











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






GAN最新研究进展与提高其性能的技术
2019年02月16日 由 浅浅 发表
905579
0
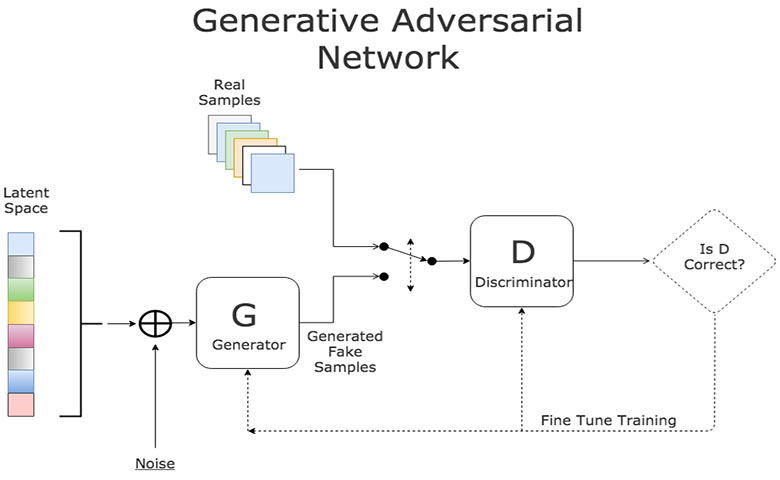 生成对抗性网络(GAN)是一类功能强大的神经网络,具有广泛的应用前景。它们本质上是由两个神经网络组成的系统:一个是生成神经网络,另一个是鉴别神经网络。
生成对抗性网络(GAN)是一类功能强大的神经网络,具有广泛的应用前景。它们本质上是由两个神经网络组成的系统:一个是生成神经网络,另一个是鉴别神经网络。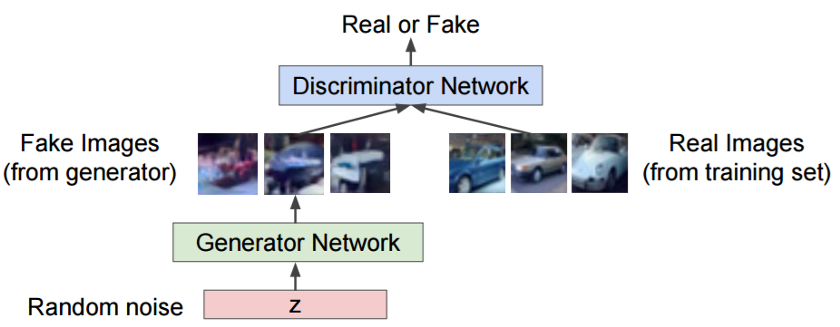
给定一组目标样本,生成器试图生成能够欺骗鉴别器的样本,使其相信这些样本是真实的。鉴别器试图从(生成的)样本中分辨出真实(目标)的样品。使用这种迭代训练方法,我们最终得到一个真正擅长生成类似于目标样本的生成器。
GAN有大量的应用程序,因为它们可以模拟几乎任何类型的数据分布。通常,GAN用于删除人工制品、超分辨率、姿势转换,以及任何类型的图像转换,如下所示:
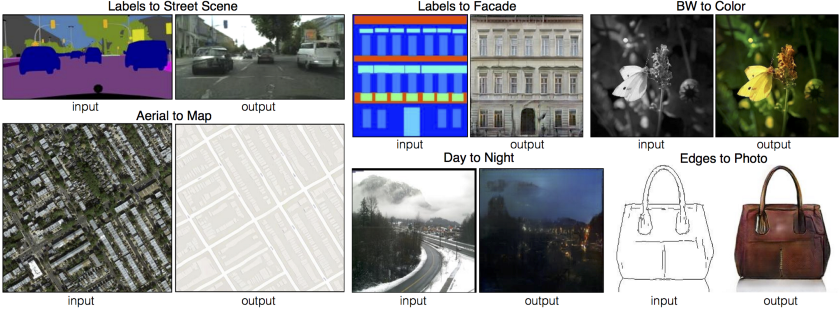
使用GAN进行图像转换。
然而,由于其不稳定性,它们难以使用。毋庸置疑,许多研究人员已提出了出色的解决方案来减轻训练GAN所涉及的一些问题。然而,这一领域的研究发展得如此之快,以至于很难跟踪有趣的想法。下面会列出一些常用于使GAN训练稳定的流行技术。
使用GAN的缺点
1.模式崩溃
自然数据分布是高度复杂和多模态的。也就是说,数据分布具有许多“峰值”或“模式”。每种模式表示相似数据样本的集中度,但不同于其他模式。
在模式崩溃期间,生成器生成属于有限模式集的样本。当生成器认为它可以通过锁定单一模式来欺骗鉴别器时,就会发生这种情况。也就是说,生成器只从这种模式生成样本。

顶部的图像表示没有模式崩溃的GAN的输出。底部的图像表示模式崩溃的GAN的输出。
鉴别器最终发现这种模式的样本是假的。结果,生成器只是锁定到另一种模式。该循环无限重复,这基本上限制了所生成样品的多样性。
2.会聚
GAN训练中的一个常见问题是“我们什么时候停止训练?”
由于当鉴别器损耗降低时生成器损耗增加(反之亦然),我们无法根据损耗函数的值来判断会聚。如下图所示:
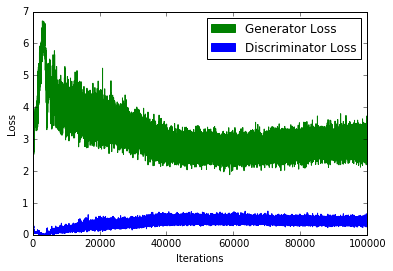
