











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






卷积神经网络模型分类
2019年02月25日 由 sunlei 发表
209920
0
卷积神经网络(CNN)是一种特殊的深层的神经网络,广泛应用于视觉图像识别领域。卷积神经网络(CNN)将人工神经网络和深度学习技术相结合而产生的一种新型人工神经网络方法,具有局部感受区域、层次结构化、特征提取和分类过程结合的全局训练的特点,所以对于图像的局部有着相对于准确的识别能力。与其他图像识别算法相比,卷积神经网络(CNN)使用较少的预处理时间,这意味大大缩短了学习所需的时间,减少了学习自由参数的数据量,从而降低了网络运行的内存要求,并允许构建出更强大的神经网络。
接下来我们转到有趣的部分,关于卷积神经网络模型分类。本文只做简单的介绍,关于各个模型的详细解读,请继续关注网站其他相关文章继续深度学习。
LeNet一共有7层(不包括输入层)
[caption id="attachment_37217" align="aligncenter" width="967"] Lenet类似结构[/caption]
Lenet类似结构[/caption]
Input(输入层):输入图像的大小为32*32,这要比mnist数据库中的最大字母(28*28)还大。
作用: 图像较大,这样做的目的是希望潜在的明显特征,比如笔画断续,角点等能够出现在最高层特征监测子感受野的中心。
其他层:Conv1(C1),Conv3(C3),C5为卷积层,S2,S4为降采样层,F6为全连接层,还有一个output(输出层)。
每一个层都有多个Feature Map(每个Feature Map中含有多个神经元),输入通过一种过滤器作用,提取输入的一种特征,得到一个不同的Feature Map。如下图所示:

[caption id="attachment_37219" align="aligncenter" width="618"]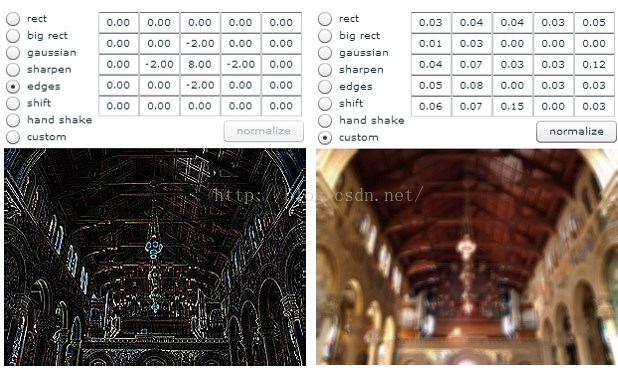 Feature Map[/caption]
Feature Map[/caption]
Alexnet是在2012年ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)获得冠军的model,它证明了CNN在复杂模型下的有效性,利用CNN实现了图片分类,Alex利用CNN精度远超传统的网络。它的模型结构(见下图)由5层卷积层、最大池化层、dropout层和3层全连接层组成。
[caption id="attachment_37220" align="aligncenter" width="775"]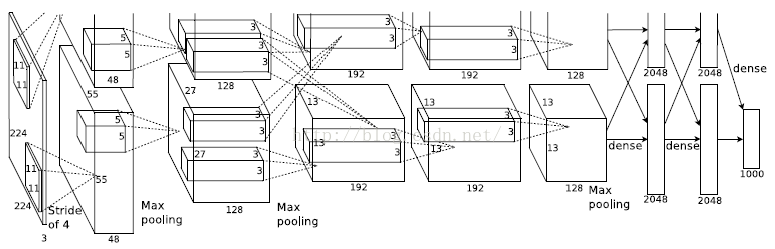 Alexnet模型结构[/caption]
Alexnet模型结构[/caption]
GoogLeNet又称之为inception是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。GoogleNet是一个具有22个conv层的CNN网络,是ILSVRC2014中以6.7%的TOP5错误率登顶大赛榜首的CNN模型,VGG Net以7.3%位居其下。
GoogLeNet(inception)模块的基本机构如下图:
[caption id="attachment_37221" align="aligncenter" width="700"]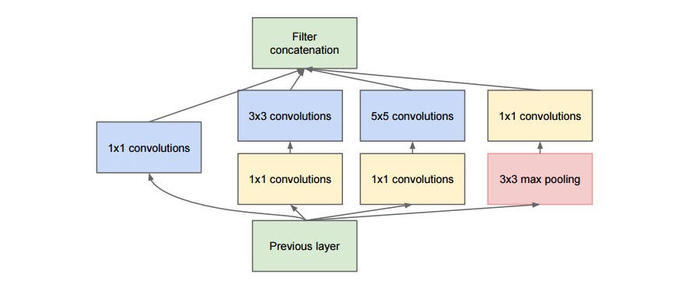 GoogLeNet(inception)模块[/caption]
GoogLeNet(inception)模块[/caption]
