











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






AI分割:从漫画中准确分离对话气泡
2019年02月25日 由 浮生 发表
663524
0
 分割是把图像分割或扫描成多个片段或像素组,是AI擅长的任务。现在,德国波茨坦大学的科学家开发了一种用于漫画的AI分割工具。
分割是把图像分割或扫描成多个片段或像素组,是AI擅长的任务。现在,德国波茨坦大学的科学家开发了一种用于漫画的AI分割工具。在论文“Deep CNN-based Speech Balloon Detection and Segmentation for Comic Books”中,描述了一个神经网络,它可以检测和分离漫画小说和漫画书中的对话气泡。在测试中,研究人员使用的数据集包含了带有弯曲的小尾巴和弯角的对话气泡,测试F1分数为0.94,研究人员称这是最先进的测试方法。
对话气泡通常由载体,和将载体连接到其根文字符的尾部组成,文本被包含其中。小尾巴和载体形状各异,它将对话气泡分类,因为它们具有不同的功能:与通常用于叙述目的的字相比,对话气泡通常为漫画中的直接言语或人物思想。
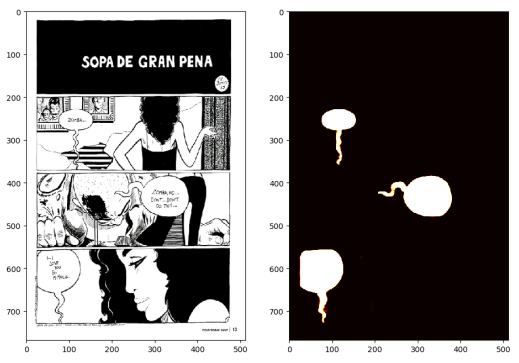
该团队开发了一个全卷积神经网络,一种常用于分析视觉图像的AI,最初用于医学图像分割,经过训练后用于自然图像的分类。他们稍微修改了它,并从90本漫画书中选取750页加入了注释。这些注释来自于图形叙事语料库,这是一个数字库,收录了用英语创作的图形小说、回忆录和非虚构作品。
随着时间的推移,它学会了对漫画中的每个像素进行检测,对对话气泡进行分类。
为了验证他们的方法,研究人员在他们从图形叙事语料库中提取的750张图像的子集(15%)中测试了经过训练的AI系统。令人印象深刻的是,它成功地分离了对话气泡的轮廓线,这些轮廓线不是由物理线条勾勒出来的,而是由定义面板之间空间的线条的假想连续性勾勒出来的。
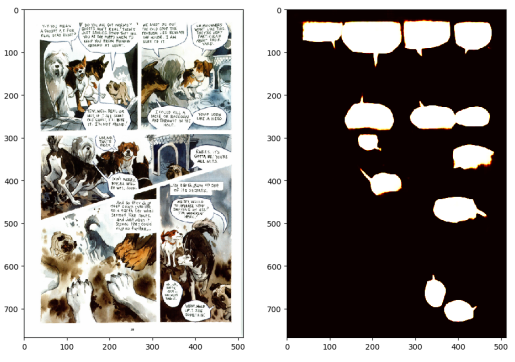
研究人员认为,该AI系统可以用来创建带注释的漫画书语料库,或者作为对历史手稿、科学文章、图表和报纸文章进行常规分割的第一步。未来它可能会帮助视力不好的人开发辅助技术。
这并不是说它现在是完美的。系统对日本漫画中的对话气泡表现不佳,研究人员称这可能是拉丁字母编码的文化特定特征和训练数据集中文本行对话气泡水平方向的原因。但是模型已经用更多漫画样本进行更新,并对模型以分割标题、字符和其他元素进行扩展。
论文:
arxiv.org/pdf/1902.08137.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消