











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI发布大型多智能体游戏环境Nueral MMO
2019年03月05日 由 老张 发表
673126
0
 OpenAI发布了Nueral MMO,一个为强化学习智能体打造的大型多智能体游戏环境。平台支持在一个持久且开放的任务中使用大量可变数量的智能体。包含许多智能体和物种可以带来更好的探索,不同的利基形成和更高的整体能力。
OpenAI发布了Nueral MMO,一个为强化学习智能体打造的大型多智能体游戏环境。平台支持在一个持久且开放的任务中使用大量可变数量的智能体。包含许多智能体和物种可以带来更好的探索,不同的利基形成和更高的整体能力。近年来,多智能体设置已经成为深入强化学习研究的有效平台。尽管取得了这些进展,但多智能体强化学习仍存在两个主要挑战。
我们需要创建具有高度复杂性上限的开放式任务:当前环境要么复杂但过于狭窄,要么开放但过于简单。持久性和大总体规模等属性是关键,但是我们还需要更多的基准环境来量化存在大总体规模和持久性的学习进度。大型多人在线游戏(MMO)的游戏类型模拟了一个大型生态系统,该系统由数量不等的玩家在持久且广泛的环境中进行竞争。
为了应对这些挑战,团队构建了Nueral MMO以满足以下标准:
- 持久性:智能体在没有环境重置的情况下在其他学习智能体存在的情况下学习。策略必须考虑长时间的视野,并适应其他智能体行为的潜在快速变化。
- 规模:环境支持大量且可变数量的实体。实验考虑了100个并行服务器中,每个服务器128个并行智能体的长达100M的生命周期。
