哪项关于模型能力(model capacity)的描述是正确的?(指模型能近似复杂函数的能力)
A.隐层层数增加,模型能力增加
B.Dropout的比例增加,模型能力增加
C.学习率增加,模型能力增加
D.都不正确
答案:(A)
15.如果增加多层感知机(Multilayer Perceptron)的隐层层数,测试集的分类错误会减小。这种陈述正确还是错误?
A.正确
B.错误
答案:(B) 并不总是正确。过拟合可能会导致错误增加。
16.构建一个神经网络,将前一层的输出和它自身作为输入。
下列哪一种架构有反馈连接?
A.循环神经网络
B.卷积神经网络
C.限制玻尔兹曼机
D.都不是
答案:(A)
17.在感知机中(Perceptron)的任务顺序是什么?
1.初始化随机权重
2.去到数据集的下一批(batch)
3.如果预测值和输出不一致,改变权重
4.对一个输入样本,计算输出值
A. 1, 2, 3, 4
B. 4, 3, 2, 1
C. 3, 1, 2, 4
D. 1, 4, 3, 2
答案:(D) 顺序D是正确的。
18.假设你需要改变参数来最小化代价函数(cost function),可以使用下列哪项技术?
A.穷举搜索
B.随机搜索
C.Bayesian优化
D.以上任意一种
答案:(D) 以上任意种技术都可以用来更新参数。
19.在哪种情况下,一阶梯度下降不一定正确工作(可能会卡住)?
A.
B.C.
D. 以上都不正确
答案:(B) 这是鞍点(Saddle Point)的梯度下降的经典例子。
20.训练好的三层卷积神经网络的精确度(Accuracy)vs 参数数量(比如特征核的数量)的图示如下。
从图中趋势可见,如果增加神经网络的宽度,精确度会增加到一个阈值,然后开始降低。这一现象的可能是什么原因是造成的?
A.即便核数量(number of kernels)增加,只有一部分核被用于预测
B.当核数量增加,神经网络的预测功效(Power)降低
C.当核数量增加,其相关性增加,导致过拟合
D.以上都不正确
答案:(C) 如C选项指出的那样,可能的原因是核之间的相关性。
21.假设我们有一个隐层神经网络,如上所示。隐层在这个网络中用于降维。现在我们并不是采用这个隐层,而是使用例如主成分分析(Principal Component Analysis, PCA)的降维技术。
使用降维技术的网络与隐层网络总是有相同的输出吗?
A.是
B.否
答案:(B) 因为PCA用于相关特征而隐层用于有预测能力的特征
22.可以用神经网络对函数(y=1/x)建模吗?
A.是
B.否
答案:(A) 选项A是正确的,因为激活函数可以是互反函数
23.下列哪个神经网络结构会发生权重共享?
A.卷积神经网络
B.循环神经网络
C.全连接神经网络
D.选项A和B
答案:(D)
24.批规范化是有帮助的,因为
A.在将所有的输入传递到下一层之前对其进行归一化(更改)
B.它将返回归一化的权重平均值和标准差
C.它是一种非常有效的反向传播技术
D.这些均不是
答案:(A) 要详细了解批规范化,请参阅此视频。
25.我们不是想要绝对零误差,而是设置一个称为贝叶斯(bayes)误差(我们希望实现的误差)的度量。使用贝叶斯(bayes)误差的原因是什么?
A.输入变量可能不包含有关输出变量的完整信息
B.系统(创建输入-输出映射)可以是随机的
C.有限的训练数据
D.所有
答案:(D) 想在现实中实现准确的预测,是一个神话,所以我们的希望应该放在实现一个“可实现的结果”上。
26.在监督学习任务中,输出层中的神经元的数量应该与类的数量(其中类的数量大于2)匹配。对或错?
A.正确
B.错误
答案:(B) 它取决于输出编码。如果是独热编码(one-hot encoding) 则正确。但是你可以有两个输出囊括四个类,并用二进制值表示出来(00,01,10,11)。
27.在神经网络中,以下哪种技术用于解决过拟合?
A.Dropout
B.正则化
C.批规范化
D.所有
答案:(D) 所有的技术都可以用于处理过拟合。
28.Y = ax^2 + bx + c(二次多项式)
这个方程可以用具有线性阈值的单个隐层的神经网络表示吗?
A.是
B.否
答案:(B) 答案为否。因为简单来说,有一个线性阈值限制神经网络就会使它成为一个相应的线性变换函数。
29.神经网络中的死神经元(dead unit)是什么?
A.在训练任何其它相邻单元时,不会更新的单元
B.没有完全响应任何训练模式的单元
C.产生最大平方误差的单元
D.以上均不符合
答案:(A)
30.以下哪项是对早期停止的最佳描述?
A.训练网络直到达到误差函数中的局部最小值
B.在每次训练期后在测试数据集上模拟网络,当泛化误差开始增加时停止训练
C.在中心化权重更新中添加一个梯度下降加速算子,以便训练更快地收敛
D.更快的方法是反向传播,如‘Quickprop’算法
答案:(B)
31.如果我们使用的学习率太大该怎么办?
