











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






智能主题检测与无监督机器学习:识别颜色教程
2017年07月26日 由 yining 发表
464173
0
介绍
人工智能学习通常由两种主要方法组成:监督学习和无监督的学习。监督学习包括使用现有的训练集,这种训练集由预先标记的分类数据列组成。机器学习算法会发现数据的特征和这一列的标签(或输出)之间的关联。通过这种方式,机器学习模型可以预测它从来没有公开过的新的数据列,并且根据它的训练数据返回一个精确的分类。在你已经有了预先分类的数据的情况下,监督学习对于大数据集是非常有用的。
在另一种是无监督的学习。使用这种学习方式,数据不需要在训练集中进行预先标记或预分类,相反,机器学习算法在数据的特征中发现相似的特征和关联,并将它们分组在一起。例如,根据某些特性,两个数据可能会出现类似的情况,因此会被分组到同一个框中(更正式地称为“集群”)。通过将相似的数据聚集在一起,就可以预测出新列之前从未见过的数据,并获得一个准确的分类。不受监督的学习可以很好地适用于某些公共关系形式的数据集。这也得益于不需要事先贴上标签的训练集,而这往往是监督学习中较为困难的部分(通常需要人工标记训练数据)。
 与监督学习的方法相似,无监督学习和聚类可以利用训练数据来形成分组。当监督学习使用预先标记的训练集时,无监督的学习只需要数据。很自然地,预先标记的训练数据用于监督学习不仅费时,而且容易出现人为错误。由于这些原因,不需要(人工/自动化)预先标记的数据集,无监督学习就有潜力在机器学习和人工智能结果方面取得进展。
与监督学习的方法相似,无监督学习和聚类可以利用训练数据来形成分组。当监督学习使用预先标记的训练集时,无监督的学习只需要数据。很自然地,预先标记的训练数据用于监督学习不仅费时,而且容易出现人为错误。由于这些原因,不需要(人工/自动化)预先标记的数据集,无监督学习就有潜力在机器学习和人工智能结果方面取得进展。在本教程中,我们将演示使用无监督学习和集群来智能地识别图上绘制的颜色点,如红色、绿色或蓝色的整体颜色。例如,一个紫色的点可能被认为是红色或蓝色的。我们的无监督学习算法将会学习到像这样的点,作为一个特定的颜色类别。我们还将看到运行K-Means算法来聚类训练数据,识别聚类中心,标记现有数据,并预测新数据的类别。
最后,你将看到如何将非监督分类应用于其他类型的数据,包括在特定类别下对股票和债券ETF基金进行分类。
我们将使用R作为编程语言,当然,你也可以使用JavaScript或你所选择的任何语言作为示例。

在完成本教程之后,你将了解如何将无人监督的机器学习应用到各种主题,包括其他数字数据、行业特定主题、自然语言处理,甚至文本中。
一堆漂亮的颜色
让我们通过生成一组不同的颜色来开始本教程。
我们都知道,颜色由红色、绿色和蓝色组成。通过将这三种颜色组合在一起,我们就可以获得多种颜色。纯红色是由RGB(255、0、0)的红色、绿色、蓝色值确定的,同样地,所有三个纯色值都列在下面。
rgb(255, 0, 0) // Red
rgb(0, 255, 0) // Green
rgb(0, 0, 255) // Blue
不同程度的红色、绿色和蓝色可以通过调整各自的值来表示。例如,rgb(255、0、255)由大量的红色和大量的蓝色组成,这就变成了紫色。
我们到底在分类什么?
到目前为止,我们已经讨论了如何通过组合红色、绿色和蓝色的值来生成颜色。现在我们可以创建颜色了,机器学习算法是如何做到这一点的呢?
回想一下,紫色实际上可以被认为是红色或蓝色。事实上,因为紫色示例的红色和蓝色值都包含最大值rgb(255、0、255),将此颜色标记为红色或蓝色将是正确的。但是,如果我们稍微降低蓝色的值,会怎么样呢?
