











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






从新一代TPU到Google.ai,详解谷歌I/O首日人工智能五大亮点
2017年05月18日 由 duketxl 发表
280252
0
从大会主题演讲可以看出,谷歌人工智能主要体现在以下五大方面:
- AI First 的整体战略;
- TPU 的升级与云服务;
- 集研究、工具、应用于一体的 Google.ai ;
- 人工智能技术的产品落地;
- 基于安卓和 TensorFlow 的移动开发者生态。

重申 AI First
去年 10 月的谷歌新品发布会期间,谷歌 CEO Sundar Pichai 曾撰文解读谷歌从 Mobile First 向 AI First 的战略转变。他认为在接下来 10 年中,谷歌将转向建立 AI First 的世界。
Pichai 在本届大会上再次强调了谷歌 AI First 战略的重要性,他表示,机器学习已经在谷歌的诸多产品中得到了广泛应用,其中包括搜索排序、街景、图片搜索、智能回复、YouTube 推荐等。
在具体技术方面,Pichai 说:「声音和视觉是一种新的计算形式。我们正在见证计算机视觉和语音领域的诸多伟大进步。」
谷歌的语音识别技术的词错率逐年下降,仅从去年 7 月到现在就实现了 8.5% 到 4.9% 的极大改进;而且即使在有噪音存在的情况下也能表现良好。在 Google Home 刚发布时,原本需要 8 个麦克风才能准确定位周围的说话人,「而借助深度学习,我们最后能够推出仅有 2 个麦克风的产品,而且达到了同样质量。」现在 Google Home 已经能识别 6 个不同的说话人并为他们定制个性化体验。
在处理某些任务时,图像识别的准确度也超过了人类水平,并且应用到了 Pixel 系列手机的相机应用中,来自动清除图像中的噪点,实现高质量的夜间成像效果;不久之后甚至还可以自动移除照片上的遮挡物,比如挡在相机前的棒球场围网。
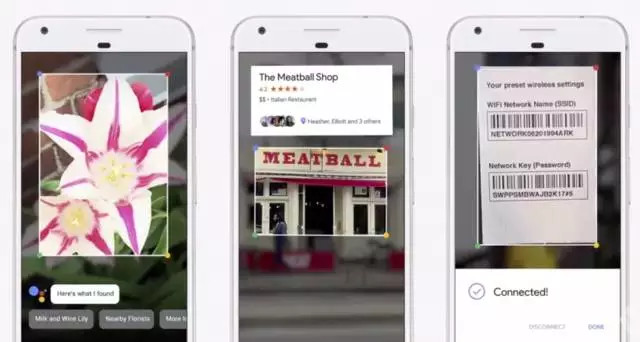
在这些计算机视觉技术的基础上,谷歌又发布了 Google Lens 。这个功能将首先出现在 Google Assistant 和 Photos 中,用户可以使用 Google Lens 来识别花的品种、扫描设置好的条形码来连接 WiFi 、在大街上扫描店面来了解网上评价。
TPU 云服务
AI First 的战略需要 AI First 的数据中心,为此谷歌打造了为机器学习定制的硬件 TPU 。去年发布时,TPU 的速度比当时 CPU 和 GPU 的速度快 15 到 30 倍,功耗效率高 30 到 80 倍。如今的 TPU 已经在为谷歌的各种机器学习应用提供支持,包括之前战胜李世石的 AlphaGo 。
Pichai 介绍道,深度学习分为两个阶段:训练(training)和推理(inference)。其中训练阶段是非常计算密集型的,比如,谷歌的一个机器翻译模型每周就要处理至少 30 亿词的训练数据,需要数百个 GPU,去年的 TPU 就是专门为推理阶段优化的;而在今年的 I/O 大会上,Pichai 宣布了下一代 TPU——Cloud TPU——其既为推理阶段进行了优化,也为训练阶段进行了优化。在现场展示的一块 Cloud TPU 板图片上有 4 块芯片,其处理速度可达 180 teraflops(每秒万亿次浮点运算)。
 此外,Cloud TPU 还可以轻松实现集成组合,你可以将 64 块 TPU 组合成一个「超级计算机」,即一个 pod ,每个 pod 的速度可达 11.5 petaflops(每秒千万亿次浮点运算);另外,Pichai 还宣布将 Cloud TPU 应用到了 Google Compute Engine 中。
此外,Cloud TPU 还可以轻松实现集成组合,你可以将 64 块 TPU 组合成一个「超级计算机」,即一个 pod ,每个 pod 的速度可达 11.5 petaflops(每秒千万亿次浮点运算);另外,Pichai 还宣布将 Cloud TPU 应用到了 Google Compute Engine 中。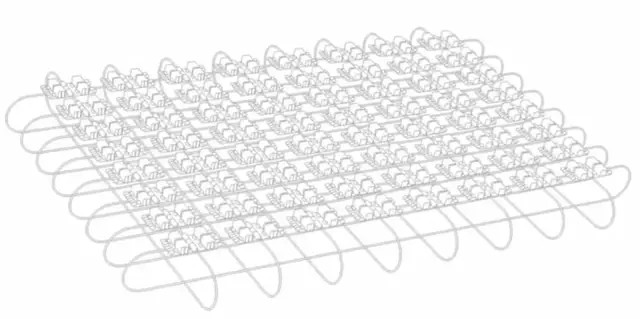 一个 Cloud TPU Pod 示意图,包含 64 块 Cloud TPU
