











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Facebook的NLP库的使用:利用FastText进行文本分类和词提示
2017年07月24日 由 xiaoshan.xiang 发表
111773
0
介绍
现在, 社交软件Facebook面临诸多挑战。Facebook每天处理大量的各种形式的文本数据,例如状态更新、评论等等。而对Facebook来说,更重要的是利用这些文本数据更好地为其用户提供服务。使用由数十亿用户生成的文本数据来计算字表示法是一个耗资巨大的任务,直到Facebook开发自己的库FastText用于词汇表现和文本分类。
在本文中,我们将看到FastText如何计算word representation并执行文本分类,它可以在几秒内完成其他算法几天才可以完成的任务,并且实现相同的功能。
目录
1.什么是FastText?
2.安装
3.执行
4.优点和缺点
5.结语
1.什么是FastText?
FastText是Facebook研究团队创建的一个库,用于高效学习word representation和句子分类。
这个库在NLP社区获得了用户的大量支持,并且可能替代gensim包,它提供了像Word Vectors(词向量)这样的功能。如果您刚接触词向量和word representation,那么我建议您首先阅读这篇 文章,会对此有一个大致的了解。
但是我们应该真正的问题是 - FastText与gensim 词向量有何不同?
区别在于,词向量a.k.a word2vec 将每个词视为要找到向量表征的最小单位,但FastText假定一个词由n个字符组成,例如,阳光由[sun ,sunn,sunny],[sunny,unny,nny]等,其中n的范围是从1到词语的长度。fastText的这个新的表示方法比word2vec或glove要多出以下几个优点。
找到罕见词的向量表示是有帮助的。由于罕见词仍然可以被分解成字符n-gram,所以它们可以与通用字共享这些n-gram。
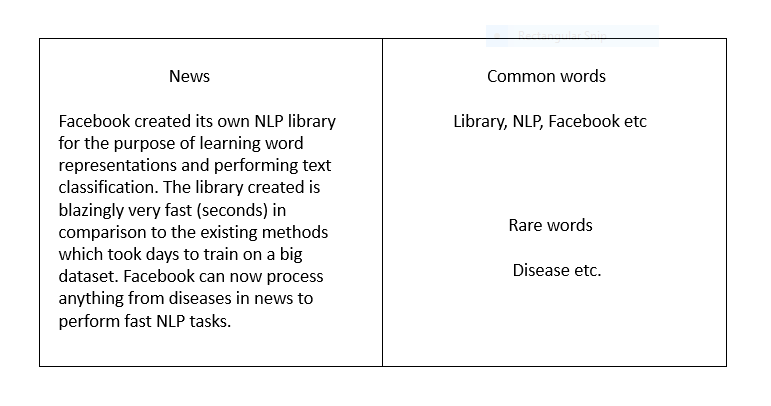
它可以给出词典中不存在的字(OOV字)的向量表示,因为这些字也可以分解成字符n-gram。word2vec和glove 都不能对词典中不存在的词提供字的向量。
例如,对于像stupedofantabulouslyfantastic这样的词语,可能永远都不在任何语料库,gensim可能会去选择以下两个解决方案中的任意一个 - a)零向量 或 b)具有低幅度的随机向量。但是FastText可以通过将上面的词分成数据块,并使用这些数据块的向量来创建这个词的最终向量,从而可以产生比随机向量更好的向量。
字符n-gram在更小的数据集上比word2vec和glove更出色。。
现在我们来看下面安装FastText库的步骤。
2.安装
要充分利用FastText库,请确保您满足以下要求:
- 操作系统 - MacOS或Linux
- C ++编译器 - gcc或clang
- Python 2.6+,numpy和scipy。
如果您没有满足上述先决条件,我希望您先安装以上程序。
要安装FastText,请在下面输入代码 -
git clone https://github.com/facebookresearch/fastText.git
cd fastText
make
您可以通过在FastText文件夹中键入以下命令来检查FastText是否已正确安装。
./fasttext
如果一切安装正确,那么您应该看到FastText的可用命令列表作为输出。
3.执行
如前所述,FastText是为两个特定目的而设计的 – Word representation学习和文本分类。现在我们将详细地学习这些步骤。
学习Word representation
自然形式的词语一般不能用于任何机器学习任务。使用这些词的一种方式是将这些词转换为捕获该词的某些属性。它类似于描述一个人,因为 - ['height':5.10,'weight':75,'color':'dusky'等]其中height,weight等是人的属性。类似地,word representation用相似的词倾向于相似的词的表示方式捕获词的抽象属性。主要有两种用于开发词向量的方法 - Skipgram和CBOW。
我们将看到如何实现这两种方法来学习使用fasttext 的示例文本文件的向量表示。
使用Skipgram和CBOW模型学习字表征
1.Skipgram
./fasttext skipgram -input file.txt -output model
2.CBOW
./fasttext cbow -input file.txt -output model
让我们看看上面定义的参数,以便于理解。
./fasttext - 用于调用FastText库。
skipgram / cbow - 您指定是否使用skipgram或cbow来创建word representation。