典型GAN损失函数。请注意如何从该图中解释会聚。
3.质量
与前一个问题一样,很难定量地判断生成器何时生成高质量的样品。在损失函数中加入额外的感知正则化可以在一定程度上缓解这种情况。
4.度量标准
GAN目标函数解释了生成器或鉴别器相对于其对手的性能。然而,它并不代表输出的质量或多样性。因此,我们需要能够度量相同的不同度量标准。
术语
在深入研究可以帮助提高性能的技术之前,让我们回顾一些术语。
1.Inimum和Supremum
简而言之,Infimum是集合的最大下界。Supremum是一组中最小的上界。它们与最小值和最大值不同,因为下限和上限不需要属于集合。
2.散度测度
散度测度表示两个分布之间的距离。传统的GAN基本上最小化了实际数据分布和生成的数据分布之间的Jensen Shannon偏差。可以修改GAN损失函数以最小化其他分歧度量,例如Kulback Leibler散度或总变异距离。通常,Wasserstein GAN最小化Earth Mover距离。
3. Kantorovich Rubenstein二元性
一些散度测度难以以纯粹的形式进行优化。然而,它们的双重形式(用supremum替换infimum,反之亦然)可易于优化。二元性原则为将一种形式转换为另一种形式奠定了框架。
4. Lipschitz连续性
Lipschitz连续函数的变化速度是有限的。对于Lipschitz连续的函数,函数图的斜率(对于任何点对)的绝对值不能大于实值K。这些函数也称为K-Lipschitz连续。
在GAN中需要Lipschitz连续性,因为它们限制了鉴别器的梯度,从而基本上防止了爆炸梯度问题。此外,Kantorovich-Rubinstein二元性要求它为Wasserstein GAN。
提高性能的技术
有许多技巧和技巧可用于使GAN更稳定和更强大。下面只解释了相对较新或复杂的技术。
1.替代损失函数
GAN最常见的修复方法之一是Wasserstein GAN。它基本上取代了传统GAN的Jensen Shannon散度与Earth Mover distance(Wasserstein-1距离或EM距离)。EM距离的原始形式是难以处理的,因此我们使用其双重形式(由Kantorovich Rubenstein Duality计算)。这要求鉴别器为1-Lipschitz,其通过削减鉴别器的权重来维持。