一个 Cloud TPU Pod 示意图,包含 64 块 Cloud TPU正如 Pichai 所言,「我们希望谷歌云是最好的机器学习云,并为用户提供 CPU 、GPU 和 TPU 等更广泛的硬件支持。」
在下午的开发者 Keynote 中,谷歌云机器学习与人工智能首席科学家李飞飞也表示,每个人都可通过谷歌的云平台使用云 TPU,不久之后将会开放租借。
李飞飞在下午的开发者 Keynote 演讲
Google.ai 与 AutoML
为推动使用人工智能解决实际问题,Pichai 宣布将谷歌人工智能方面的工作综合到 Google.ai 下。总体而言,Google.ai 将专注于三个领域:研究、工具和应用。
 在研究方面,深度学习模型方面的进步令人振奋,但设计和开发却很耗费时间,只有少量工程师和科学家愿意去研究它们。为了让更多开发者使用机器学习,谷歌提出了 AutoML——让神经网络来设计神经网络。
在研究方面,深度学习模型方面的进步令人振奋,但设计和开发却很耗费时间,只有少量工程师和科学家愿意去研究它们。为了让更多开发者使用机器学习,谷歌提出了 AutoML——让神经网络来设计神经网络。 AutoML 是一种「learning to learn」的方法。在此方法中,一种控制器神经网络能够提议一个「子」模型架构,然后针对特定任务进行训练与质量评估;而反馈给控制器的信息则会被用来改进下一轮的提议。谷歌在技术博客中表示,他们已经将此过程重复了上千次,从而来生成新架构,然后经过测试和反馈,让控制器进行学习。最终,控制器将学会为好的架构分配高的概率。
AutoML 是一种「learning to learn」的方法。在此方法中,一种控制器神经网络能够提议一个「子」模型架构,然后针对特定任务进行训练与质量评估;而反馈给控制器的信息则会被用来改进下一轮的提议。谷歌在技术博客中表示,他们已经将此过程重复了上千次,从而来生成新架构,然后经过测试和反馈,让控制器进行学习。最终,控制器将学会为好的架构分配高的概率。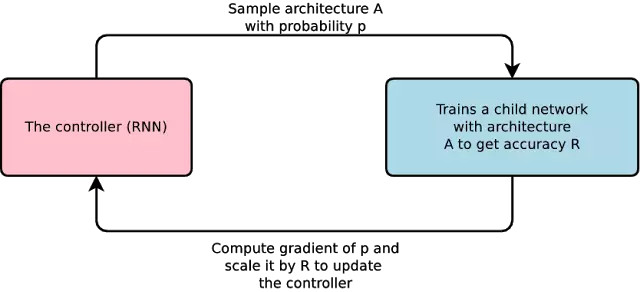 AutoML 流程图
AutoML 流程图AutoML 会产生什么样的神经网络?以循环架构为例(用来在 Penn Treebank 数据集上预测下一单词),如下图所示:
 左边为人类专家设计的神经网络,右边为 AutoML 方法创造的循环架构,两个架构有着共同的设计特征。
左边为人类专家设计的神经网络,右边为 AutoML 方法创造的循环架构,两个架构有着共同的设计特征。Pichai 认为,AutoML 具有很大的潜力,并且,谷歌已经在图像识别基准数据集 CIFAR-10 上取得了顶尖成果。虽然过程很难,但云 TPU 的存在使这种方法成为了可能。
有了这些前沿的研究,接下来就是应用的问题。Pichai 列举了谷歌应用机器学习的几个案例:比如在医疗领域诊断癌症的应用和在基础科学领域的应用(比如在生物学上,谷歌通过训练神经网络来改进 DNA 测序的准确率;在化学领域,谷歌通过使用机器学习了预测分子性质)。
产品及应用
谷歌 AI First 战略不仅体现在研究上,还体现在众多人工智能技术的应用上——将谷歌的各项人工智能技术在产品层面统一起来。Pichai 提到:「计算机仍在不断地进化,从 Mobile First 的世界进化到 AI First 的世界。我们也在重新思考我们所有的产品。」
1. Google Assistant
谷歌正将人工智能应用于所有产品中,Pichai 表示,其中最重要的就是谷歌搜索和 Google Assistant 。自去年 I/O 大会发布以来,Google Assistant 已经可以在上亿台设备上使用。今天 Google Assistant 工程副总裁 Scott Huffman 又介绍了 Google Assistant 三大进步。
1)更自然的对话
Google Assistant 上 70% 的请求都是通过自然语言的方式进行的,而非键盘输入。而谷歌要做的就是结合语音识别、自然语言处理以及语境意义方面的技术来解决用户双手,实现更加自然的人机交流。「Google Assistant 可以通过聆听学会区分不同家庭成员的声音。」他说。除了语音识别和自然语言处理,Google Assistant 还使用了 Google Lens 功能,通过图像信息来实现更加自然的「对话」。
2)更广泛的应用