-input - 这是参数的名称,它指定使用的名称作为训练的文件的名称,这个参数应该原样使用。
data.txt - 我们希望培训skipgram或cbow模型的示例文本文件。将此名称更改为您所拥有的文本文件的名称。
-output - 这是参数的名称,它指定使用的名称作为创建模型的名称。这个参数应该原样使用。
model - 这是创建的模型的名称。
运行上述命令将创建两个名为model.bin和model.vec的文件。model.bin包含模型参数,字典和超参数,可用于计算词向量。model.vec是一个文本文件,其中每行包含一个词的词向量。
现在,由于我们创建了自己的词向量,我们来看看我们是否可以使用这些词向量来做一些常见的任务,比如寻找类似的词,类比等。
输出词的词向量
获取一个词或一组词的词向量,将它们保存在一个文本文件中。例如,这里有一个包含一些随机字的名为queries.txt 的示例文本文件。我们将使用我们上面训练的模型来获得这些词的向量表示。
./fasttext print-word-vectors model.bin < queries.txt
要检查一个词的词向量,而且不保存到一个文件中,可以这样做
echo "word" | ./fasttext print-word-vectors model.bin
找到类似的词
你也可以寻找最相似于给定词语的词。该功能由nn 参数提供。让我们看看如何找到与“happy”最相似的词。
./fasttext nn model.bin
键入上述命令后,终端将要求您输入查询词。
happy
by 0.183204
be 0.0822266
training 0.0522333
the 0.0404951
similar 0.036328
and 0.0248938
The 0.0229364
word 0.00767293
that 0.00138793
syntactic -0.00251774
上面的结果是和happy最相似的词。 有趣的是,此功能也可用于修正拼写错误。例如,当您输入错误的拼写时,它会显示在训练文件中出现的词的正确拼写。
wrd
word 0.481091
words. 0.389373
words 0.370469
word2vec 0.354458
more 0.345805
and 0.333076
with 0.325603
in 0.268813
Word2vec 0.26591
or 0.263104
类比
FastText字向量也可以用于类别任务,什么对于C等同于B对于A?
这里,A,B和C是词。
类比功能由参数类比提供。让我们借助一个例子来看一下。
./fasttext analogies model.bin
上述命令将要求输入A-B + C格式的字,但是我们只需要用空格分隔三个字。
happy sad angry
of 0.199229
the 0.187058
context 0.158968
a 0.151884
as 0.142561
The 0.136407
or 0.119725
on 0.117082
and 0.113304
be 0.0996916
在一个非常大的语料库上进行训练会产生更好的结果。
文本分类
如名称所示,文本分类是使用特定的类标来标记文本中的每个文档。情感分析和电子邮件分类是文本分类的典型例子。在这个技术时代,每天都会产生数百万的数字文件。这将花费大量的时间和人力将它们分类为合理的类别,如垃圾邮件和非垃圾邮件,重要和不重要等等。NLP的文本分类技术可以帮助我们。我们来看一下基于情感分析问题的实践操作。我从kaggle收集了这个分析的数据。
在我们开始执行之前,有一个关于训练文件的警告。我们要训练我们的模型的文本文件的默认格式应该是_ _ label _ _
其中_ _label_ _是类的前缀,而
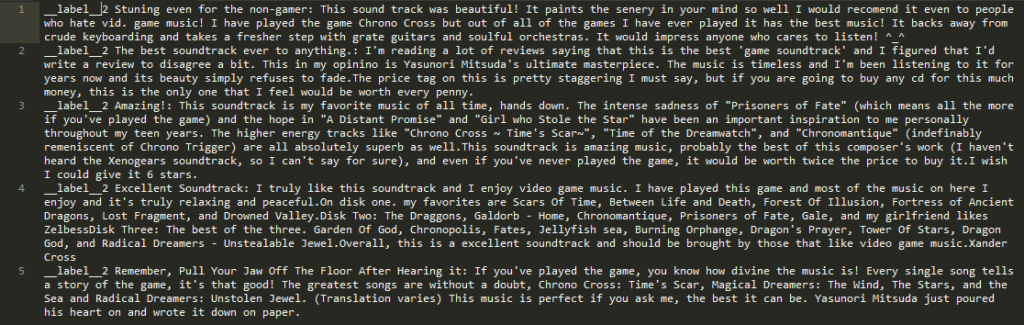
事实上,我选择这篇文章的数据的原因是数据已经完全按照所需的默认格式提供了。如果您对FastText不熟悉,并且第一次在FastText中实现文本分类,我强烈推荐使用上述数据。
如果您的数据具有标签的其他格式,不要不安。一旦您传递了一个合适的逻辑论证,FastText就会注意到它。
在介绍文本分类后,让我们进一步了解实施部分。我们将使用train.ft文本文件来训练模型和预测。
#训练分类器
./fasttext supervised -input train.ft.txt -output model_kaggle -label __label__
这里,参数与创建word representation时所提到的参数相同。唯一的附加参数是-label。 此参数处理指定的标签的格式。您下载的文件包含前缀__label__的标签。
如果您不想使用默认参数来训练模型,则可以在训练时间内指定它们。例如,如果您明确要指定训练过程的学习率,则可以使用参数-lr 来指定学习速率。