当我们看到VGG这个名字,不由得想去探寻名字的由来,VGG是由Oxford的Visual Geometry Group的组提出。2014年牛津大学学者Karen Simonyan 和 Andrew Zisserman创建了一个新的卷积神经网络模型,19层卷积层,卷积核尺寸为3×3,步长为1,最大池化层尺寸为2×2,步长为2。
[caption id="attachment_37222" align="aligncenter" width="470"]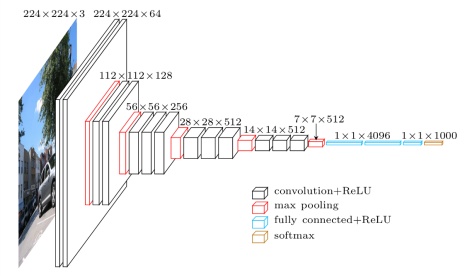 VGG Net[/caption]
VGG Net[/caption]
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
Deep Residual Learning是2015年ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)获得冠军的model,它进一步将conv进行到底,“bottleneck”形式的block(有跨越几层的直连)的设计是它的独到之处。
下面是一个34层的例子,更深的model见表格。
[caption id="attachment_37225" align="aligncenter" width="135"] DeepRsidualLearning[/caption]
DeepRsidualLearning[/caption]
其实这个model构成上更加简单,连LRN这样的layer都没有了。
[caption id="attachment_37223" align="aligncenter" width="1222"]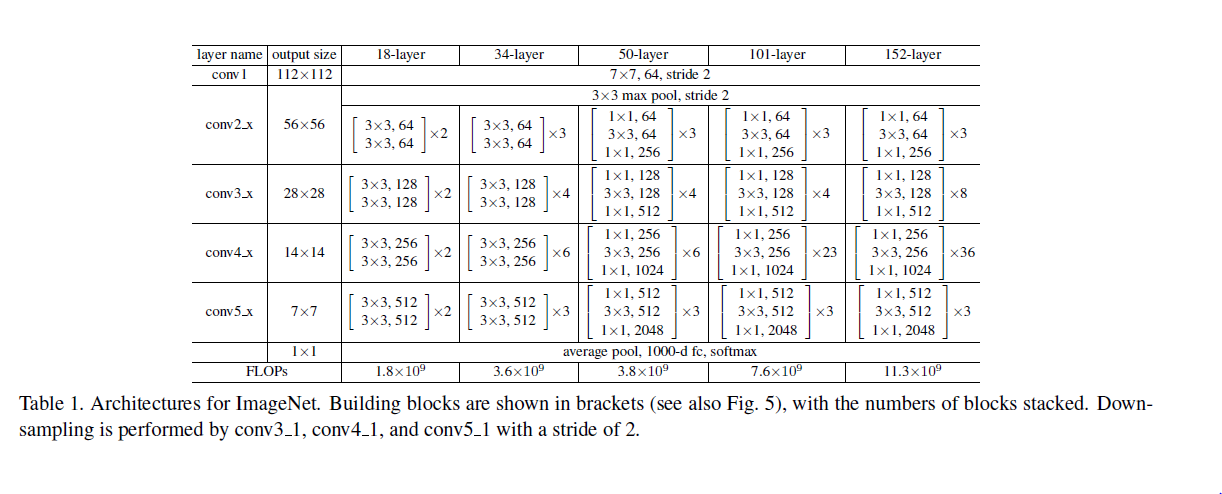 Deep Residual Learning[/caption]
Deep Residual Learning[/caption]
block的构成见下图:
[caption id="attachment_37224" align="aligncenter" width="648"]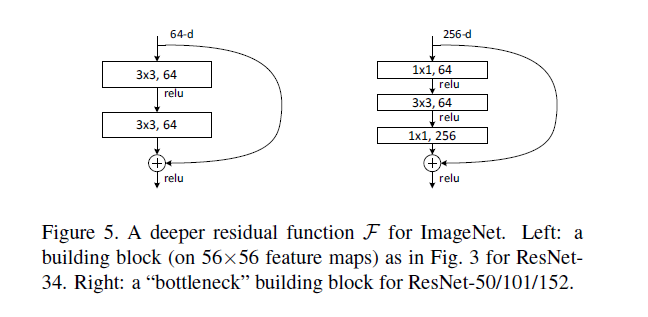 Deep Residual Learning[/caption]
Deep Residual Learning[/caption]
以上5个是卷积神经网络的最常见的模型。虽然本文只是针对几种常见的最新的模型做了简单的阐述,但是依然可以看出目前CNN的设计思路是向着更深度的网络及更多的卷积计算方向发展。未来我们将对卷积神经网络模型做进一步更深入的介绍。
接下来我们转到有趣的部分,关于卷积神经网络模型分类。本文只做简单的介绍,关于各个模型的详细解读,请继续关注网站其他相关文章继续深度学习。
LeNet
LeNet一共有7层(不包括输入层)
[caption id="attachment_37217" align="aligncenter" width="967"]
Lenet类似结构[/caption]Input(输入层):输入图像的大小为32*32,这要比mnist数据库中的最大字母(28*28)还大。
作用: 图像较大,这样做的目的是希望潜在的明显特征,比如笔画断续,角点等能够出现在最高层特征监测子感受野的中心。
其他层:Conv1(C1),Conv3(C3),C5为卷积层,S2,S4为降采样层,F6为全连接层,还有一个output(输出层)。
每一个层都有多个Feature Map(每个Feature Map中含有多个神经元),输入通过一种过滤器作用,提取输入的一种特征,得到一个不同的Feature Map。如下图所示:
[caption id="attachment_37219" align="aligncenter" width="618"]
Feature Map[/caption]Alexnet
Alexnet是在2012年ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)获得冠军的model,它证明了CNN在复杂模型下的有效性,利用CNN实现了图片分类,Alex利用CNN精度远超传统的网络。它的模型结构(见下图)由5层卷积层、最大池化层、dropout层和3层全连接层组成。
[caption id="attachment_37220" align="aligncenter" width="775"]
Alexnet模型结构[/caption]GoogleNet
GoogLeNet又称之为inception是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。GoogleNet是一个具有22个conv层的CNN网络,是ILSVRC2014中以6.7%的TOP5错误率登顶大赛榜首的CNN模型,VGG Net以7.3%位居其下。
GoogLeNet(inception)模块的基本机构如下图:
[caption id="attachment_37221" align="aligncenter" width="700"]
GoogLeNet(inception)模块[/caption]VGG
当我们看到VGG这个名字,不由得想去探寻名字的由来,VGG是由Oxford的Visual Geometry Group的组提出。2014年牛津大学学者Karen Simonyan 和 Andrew Zisserman创建了一个新的卷积神经网络模型,19层卷积层,卷积核尺寸为3×3,步长为1,最大池化层尺寸为2×2,步长为2。
[caption id="attachment_37222" align="aligncenter" width="470"]
VGG Net[/caption]VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
Deep Residual Learning
Deep Residual Learning是2015年ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)获得冠军的model,它进一步将conv进行到底,“bottleneck”形式的block(有跨越几层的直连)的设计是它的独到之处。
下面是一个34层的例子,更深的model见表格。
[caption id="attachment_37225" align="aligncenter" width="135"]
DeepRsidualLearning[/caption]其实这个model构成上更加简单,连LRN这样的layer都没有了。
[caption id="attachment_37223" align="aligncenter" width="1222"]
Deep Residual Learning[/caption]block的构成见下图:
[caption id="attachment_37224" align="aligncenter" width="648"]
Deep Residual Learning[/caption]以上5个是卷积神经网络的最常见的模型。虽然本文只是针对几种常见的最新的模型做了简单的阐述,但是依然可以看出目前CNN的设计思路是向着更深度的网络及更多的卷积计算方向发展。未来我们将对卷积神经网络模型做进一步更深入的介绍。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消