Huffman 表示,Google Assistant 正变得更加广泛可用,除了之前的安卓系统,Google Assistant 已经可以在 iPhone 上使用。而随着 Google Assistant SDK 的发布,任何设备生产商都能简单轻松地将 Google Assistant 部署在音响、玩具和机器人等设备上;此外,今年夏天,Google Assistant 也开始将支持法语、德语、葡萄牙语和日语,并将在年底新增意大利语、韩语和西班牙语等语言。
3)更触手可及的服务
用户使用 Google Assistant 不仅仅是搜索信息,还希望获取所有服务,比如 Gmail 、Google Photos 、谷歌地图和 YouTube 等。因此,谷歌将 Google Assistant 开放给了第三方开发者,以实现产品间更加有用的融合。据 Google Assistant 产品经理 Valerie Nygaard 介绍,Google Assistant 将支持交易,从而为第三方提供端到端的完整解决方案。
Google Assistant 的进步也使得智能家居产品 Google Home 新增了 50 项新功能——用户可以通过语音去调用各种服务,包括免费电话、免费听音乐,以及在电视上观看视频等。
同时,基于本次大会上多次提及的「语音加图像」的多模态交互,此前缺乏视觉交互 Google Home 现在也可以借助手机和电视的屏幕与用户进行更好的互动,比如,用户可以通过语音命令让 Google Home 把你的日程在电视上显示。就像 Nygaard 所说的那样,用户可以 hands-free 的做任何事情。如今 Google Assistant 已经开始支持交易并集成到智能家居设备中,目前拥有超过 70 家智能家居合作者。
2. Google Photos
Google Photos 目前拥有十亿月度活跃用户,每天上传的照片和视频达到 12 亿次。借助于谷歌的核心人工智能技术,如今 Google Photos 使用了全新的图像处理方法。这从此次发布的三个新功能可以看出:
- Suggest Sharing 可以借助机器学习将照片中的人物和场景识别出来,然后给用户提供分享建议——是否应该分享以及分享给谁。
- Shared Libraries 基于用户识别的相片库分享。
- Photo Books 自动帮助用户筛选出某一场景下的高质量照片并生成相册。
另外,除了 Google Assistant ,Google Lens 也被集成到了 Google Photos 中。通过这个功能,你可以识别相册里面的地标建筑、检索艺术作品背后的故事、识别照片内的文本内容和信息,这项功能将于今年晚些时候发布。
用 TensorFlowLite 构建移动开发者生态
机器学习在移动端的应用至关重要,而在讨论安卓的未来时,谷歌工程副总裁 Dave Burke 宣布了一个为移动端优化的 TensorFlow 版本——TensorFlowLite 。TensorFlowLite 能让更多的开发者建立在安卓手机上运行的深度学习模型。而 TensorFlowLite 就是谷歌在移动端部署人工智能的一个着力点。首先,TensorFlowLite 很小很快,但依然可以使用最先进的技术,包括卷积神经网络、LSTM 等;其次,Dave Burke 还宣布在安卓上推出了一个新的框架来进行硬件加速,期待看到为神经网络的训练和推理特别定制的 DSP 。这些新能力将促进新一代设备上(on-device)语音识别、视觉搜索和增强现实的发展。
去年,Facebook 公开了 Caffe2Go ,今年更是开源了可在手机与树莓派上训练和部署神经网络模型的 Caffe2 。在移动端部署机器学习成为了一项新的挑战。但不幸的是,手机上训练神经网络仍是计算密集型任务。即便忽略训练,预训练模型仍旧艰难。但如果能在边缘设备运行模型,就能避免云和网络,在任何环境中有更可靠的表现。谷歌表示他们会开源该项工作,并计划在今年晚些时候发布 API 。
谷歌首日 Keynote ,让我们看到了谷歌围绕机器学习研究、开源工具、基础设施和人工智能应用开发的 AI First 战略。Cloud TPU 是加速人工智能部署的基础设施;AutoML 代表着机器学习研究层面的前沿方向;TensorFlowLite 将促进人工智能在移动端的部署;语音和图像的结合代表着对多模态人机交互的探索;而应用了各种人工智能技术的产品更新则是极大推动了将 AI 真正融入生活的进程。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消