











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌开源GPipe库,可以有效训练大型深度神经网络
2019年03月05日 由 老张 发表
260618
0
 深度神经网络(DNN)已经推进了许多机器学习任务,包括语音识别,视觉识别和语言处理。BigGan,Bert和GPT2.0的最新进展表明,越来越大的DNN模型可以带来越好的性能,而视觉识别任务的进展也表明模型大小和分类准确性之间存在很强的相关性。
深度神经网络(DNN)已经推进了许多机器学习任务,包括语音识别,视觉识别和语言处理。BigGan,Bert和GPT2.0的最新进展表明,越来越大的DNN模型可以带来越好的性能,而视觉识别任务的进展也表明模型大小和分类准确性之间存在很强的相关性。例如,2014年ImageNet视觉识别挑战赛的获胜者是GoogleNet,它以400万参数获得了74.8%的准确率,位居第1,而仅仅三年之后,2017年ImageNet挑战赛的获胜者就使用了Squeeze-and-Excitation网络,其准确率达到82.7%,参数为1.458亿(36倍以上)。然而GPU内存仅增加了约3倍,因此,迫切需要一种高效,可扩展的基础设施,以实现大规模深度学习并克服当前加速器的内存限制。
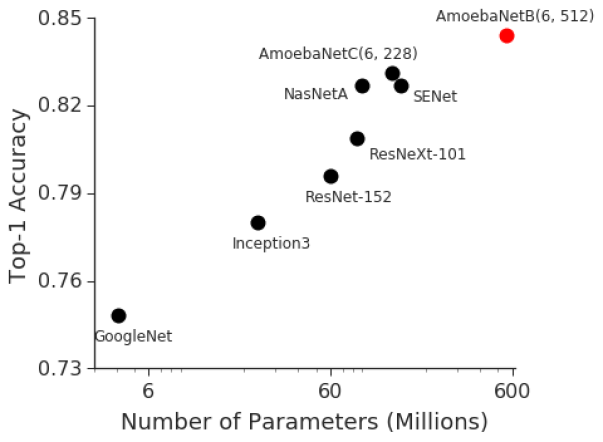
对于最近开发的具有代表性的图像分类模型,ImageNet准确率与模型尺寸相关性强
在论文“GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism”中,谷歌演示了使用管道并行性来扩展DNN训练以克服这一限制。GPipe是一个分布式机器学习库,它使用同步随机梯度下降和管道并行性进行训练,适用于由多个连续层组成的任何DNN。
重要的是,GPipe允许研究人员轻松部署更多加速器来训练更大的模型,并在不调整超参数的情况下扩展性能。为了证明GPipe的有效性,团队在谷歌Cloud TPUv2s上训练了一个模型参数为5.57亿个,输入图像大小为480 x 480的AmoebaNet-B。该模型在多个流行数据集上表现良好,包括将单作物ImageNet的准确率提高到84.3%、CIFAR-10准确率提高到99%、CIFAR-100准确率提高到91.3%。核心GPipe库是在Lingvo框架下开源的。
从小批量到微批量
有两种标准方法可以加速中等大小的DNN模型。数据并行方法使用更多的机器并将输入数据分开。另一种方法是将模型移动到加速器,例如GPU或TPU,它们具有加速模型训练的特殊硬件。但是,加速器的内存有限,与主机的通信带宽有限。
因此,通过将模型划分为分区并将不同的分区分配给不同的加速器,需要模型并行性来在加速器上训练更大的DNN模型。但是由于DNN的顺序性,这种策略可能导致在计算期间只有一个加速器处于活动状态,未充分利用加速器计算能力。
为了实现跨多个加速器的高效训练,GPipe将模型划分为不同的加速器,并自动将一小批训练示例拆分为更小的微批量。通过在微批量中管理执行,加速器可以并行运行。此外,梯度一直在微批次中累积,因此分区数量不会影响模型质量。
最大化内存和效率
GPipe最大化了模型参数的内存分配。团队在云TPUv2上进行了实验,每个TPUv2都有8个加速器核心和64 GB内存(每个加速器8 GB)。如果没有GPipe,由于内存限制,单个加速器可以训练多达8200万个模型参数。
由于在反向传播和批量分割中重新计算,GPipe将中间激活内存从6.26 GB减少到3.46GB,在单个加速器上实现了3.18亿个参数。此外,通过管道并行性,最大模型大小与分区数成正比,如预期的一样。通过GPipe,AmoebaNet能够在云TPUv2的8个加速器上集成18亿个参数,比没有GPipe的情况下多25倍。
为了测试效率,测量了GPipe对AmoebaNet-D模型吞吐量的影响。由于训练需要至少两个加速器来适应模型尺寸,团队测量了具有两个分区但没有管道并行化的简单情况下的加速。
在训练中观察到几乎线性的加速,与具有两个分区的简单方法相比,将模型分布四倍于加速器实现了3.5倍的加速。虽然论文中的所有实验都使用了云TPUv2,但我们看到当前可用的云TPUv3具有更好的性能,每个TPUv3都有16个加速器核心和256 GB(每个加速器16 GB)。GPipe在1024个标记句上启用了80亿个参数转换器语言模型,当将模型分布在所有16个加速器上时,速度提高了11倍。
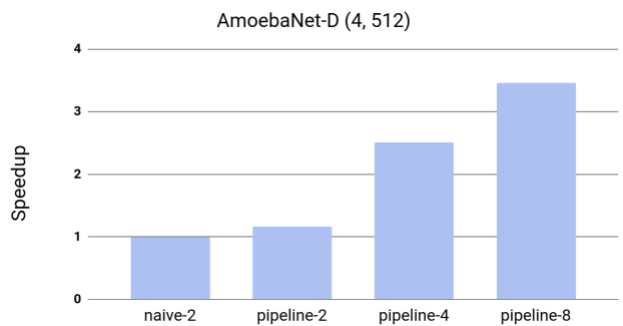
使用GPipe加速AmoebaNet-D。这种模型不适合一个加速器。基线naive-2是将模型拆分为两个分区时本机分区方法的性能。Pipeline-k指的是GPipe的性能,它将模型分成带有k个加速器的k个分区。
GPipe还可以通过使用更多加速器来扩展训练,而无需更改超参数。因此,它可以与数据并行性相结合,以互补的方式使用更多的加速器来扩展神经网络训练。
测试准确度
团队使用GPipe来验证一个假设,即扩展现有的神经网络可以获得更好的模型质量。团队在ImageNet ILSVRC-2012数据集上训练了一个AmoebaNet-B,其模型参数为5.57亿,输入图像尺寸为480 x 480。该网络分为4个分区,并对模型和数据应用并行训练流程。
这个巨大的模型在没有任何外部数据的情况下达到了最先进的84.3% top-1 / 97% top-5验证准确率。大型神经网络不仅适用于ImageNet等数据集,还通过迁移学习与其他数据集相关。更好的ImageNet模型可以更好地传输。此外,在CIFAR10和CIFAR100数据集上进行了迁移学习实验,模型将最佳的CIFAR-10准确率提高到99%,将CIFAR-100提高到91.3%。
结论
许多实际机器学习应用(如自动驾驶和医学成像)的持续发展和成功,取决于尽可能高的准确率。由于这通常需要构建更大,更复杂的模型,谷歌为更广泛的研究社区提供GPipe,并希望它是有效训练大规模DNN的基础设施。
论文:
arxiv.org/pdf/1811.06965.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消