使用Earth Mover distance的优势在于,即使实际和生成的数据分布不相交,它也是连续的,与JS或KL分歧不同。此外,生成的图像质量与损失值(源)之间存在相关性。缺点是,我们需要为每个生成器更新执行多个鉴别器更新(根据原始实现)。此外,作者认为削减鉴别器的权重是确保1-Lipschitz约束的糟糕的方法。
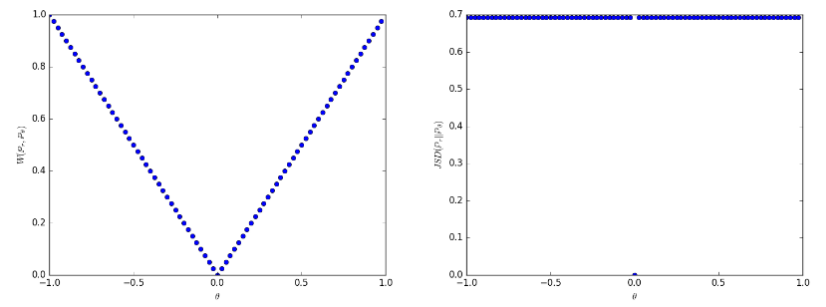
即使分布不连续,Earth Mover distance(左)也是连续的,与Jensen Shannon散度(右)不同。
另一个有趣的解决方案是使用均方损失而不是对数损失。LSGAN的作者认为,传统的GAN损失函数并没有提供太多激励来把生成的数据分布“拉”到接近真实的数据分布。
原始GAN损失函数中的对数丢失不会干扰生成的数据与决策边界的距离(决策边界将实数和假数据分开)。另一方面,LSGAN对远离决策边界产生的样本实施惩罚,基本上是将生成的数据分布“拉”到更接近真实的数据分布。它通过用均方损失替换对数损失来实现这一点。
2.两个时间尺度更新规则(TTUR)
在这种方法中,我们对鉴别器和生成器使用不同的学习速率。通常,较慢的更新规则用于生成器,更快的更新规则用于鉴别器。使用这种方法,我们可以按1:1的比例执行生成器和鉴别器更新,只需修改学习率。值得注意的是,SAGAN实现使用了此方法。
3. Gradient Penalty
在论文Improved Training of WGANs中,作者声称削减权重(最初在WGAN中执行)会导致优化问题。削减权重迫使神经网络学习“更简单的近似”以获得最佳数据分布,从而导致较低质量的结果。如果没有正确设置WGAN超参数,权重削减会导致梯度爆炸或消失问题。作者引入了一个简单的梯度惩罚,它被添加到损失函数中,从而减轻了上述问题。此外,保持1-Lipschitz连续性,如在原始WGAN实现中那样。
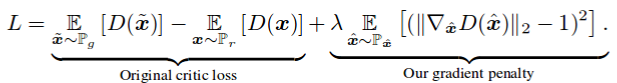
与最初的WGAN-GP论文一样,梯度惩罚作为正规处理器添加。
DRAGAN的作者声称,当GAN所玩的游戏达到“局部平衡状态”时,模式崩溃就会发生。他们还声称,围绕这些状态的鉴别器所贡献的梯度是“尖锐的”。当然,使用梯度惩罚将有助于我们规避这些状态,大大增强稳定性并减少模式崩溃。
4.频谱归一化(Spectral Normalization)
频谱归一化是一种权重归一化技术,通常用于鉴别器以增强训练过程。这基本上确保了鉴别器是K-Lipschitz连续的。
像SAGAN这样的一些实现也使用了Generator上的频谱归一化。还指出该方法在计算上比梯度惩罚更有效。