- 效率:进入计算障碍很低。可以在单个桌面CPU上训练有效的策略。
- 扩展:与现有MMO类似,新的Nueral MMO旨在更新新内容。目前的核心功能包括基于tile地形的程序生成,食物和水觅食系统以及战略战斗系统。未来有机会进行开源驱动的扩展。
环境
玩家(智能体)可以加入任何可用的服务器(环境),每个都包含一个可配置大小的自动生成的基于图块的游戏地图。一些瓷砖,例如食用森林tile和草tile,是可穿过的。其他的,如水和实心石,则不能穿过。智能体在环境边缘的随机位置产生。它们必须获得食物和水,并避免与其他智能体的战斗,以维持健康。踩在森林tile上或水tile旁边分别重新填充一部分智能体的食物或水供应。然而,森林的食物供应有限,随着时间的推移会缓慢再生。这意味着智能体必须竞争,同时定期从无限的水砖块中补充水源。玩家使用三种战斗风格参与战斗,表示近战,远程和法师。
- 输入:智能体观察以其当前位置为中心的方形裁剪。这包括tile地形类型和占用智能体的选择属性(健康,食物,水和位置)。
- 输出:智能体为下一场比赛的时间步长输出行为选项。行为包括一次移动和一个攻击。
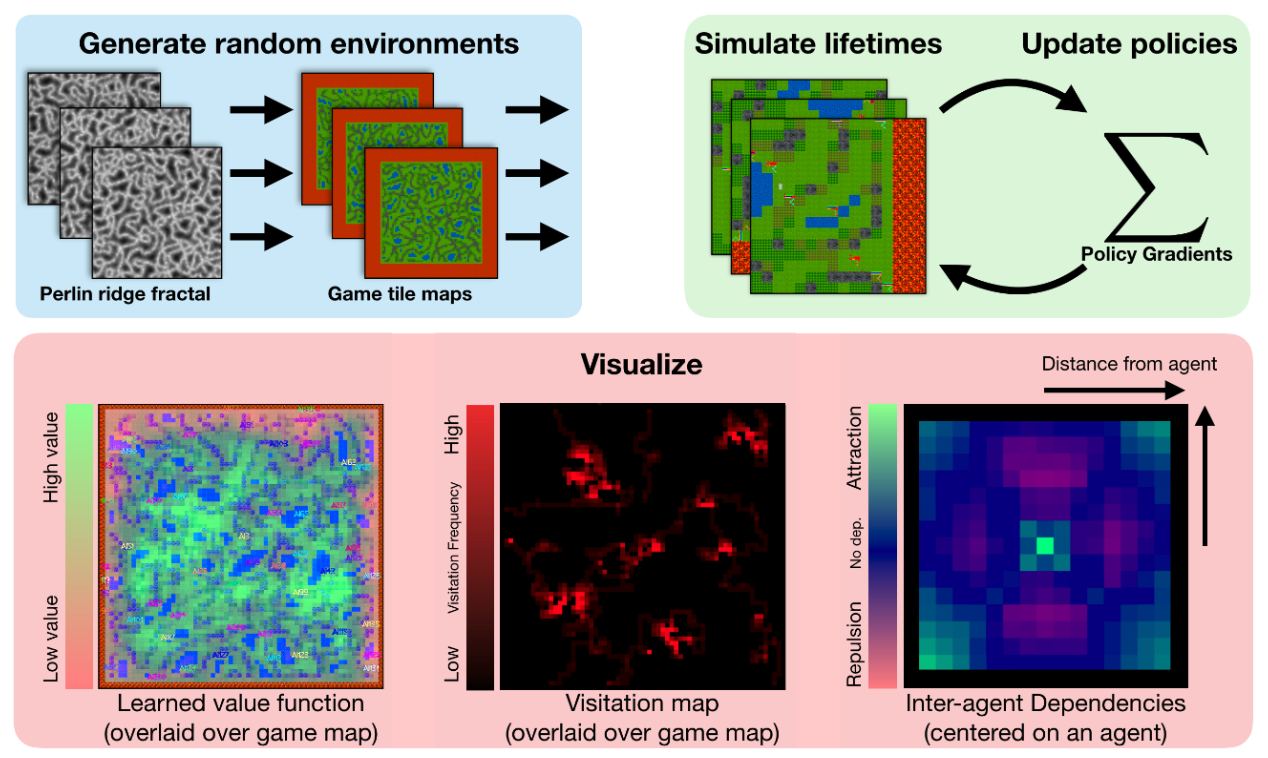
平台提供了一个过程化的环境生成器和可视化工具,用于实现值函数、映射访问分布和学习策略的智能体依赖性。基线使用超过100个世界的策略梯度进行训练。
模型
作为一个简单的基线,我们使用普通策略梯度训练一个小型,完全连接的架构,其中值函数基线和奖励折扣作为唯一的增强功能。智能体不是为了实现特定目标而获得奖励,而是仅针对其生命周期(轨迹长度)进行优化:它们在其生命周期的每个tick上获得奖励1。我们通过计算所有玩家的最大值来将可变长度观测值(例如周围玩家列表)转换为单个长度向量(OpenAI Five也使用了这个技巧)。源版本包括完整分布式训练实现,它基于PyTorch和Ray。