这种颜色在人眼看来仍然是紫色的。然而,现在它可能更准确地归类为红色。
下面是一些关于颜色如何分组的例子。
rgb(200, 0, 150) // Purple Plum => Red
rgb(50, 199, 135) // Sea Green => Green
rgb(100, 180, 255) // Sky Blue => Blue
有了以上分类的概念,我们就可以利用机器学习来判断它是否能单独识别这些颜色组。虽然我们知道哪些颜色应该是红色的(在rgb()组合中有较高的红色值),所以我们来看看计算机是否可以识别这些颜色组,并精确地将rgb值放置到它们的自然分组中。
考虑颜色
通过在图上查看颜色,可以更容易地(更有趣!)来考虑颜色是如何聚集在一起的。这样,我们可以在图上画出颜色,用各自的红色、绿色和蓝色的值将它们组合在一起,并了解这些颜色是如何自然地形成一层的。
生成随机颜色
首先,让我们看看一些可以随机生成颜色,并在图表上绘制它们的代码。我们需要生成红色、绿色和蓝色的随机值。我们还需要将rgb()值转换为十六进制格式,以便呈现图表上的颜色。幸运的是,R语言很容易将rgb转换为十六进制,只需调用以下代码行:
rgb(255, 100, 175, maxColorValue = 255)
上述代码的结果是 #FF64AF,这是一个与html兼容的颜色,我们可以在图表上绘制。
将RGB转换为数值
除了生成颜色外,我们还需要一种在2D图表上绘制3D颜色的方法。也就是说,我们的颜色由红色,绿色和蓝色的值组成。然而,在图表上绘制需要x y值。因此,我们需要一种将3D红、绿、蓝的数值转换成数值的方法。
我们可以将颜色转换为数值,只需将它们各自的红、绿、蓝的值乘以最大值,并相应的进行索引。
我们可以使用以下公式:
(Red * 256 * 256) +
(Green * 256) +
(Blue)
使用上面的公式,我们得到以下这些示例颜色的值:
rgb(200, 0, 150)
// 13107350
rgb(50, 199, 135)
// 3327879
rgb(100, 180, 255)
// 6599935
现在我们有了生成随机颜色的方法并将它们转换为数值表示,我们可以在图表上画出它们。然后,我们可以用无监督学习来对它们进行分类,并观察计算机如何决定在颜色之间划定界限,有效地将每一种颜色组合成一组红色、绿色或蓝色。注意红色的颜色如何形成一个更大的数值。如果使用y轴来绘制值,那么红色就会被绘制到图表的顶部。同样地,蓝色值的值范围更小,导致它们在图表的底部出现。绿色的颜色在中间。
在图表上绘制颜色
我们可以使用如下所示的R代码来生成一组随机颜色并将它们转换为数值表示。
rgb2Num <- function(data) {
# Maps RGB colors to a single value.
result <- sapply(1:nrow(data), function(row) {
color <- data[row,]
(color$red * 256 * 256) + (color$green * 256) + color$blue
})
result
}
generateColors <- function(n) {
# Generate a set of random colors.
colors <- as.data.frame(t(sapply(1:n, function(i) {
parts <- sample(0:255, 3)
c(red = parts[1], green = parts[2], blue = parts[3], hex = rgb(parts[1], parts[2], parts[3], maxColorValue = 255))
})), stringsAsFactors = F)
# Convert to numeric values.
colors$red <- as.numeric(colors$red)
colors$green <- as.numeric(colors$green)
colors$blue <- as.numeric(colors$blue)