./fasttext supervised -input train.ft.txt -output model_kaggle -label __label__ -lr 0.5
可以调整的其他可用参数是 -
- -lr:学习速率[0.1]
- -lrUpdateRate:更改学习率的更新速率[100]
- -dim :字向量大小[100]
- -ws:上下文窗口的大小[5]
- -epoch:历元数[5]
- -neg:抽样数量[5]
- -loss:损失函数 {ns,hs,softmax} [ns]
- -thread:线程数[12]
- -pretrainedVectors:用于监督学习的预培训字向量
- -saveOutput:输出参数是否应该保存[0]
方括号[]中的值表示传递的参数的默认值。
#测试结果
./fasttext test model_kaggle.bin test.ft.txt
N 400000
P@1 0.916
R@1 0.916
Number of examples: 400000
P@1 is the precision
R@1 is the recall
#预测测试数据集
./fasttext predict model_kaggle.bin test.ft.txt
#预测前3名标签
./fasttext predict model_kaggle.bin test.ft.txt 3
计算句子向量(受监督)
该模型也可用于计算句子向量。让我们看看如何使用以下命令来计算句子向量。
echo "this is a sample sentence" | ./fasttext print-sentence-vectors model_kaggle.bin
0.008204 0.016523 -0.028591 -0.0019852 -0.0043028 0.044917 -0.055856 -0.057333 0.16713 0.079895 0.0034849 0.052638 -0.073566 0.10069 0.0098551 -0.016581 -0.023504 -0.027494 -0.070747 -0.028199 0.068043 0.082783 -0.033781 0.051088 -0.024244 -0.031605 0.091783 -0.029228 -0.017851 0.047316 0.013819 0.072576 -0.004047 -0.10553 -0.12998 0.021245 0.0019761 -0.0068286 0.021346 0.012595 0.0016618 0.02793 0.0088362 0.031308 0.035874 -0.0078695 0.019297 0.032703 0.015868 0.025272 -0.035632 0.031488 -0.027837 0.020735 -0.01791 -0.021394 0.0055139 0.009132 -0.0042779 0.008727 -0.034485 0.027236 0.091251 0.018552 -0.019416 0.0094632 -0.0040765 0.012285 0.0039224 -0.0024119 -0.0023406 0.0025112 -0.0022772 0.0010826 0.0006142 0.0009227 0.016582 0.011488 0.019017 -0.0043627 0.00014679 -0.003167 0.0016855 -0.002838 0.0050221 -0.00078066 0.0015846 -0.0018429 0.0016942 -0.04923 0.056873 0.019886 0.043118 -0.002863 -0.0087295 -0.033149 -0.0030569 0.0063657 0.0016887 -0.0022234
4.优点和缺点
像每个库一样,它也有自己的优缺点。让我们明确说明。
优点
1.与实现相同精度的其他方法相比,该库的速度惊人。这是Facebook研究团队发布的支持这一论点的结果。

2.句子向量(被监督)可以很容易的计算。
3.与gensim相比,fastText在小数据集上的运行效果更好。
4.在语义性能上,fastText在语法表现和FAIR语言表现都优于gensim。
缺点
1.这不是NLP的独立库,因为它将需要另一个库进行预处理步骤。
2.虽然,这个库有一个python实现,但它没有得到官方支持。
5.结语
对于想要更深入地了解fastText和gensim性能差异的人,您可以访问此链接。
此文为编译文章,作者NSS,原网址为https://www.analyticsvidhya.com/blog/2017/07/word-representations-text-classification-using-fasttext-nlp-facebook/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消