评估结果
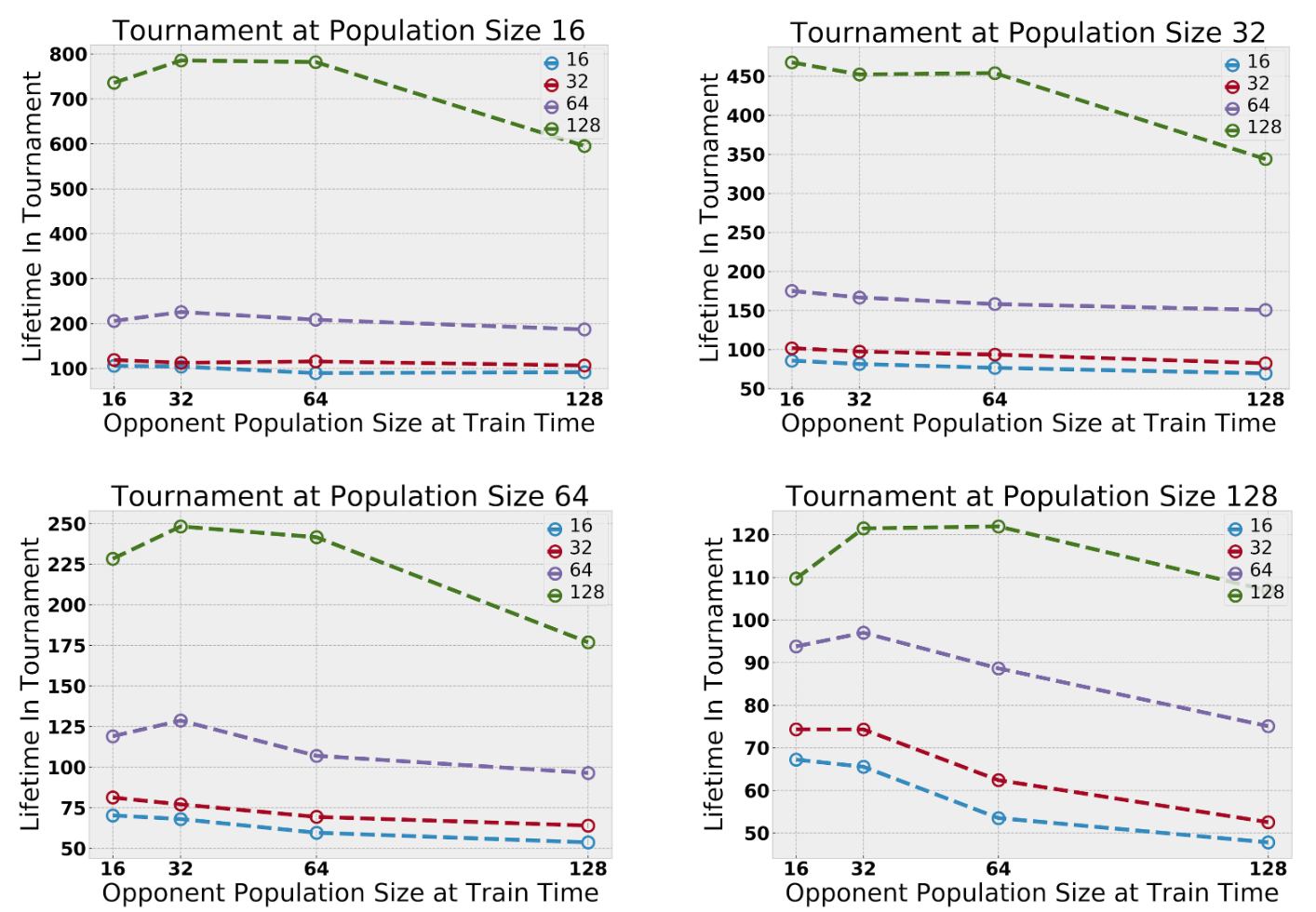
训练时间的最大规模在(16、32、64、128)之间变化。为了提高效率,策略由16个智能体共享。在测试时,我们将在实验对中学习的人群合并,并以固定的人口规模评估生命周期。我们仅通过觅食进行评估,因为战斗策略更难以直接比较。在较大群体中接受过训练的智能体表现更好。
智能体的策略统一来自多个群体,不同群体中的智能体共享架构,但只有相同群体中的智能体共享权重。初步实验表明,智能体能力随着多智能体交互的增加而扩展。增加并发玩家的最大数量可以放大探索;增加种群数量会扩大生态位形成,也就是说,种群在地图不同部分扩散和觅食的趋势。
服务器合并锦标赛:多智能体扩大了竞争力
MMO之间没有标准程序来评估跨多个服务器的相对玩家能力。但是,MMO服务器有时会进行合并,其中来自多个服务器的播放器基站放置在单个服务器中。通过合并在不同服务器中训练的玩家基础来实施“锦标赛”风格评估。这允许直接比较在不同实验设置中学习的策略。团队改变了测试时间范围,发现在较大设置下训练的智能体一直优于在较小环境中训练的智能体。
群体规模的增加扩大了探索
群体规模扩大了探索:智能体分散以避免竞争。最后几帧显示学习值函数叠加。
在自然界中,动物之间的竞争可以激励它们扩散以避免冲突。地图覆盖范围随着并行智能体数量的增加而增加。智能体学会探索只是因为其他智能体的存在提供了这样做的自然动机。
物种数量的增加扩大了利基形成