# Map each color to an x/y-coordinate for easy plotting.
colors$x <- 1:nrow(colors)
colors$y <- rgb2Num(colors)
colors
}上面的代码只生成每个红色、绿色和蓝色值中0-255的随机数字。然后,它将为每种颜色生成html兼容的颜色的十六进制值,并使用前面描述的简单公式计算y轴值。对于x轴,我们只需要使用颜色的索引(1-1000,对于1000种生成的颜色)。
下面是训练数据的一个例子,它是通过运行上面的代码生成的。
> generateColors(10)
red green blue hex x y
1 186 160 122 #BAA07A 1 12230778
2 40 2 114 #280272 2 2622066
3 126 99 118 #7E6376 3 8282998
4 182 14 90 #B60E5A 4 11931226
5 205 213 60 #CDD53C 5 13489468
6 90 218 216 #5ADAD8 6 5954264
7 75 37 178 #4B25B2 7 4924850
8 26 8 253 #1A08FD 8 1706237
9 8 86 232 #0856E8 9 546536
10 158 73 187 #9E49BB 10 10373563
你可以看到,我们现在可以通过使用红色、绿色和蓝色值生成的x、y值来轻松地将这些数据绘制到图表上。
美丽的颜色
下面是根据它们各自的值绘制图表,随机生成的1000种颜色。

图表中显示了1000个随机的颜色,由红色、绿色和蓝色的值组成。
正如你在上面的图片中所看到的,蓝色的颜色主要是在底部,然后是绿色的颜色。注意绿色的颜色如何融入到蓝色和红色中,它们在每个边界移动的时候都使用不同程度的橙色和蓝绿色。在绿色的和红色的开始之间,很难画出一条清晰的分界线。同样地,蓝色和绿色的开始和结束也很难确定。这种类型的分类是机器学习和人工智能算法的真正优势。
由于机器学习使用数据中的数值特性来形成关联和分类,因此它可以确定一组边界,以便将颜色分类到它们各自的分组或聚类中。
更少的颜色与更多的机器学习
用我们的分组公式绘制1000种颜色肯定会产生美丽的图像。但是,让我们考虑一组更小的只有100种颜色的数据集。这将使在红色、绿色和蓝色集群中查看数据及其最终分类变得更加容易。
下面是我们的训练数据,由100个随机生成的颜色组成,根据它们各自的值绘制图表。
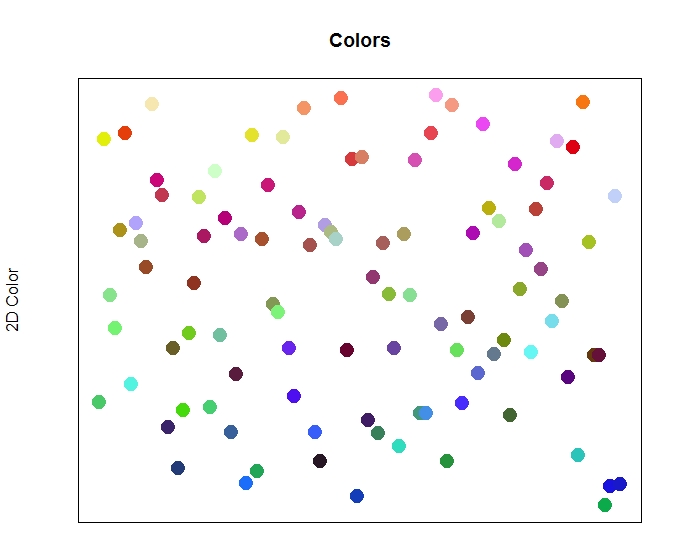
图表中显示了100个随机的颜色,由红色、绿色和蓝色的值组成。
上面的100种颜色和1000种颜色没有什么不同。请注意,蓝色的点在图的底部是如何下降的,中间是绿色和黄色,红色是指向顶部的点。
让我们看看如何根据颜色对每个点进行分类和标注来应用无监督的机器学习算法。
使颜色聚集成组
将数据聚集到组中最常用的算法是K-Means算法。这种聚类算法将数据分组到k个集群中,基于每个数据点的特性与彼此之间的相似程度。我们可以将K-Means聚类算法应用到颜色点上,根据它们各自的红、绿、蓝颜色来组合它们。K-Means算法首先在数据中设置随机的中心点。然后将最接近每个中心的所有点集中到一个单独的集群中。然后将每个集群的中心转移到相关点的中心。最后,我们将所有的点重新分配到最接近的中心,直到每个集群的中心不再发生变化(或者变化小于某个阈值),然后重复这个过程。
这时,无人监督的训练就完成了。
它可以帮助查看K-Means算法的可视化,从而更好地理解这些步骤是如何工作的。
K-Means聚类
下面显示了K-Means无监督学习算法步骤的完整清单。
1.确定集群的数量(即K值)。
对于选择集群的数量,一个经验法则是将数据点的数量除以一半。下面给出了一个示例。
2.随机初始化质心(即每个集群的中心)。
3.将数据中的每个点分配给集群,并将其与最接近的中心放在一起。
4. 将每个集群的质心转移到分配给它的所有点的平均值(中心)。
5重复步骤3-5,直到质心停止移动,或者点停止交换集群,或者到达一个给定的阈值。
下面显示了用于确定集群的质心的示例代码。
K = ~~(Math.sqrt(points.length * 0.5));
计算质心
让我们把K-Means算法应用到颜色数据点上,看看集群中心的位置在哪里。通常情况下,你会尝试猜测适当数量的集群来使用,比如使用上面提到的算法。然而,由于我们知道我们要为数据点寻找红色、绿色或蓝色的分类,为了这3个集群组,我们可以将K值定为3。