5.展开和包装
防止模式跳跃的一种方法是预测未来并在更新参数时预测对手。在鉴别器有机会响应之后,展开的GAN使生成器能够欺骗鉴别器(要考虑到反作用)。
防止模式崩溃的另一种方法是在将其传递给Discriminator之前“打包”属于同一类的几个样本。这种方法被纳入PacGAN,论文中报告了模式崩溃已适当减少。
6.堆叠GAN
单个GAN可能不够强大,无法有效地处理任务。我们可以使用连续放置的多个GAN,其中每个GAN解决问题的更简单部分。例如,FashionGAN用了两个GAN进行本地化图像转换。
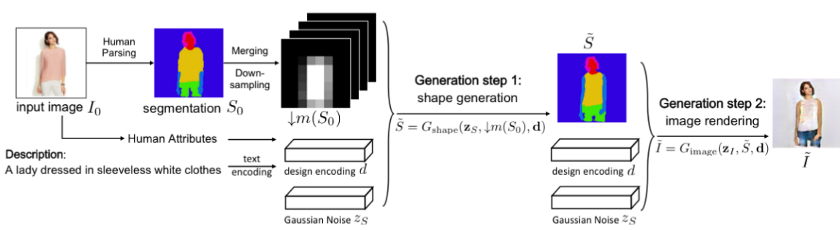
FashionGAN使用两个GAN来执行本地化图像转换。
将这一概念发挥到极致,我们可以逐渐增加向我们的GAN提出问题的难度。例如,渐进式GAN(ProGAN)可以生成具有出色分辨率的高质量图像。
7.Relativistic GAN
传统的GAN测量生成的数据是真实的概率。Relativistic GAN测量所生成数据比实际数据更真实的概率。我们可以使用适当的距离测量来衡量这种相对真实性,如RGAN论文中所述。
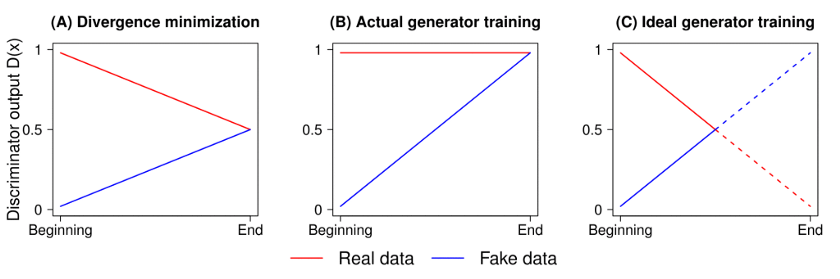
使用标准GAN损耗时的鉴别器输出(图像B)。图像C表示输出曲线的实际外观。图像A代表JS分歧的最佳解决方案。
作者还提到鉴别器输出在达到最佳状态时应会聚到0.5。然而,传统的GAN训练算法迫使鉴别器为任何图像输出“真实”(即1)。这在某种程度上阻止了鉴别器达到其最佳值。该方法也解决了这个问题,并且具有非常显著的结果,如下所示。

5000次迭代后输出标准GAN(左)和Relativistic GAN(右)。
8.自我注意机制
Self Attention GANs论文作者声称,用于生成图像的卷积查看本地传播的信息。也就是说,由于限制性的接受域,它们错过了跨越全局的关系。
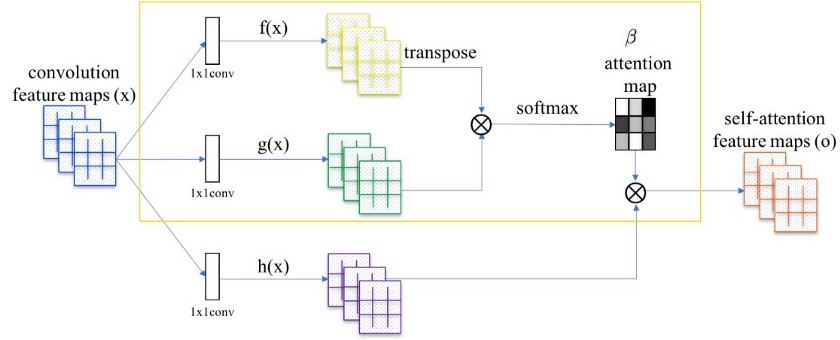
将注意力图(在黄色框中计算)添加到标准卷积操作。
Self Attention GAN允许注意力驱动的远程依赖建模用于图像生成任务。在自我关注的机制是互补的正常卷积运算。全局信息(远程依赖性)有助于生成更高质量的图像。网络可以选择忽略注意机制,或者将其与正常卷积一起考虑。

由红点标记的位置的注意力图可视化。
9.各种各样的技术
以下列出了一些用于改进GAN培训的其他技术(并非详尽无遗!):