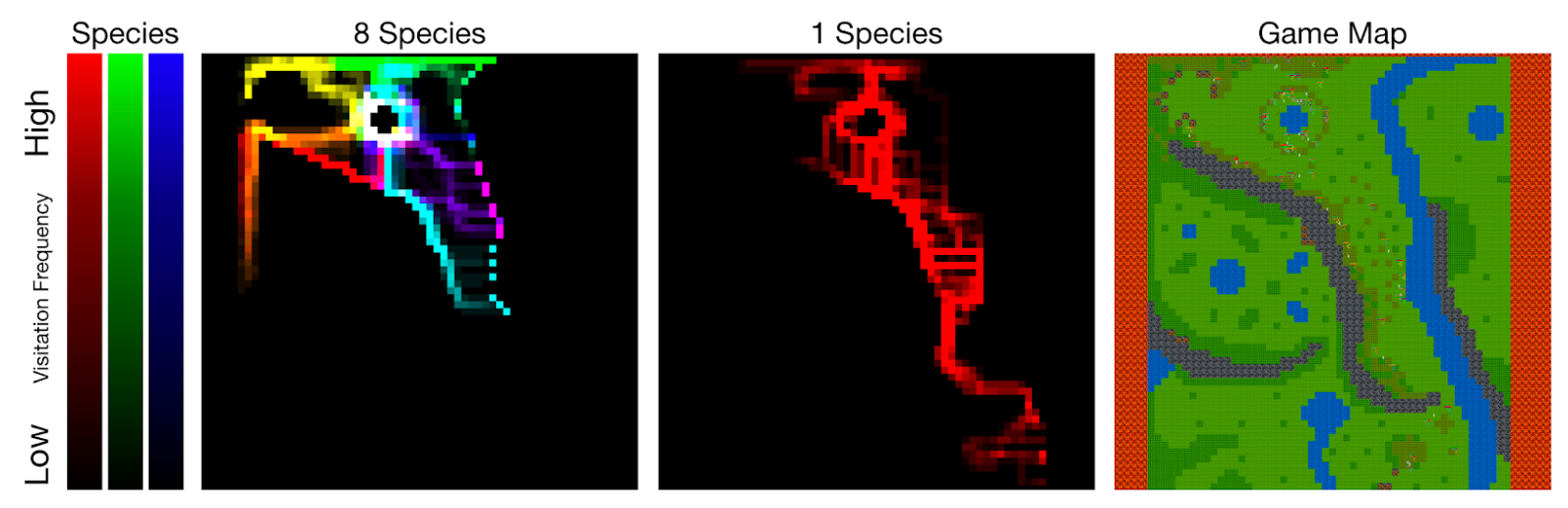
物种数量(种群数量)放大了利基形成。探视地图覆盖了游戏地图,不同的颜色对应不同的物种。训练单一种群倾向于产生单一的深度探索路径。训练八个种群导致许多较浅的路径:种群扩散以避免物种之间的竞争。
鉴于环境足够大且资源丰富,不同的智能体种群在地图上分散开,以避免随着人口的增加与其他人竞争。由于实体不能超越其本国人口的其他智能体(即与他们共享权重的智能体),它们倾向于寻找地图上包含足够资源来维持其人口的区域。在DeepMind的并行多智能体研究中也独立地观察到类似的效果。
其他见解
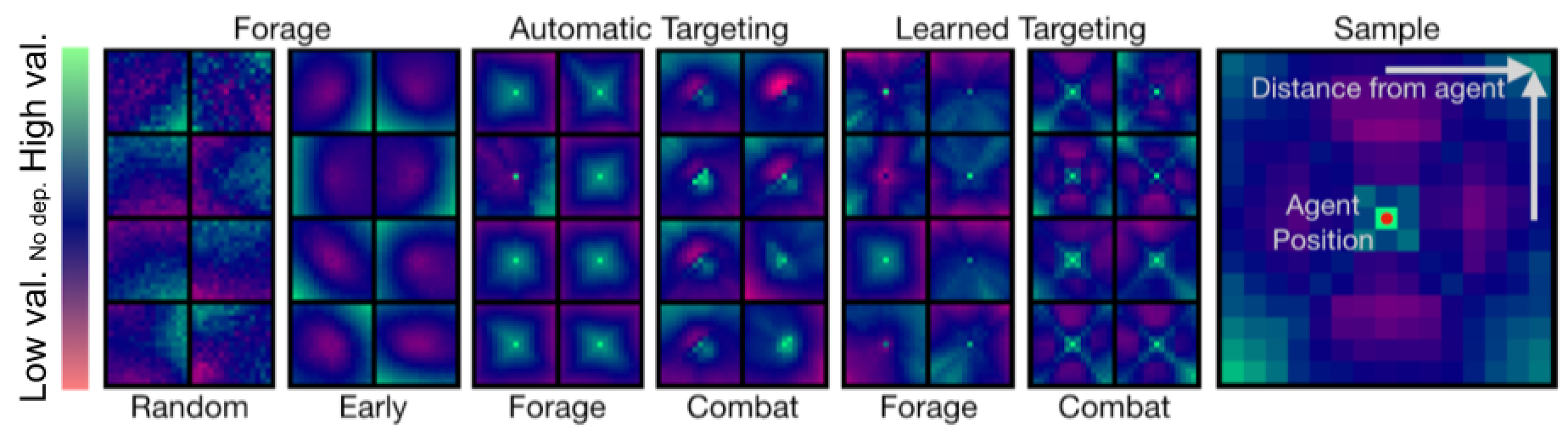
每个方形图显示位于中心的智能体对其周围智能体的存在的响应。在初始化和训练早期展示了觅食地图,额外的依赖图对应于不同的觅食和战斗形式。
团队通过将智能体固定在假设的地图裁剪的中心来可视化智能体-智能体依赖关系。对于该智能体可见的每个位置,在该位置有第二个智能体时,将显示值函数。团队发现智能体商在觅食和战斗环境中学习依赖于其他智能体的策略。智能体学习避让地图,仅在几分钟的训练后就能更有效地开始觅食。当智能体学习环境中的战斗时,它们开始适当地评估有效的接触范围和接近角度。
下一步
Nueral MMO解决了之前基于游戏的环境的两个主要限制,但仍有许多尚未解决。这种Nueral MMO在环境复杂性和群体规模之间择取了中间地带。在设计这个环境时考虑到了开源扩展,作为研究社区的基础。
源码链接
github.com/openai/neural-mmo

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消