我们可以在颜色数据点的集合上运行K-means算法,代码如下所示。
# Run kmeans clustering on the data.
fit <- kmeans(train[,1:3], 3, nstart = 20)
train$group <- fit$cluster
在上面的代码中,请注意,我们只选择数据中的前3列。这对应于红色列、绿色列和蓝色列,因为这是我们想要进行的3个特性。我们的数据集中的其他列对应在绘制图和绘制颜色的坐标上。
第二行代码简单地设置了集群,在运行算法之后,这些集群的每个数据点都被分配到各自的位置。
完成聚类后,我们可以在质心上查看详细的进程的结果。
K-means clustering with 3 clusters of sizes 24, 33, 43
Cluster means:
red green blue
1 98.16667 64.66667 189.20833
2 164.18182 65.03030 64.72727
3 140.67442 196.58140 132.20930
Clustering vector:
[1] 3 3 3 3 2 2 3 3 3 2 3 2 2 1 2 1 3 3 2 3 2 3 3 3 2 1 2 1 1 3 3 2 2 3 3 3 1 1 2 3 2 1 2 3 3
[46] 3 2 2 2 1 2 1 2 3 2 3 1 3 3 3 1 3 1 2 3 1 3 3 3 1 2 1 1 1 2 1 3 2 2 1 3 1 3 2 2 2 3 3 3 1
[91] 2 3 2 3 2 2 3 1 3 1
Within cluster sum of squares by cluster:
[1] 182410.6 201096.4 443809.0
(between_SS / total_SS = 46.1 %)
注意,我们的算法已经完成了3个集群,大小分别为24、33和43(总计为100个数据点)。它们表示为分配给每个集群的颜色点的数量。因此,24个数据点被分配到第一个集群,33个数据点到第二个集群,最后一个集群是43个数据点。
我们还可以看到每个集群中每个特性的平均值。请记住,每个数据点都有3个特征值(红色、绿色和蓝色之间的值为0-255),我们已经对3个集群进行了训练。因此,每个质心也将有一个红色、绿色和蓝色的值,对应于分配给它们的集群的相关数据点的平均值。当我们在图上画出质心时,这个看起来会更直观。
在这一点上,我们在数据上有3个受过训练的集群。我们所有的数据点都被分配到一个集群中。然而,集群实际上并没有一个“名称”。
我们不能叫第一个集群为“我们的红色组”,因为我们还不知道已经分配给它的数据类型是什么样的(但实际上,我们可以窥视质心的平均值,猜测每个集群的名称;例如,第一个集群平均值rgb(98, 64, 189)这是紫色的颜色或者也可以被认为是蓝色的;同样的第二个集群是 rgb(164, 65, 64)这是红色的;最后一个集群是rgb(140, 196, 132)这是绿色的)。
让我们在图上画出每个群集的质心,就在颜色点上。这将让我们了解每个集群中心的位置,并为我们提供了一种正确方式,从而对集群进行命名。
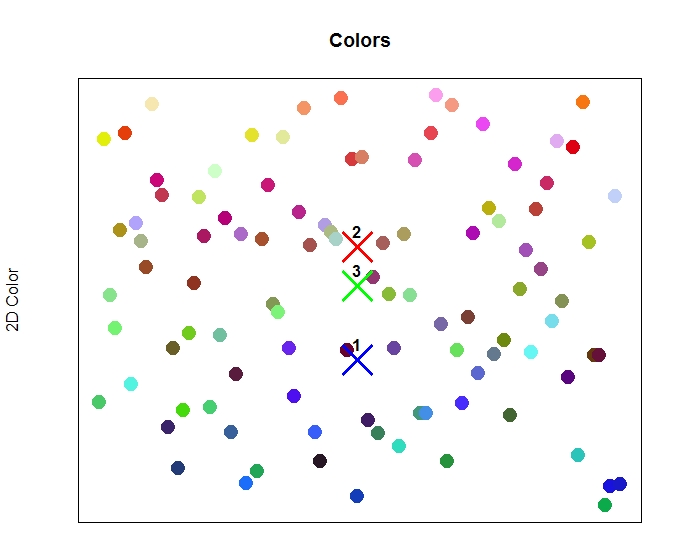
集群中心标识在它们各自的位置显示在图中颜色。