A.网络将收敛
B.网络将无法收敛
C.不确定
答案:(B) 选项B正确,因为错误率会变得不稳定并且达到非常大的值
32.图1所示的网络用于训练识别字符H和T,如下所示:
下面哪些是可能的输出?
A.A
B.B
C.C
D.可能是A或B,取决于神经网络的权重
答案:(D) 不知道神经网络的权重和偏差是什么,则无法评论它将会给出什么样的输出。
33.假设在ImageNet数据集(对象识别数据集)上训练卷积神经网络。然后给这个训练模型一个完全白色的图像作为输入。这个输入的输出概率对于所有类都是相等的。对或错?
A.正确
B.错误
答案:(B) 将存在一些不为白色像素激活的神经元作为输入,所以类不会相等。
34.当在卷积神经网络中添加池化层(pooling layer)时,变换的不变性保持稳定,这样的理解是否正确?
A.正确
B.错误
答案:(A) 使用池化时会导致出现不变性。
35.当数据太大而不能同时在RAM中处理时,哪种梯度技术更有优势?
A.全批量梯度下降(Full Batch Gradient Descent )
B.随机梯度下降(Stochastic Gradient Descent)
答案:(B)
36.该图表示,使用每个训练时期的激活函数,-训练有四个隐藏层的神经网络梯度流。神经网络遭遇了梯度消失问题。
下列哪项正确?
A.隐藏层1对应于D,隐藏层2对应于C,隐藏层3对应于B,隐藏层4对应于A
B.隐藏层1对应于A,隐藏层2对应于B,隐藏层3对应于C,隐藏层4对应于D
答案:(A) 这是对消失梯度描述的问题。由于反向传播算法进入起始层,学习能力降低。
37.对于分类任务,我们不是将神经网络中的随机权重初始化,而是将所有权重设为零。下列哪项是正确的?
A.没有任何问题,神经网络模型将正常训练
B.神经网络模型可以训练,但所有的神经元最终将识别同样的事情
C.神经网络模型不会进行训练,因为没有净梯度变化
D.这些均不会发生
答案:(B)
38.开始时有一个停滞期,这是因为神经网络在进入全局最小值之前陷入局部最小值。
为了避免这种情况,下面的哪个策略有效?
A.增加参数的数量,因为网络不会卡在局部最小值处
B.在开始时把学习率降低10倍,然后使用梯度下降加速算子(momentum)
C.抖动学习速率,即改变几个时期的学习速率
D.以上均不是
答案:(C) 选项C可以将陷于局部最小值的神经网络提取出来。
39.对于图像识别问题(比如识别照片中的猫),神经网络模型结构更适合解决哪类问题?
A.多层感知器
B.卷积神经网络
C.循环神经网络
D.感知器
答案:(B) 卷积神经网络将更好地适用于图像相关问题,因为考虑到图像附近位置变化的固有性质。
40.假设在训练时,你遇到这个问题。在几次迭代后,错误突然增加。
您确定数据一定有问题。您将数据描绘出来,找到了原始数据有点偏离,这可能是导致出现问题的地方。
你将如何应对这个挑战?
A.归一化
B.应用PCA然后归一化
C.对数据进行对数变换
D.以上这些都不符合
答案:(B) 首先您将相关的数据去掉,然后将其置零。
41.以下哪项是神经网络的决策边界?
A.B
B.A
C.D
D.C
E.以上所有
答案:(E) 神经网络被称为通用函数拟合器(universal function approximator),所以它理论上可以表示任何决策边界。
42.在下面的图中,我们观察到错误有许多“起伏”,我们该为此而担心吗?
A.是,因为这意味着神经网络的学习速率有问题。
B.否,只要训练和验证错误累积减少,我们就不必担心。
答案:(B) 选项B是正确的,为了减少这些“起伏”,可以尝试增加批尺寸(batch size)
43.什么是影响神经网络的深度选择的因素?
1.神经网络的类型,例如:多层感知机(Multi-Layer Perceptrons, MLP),卷积神经网络(Convolutional Neural Networks, CNN)
2.输入数据
3.计算能力,即硬件和软件能力
4.学习率
5.输出函数映射
A. 1, 2, 4, 5
B. 2, 3, 4, 5
C. 1, 3, 4, 5
D. 以上均是
答案:(D) 所有上述因素对于选择神经网络模型的深度都是重要的。
44.考虑这种情况:您尝试解决的问题有少量的数据。幸运的是,您有一个之前训练过的针对类似问题的神经网络模型。您将使用以下哪种方法来使用该预先训练的模型?
A.对于新的数据集重新训练模型
B.在每一层评估模型如何执行,只选择其中的一些
C.只微调最后几层
D.冻结除最后一层之外的所有层,重新训练最后一层
答案:(D) 如果数据集大部分相似,最好的方法是只训练最后一层,因为前面的所有层都用于特征提取。
45.增大卷积核的大小必然会提高卷积神经网络的性能。
A.正确
B.错误
答案:(B) 增加核函数的大小不一定会提高性能。这个问题在很大程度上取决于数据集。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消