- 特征匹配
- 迷你批量区分
- 历史平均
- 单面标签平滑
- 虚拟批量标准化
度量
现在我们已经建立了改进训练的方法,我们需要对其进行定量证明。以下指标通常用于衡量GAN的性能:
1.初始分数
初始分数衡量生成数据的“真实”程度。
该公式由两个部分组成,p(y|x)和p(y) 。这里x是生成器生成的图像,是p(y|x)当你通过x预先训练的初始网络(在ImageNet数据集上预训练,如在原始实现中)传递图像时获得的概率分布。
此外,p(y)是边际概率分布,可以通过p(y|x)对生成的图像的几个不同样本进行平均来计算(x)。这两个术语代表了真实图像所需的两种不同品质:
1.生成的图像必须具有“有意义”的对象(对象清晰且不模糊)。这意味着p(y|x)应该具有“低熵”。换句话说,我们的初始网络必须非常确信生成的图像属于特定的类。
2.生成的图像应该是“多样的”。这意味着p(y)应该具有“高熵”。换句话说,生成器应该生成图像,使得每个图像代表不同的类标签(理想情况下)。
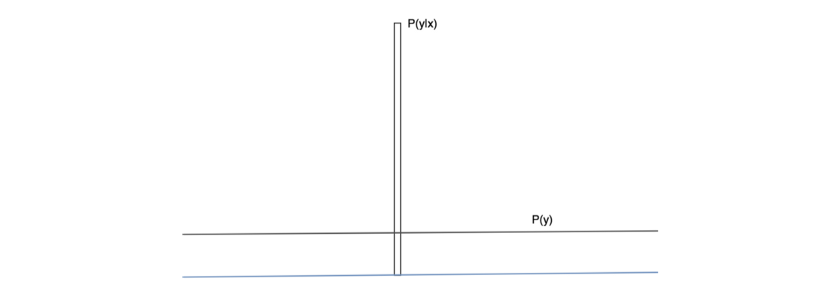
p(y | x)和p(y)的理想图。这样一对将有一个非常大的KL分歧。
如果随机变量是高度可预测的,则它具有低熵(即p(y)必须是具有尖峰的分布)。相反,如果它是不可预测的,它具有高熵(即p(y|x)必须是均匀分布)。如果这两个特征都得到满足,我们应该期望在和之间存在很大的KL差异。当然,大的初始分数(IS)更好。
2.Fréchet起始距离(FID)
初始值的一个缺点是,真实数据的统计数据不能与生成的数据(源)的统计数据进行比较。Fréchet距离通过比较真实和生成图像的均值和协方差来解决这个问题。Fréchet初始距离(FID)执行相同的分析,但是是对通过经过预先训练的Inception-v3网络(源)传递真实图像和生成图像生成的特征图执行相同的分析。该等式描述如下:
FID比较实际数据分布和生成数据分布的均值和协方差。Tr代表Trace。
一个较低的FID成绩更好,说明生成的图像统计量与真实图像统计量非常相似。
结论
研究界已经制作了许多解决方案来克服GAN训练的缺点。然而,由于新研究的庞大数量,很难跟踪所有重要的贡献。由于同样的原因,本博客中分享的详细信息并非详尽无遗,并且可能在不久的将来变得过时。尽管如此,希望这个博客可以作为改进其GAN性能的方法的指南。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消