在上图中,我们在颜色数据点上绘制了3个经过训练的集群的中心。
正如我们从集群输出结果中所预测的那样,集群1实际上位于图底部的蓝色范围内。集群2在图上是最高的,对应红色值。集群3位于中间,对应绿色值。此时,我们可以将集群命名为以下内容:
Cluster 1 - "Blue Group"
Cluster 2 - "Red Group"
Cluster 3 - "Green Group"
将颜色分类为一个集群
让我们看一下每个颜色数据点,看看它们被分配给哪个集群比较合适。回想一下,在训练之后,我们设置了每个数据点分配的集群号。通过这种方式,我们的训练集现在有了一个额外的列,包含了分配的集群号。使用这个数据段,我们可以在图上绘制每个数据点的集群,如下所示。
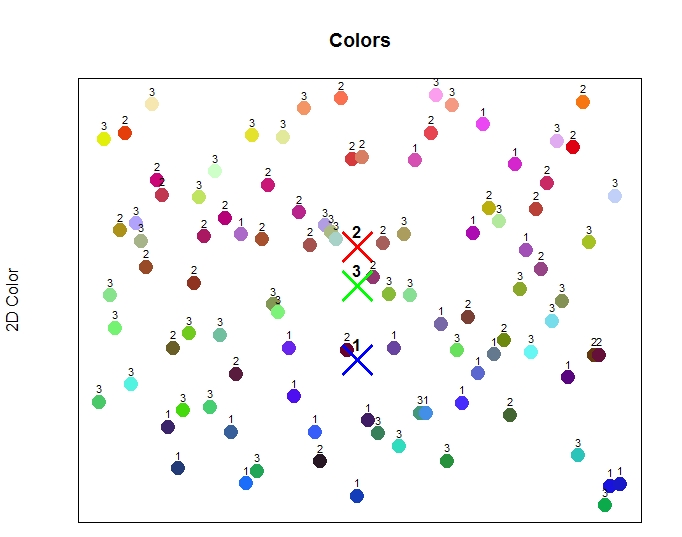
在将非监督学习应用到数据集之后,颜色被标记为已分配的集群。
上面的图像将每个数据点与指定的集群一起标记。我们已经在图上绘制了集群中心,但现在我们也展示了每个点的实际赋值。
请注意,底部的大多数蓝色点被分配给集群1(“蓝色组”)。在图的底部也有几个点被分配给集群3(“绿色组”)。记住,我们要根据一个简单的数学公式,把原始的红,绿,和蓝色的值转换成数值。但是,集群的运作方式不同,通过计算平均值到每个集群的中心。
例如,查看图表底部的点,它们被标记为3(“绿色组”)。它们的颜色从绿色、蓝色到青色,再到蓝绿色,所有的颜色都包括绿色和蓝色。在蓝色或绿色的组中对这些点进行分类是有意义的。
同样地,在图的顶部有一些点没有被分配到集群2(“红色组”),而是被分配到集群1或3。例如,分配给集群3的一些点是黄色的。它们被绘制在图表的顶部,因为它们的数值来自于我们的简单公式,但是它们被分组到“绿色”集群中,因为它们的rgb值仍然在训练的“绿色”组的范围内。毕竟,黄色就在绿色的旁边。
如果我们在指定的集群中直接绘制每一种颜色,那么在每个颜色的坐标和指定的颜色的位置上的差异就会变得更加明显。这将允许我们根据所分配的集群来查看每一种颜色,并绘制在一个单线上。
将颜色分组到它们的集群中
让我们看看哪个颜色点被分配到哪个更直观的地方。根据我们对红、绿、蓝的简单数值计算,我们可以根据所指定的集群来绘制数据点,而不是根据y轴的简单数值计算来绘制数据点。我们将x轴沿着一条直线来绘制每个点,并将其指定的集群用于y轴。
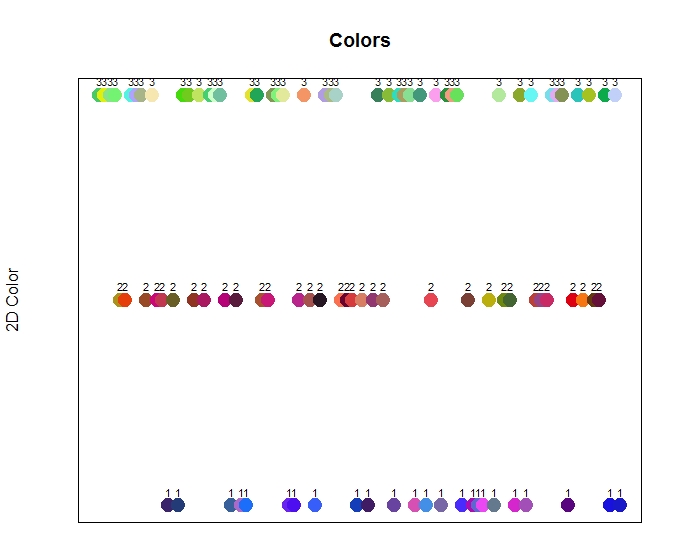
这个图表显示了被分配的集群分组的颜色,每个集群都表示在y轴上。更明显的展示了这些颜色是如何根据红、绿、蓝的颜色来聚类的。
上图显示了在训练过程中,颜色是如何组合在一起的。当然,所有的蓝色值都被分组到集群1(“蓝色组”)中。当我们使用简单的y轴的数值计算时,这包括了紫色和粉红色的颜色(之前可能已经在图的顶部画过了。[在红色区域中])。
同样地,红色和黄色是在集群2(“红色组”)中绘制的。包括棕色,甚至一些黄绿色。最后,绿色,淡蓝色,甚至一些更接近绿色的浅粉色,在第三组(绿色组)中被绘制出来。
在新数据上预测
既然我们已经用K-means聚类训练了无监督机器学习算法,我们就有了一种将颜色数据点标记为特定集群的方法。我们将每个集群分别标记为“蓝色组”、“红色组”和“绿色组”。
现在最大的测试是预测一个算法以前从未见过的新的数据点的分配组。它能预测出颜色点的正确颜色组吗?
让我们生成三个新的随机颜色点。然后,我们将要求模型对每个集群进行分类。
test <- generateColors(3)
上面的代码生成3个新颜色,如下所示。
red green blue hex x y
1 232 17 252 #E811FC 1 15208956
2 86 109 216 #566DD8 2 5664216
3 67 219 216 #43DBD8 3 4447192
使用我们已经训练过的模型(例如:计算出的质心),我们可以确定每个点将被分配到哪个集群。在R语言中,我们可以使用kcaa库来预测已经经过训练的k-means算法,如下所示。
# Cast the k-means model to be of type kcaa, so we can use the predict method.
fit2 <- as.kcca(fit, data=train[,1:3])
# Predict the assigned color by mapping the color to a cluster.
group <- predict(model, newdata=data[,1:3])
# Assign the label of the cluster.
data$label <- sapply(1:nrow(data), function(row) {
centroids[centroids$group == data[row, 'group'], ]$label
})
在上面的代码中,我们只是简单地将k-means模型转换为kcaa类型,这样我们就可以调用预测方法。在转型之后,我们可以调用预测,通过我们已经训练过的模型,以及数据点来预测。在预测了集群号之后,我们可以将给定的集群名称分配给每个数据点,以便在预测的数据上进行更易于理解的集群任务。
我们得到以下数据的结果。
red green blue hex x y group label
1 241 52 11 #F1340B 1 15807499 2 red
2 80 187 139 #50BB8B 2 5290891 3 green
3 34 15 194 #220FC2 3 2232258 1 blue
注意,第一个点被分配到集群2(“红色组”)。这很容易理解,因为红色值是最大的值。第二个点被分配给集群3(“绿色组”),并且确定的是,它的绿色值是最大的值。最后一个点被分配给集群1(“蓝色组”),再一次因为它的蓝色值是最大的值。
 在测试集中,每一种新颜色都可以预测一个类别主题。
在测试集中,每一种新颜色都可以预测一个类别主题。
上面的图像显示了三个新的数据点的预测的集群组。这些随机生成的颜色(红、绿、蓝)分别被分配到红、绿、蓝两组。
结语
聚类颜色是一种简洁的的方法,可以直观地理解人工智能中无监督的机器学习是如何工作的。
然而,我们可以超越这个主题,将无监督的学习转向更多真实的场景中。
此文为编译作品,作者:KORY BECKER,原网站:http://www.primaryobjects.com/2017/07/24/intelligent-topic-detection-with-unsupervised-learning/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消