











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌发布TensorFlow 2.0 alpha版本,更简洁易用
2019年03月07日 由 张江 发表
358193
0
 随着TensorFlow 2.0 alpha版本的发布,世界上最流行的机器学习开源框架得到了重大升级。该框架由谷歌Brain团队创建,开发人员、研究人员和企业使用它来训练和部署对数据进行推断的机器学习模型。完整版本预计将于2019年第二季度发布。
随着TensorFlow 2.0 alpha版本的发布,世界上最流行的机器学习开源框架得到了重大升级。该框架由谷歌Brain团队创建,开发人员、研究人员和企业使用它来训练和部署对数据进行推断的机器学习模型。完整版本预计将于2019年第二季度发布。今天谷歌在TensorFlow开发者峰会上宣布了这一消息。TensorFlow工程总监Rajat Monga表示,自TensorFlow于2015年11月推出以来,该框架已被下载超过4100万次,目前全球已有1800多名贡献者。
根据2018年的Octoverse报告,TensorFlow在GitHub上拥有最多的开源项目贡献者。
TensorFlow 2.0将依赖tf.keras作为其核心的高级API来简化框架的使用。与Keras深度学习库的集成始于2017年2月TensorFlow 1.0的发布。许多冗余的API(例如Slim和Layers API)将被淘汰。
他表示,“在2.0版本中,我们决定坚持Keras,Keras是前沿和中心,而所有其他的API都消失了。”
TensorFlow 2.0还将改进用于机器学习实验和研究的runtime for Eager Execution平台。Eager Execution是去年首次引入的。TensorFlow 2.0是“Eager-first”的,这意味着默认情况下它使用了Eager,因此当调用ops时,它们会立即运行。
“我们过去只使用图表,大约一年前,除了图表,我们还推出了Eager execution。”Monga说,“在2.0版本中,我们把它放在了前端和中心,你可以把这两者结合起来,这给Python带来灵活性和易用性,以及非常好的API。”
TensorFlow Federated用于不同位置的训练模型,带有隐私保证的TensorFlow隐私库,以及用于边缘计算的Coral Board今天也首次亮相。
TensorFlow Lite 1.0
此外,谷歌今天还介绍了适用于移动开发人员的TensorFlow Lite 1.0,它是开发人员在移动和物联网设备上部署AI模型的框架。改进包括在训练期间和之后对更快、更小的模型进行选择性配准和量化。量化导致一些模型的压缩4倍。
Lite从在TensorFlow上训练AI模型开始,然后转换为创建用于在移动设备上操作的Lite模型。Lite于2017年5月在I / O开发者大会上首次推出,并于当年晚些时候在开发人员预览中推出。
TensorFlow Lite团队还分享了其未来的路线图,旨在缩小和加速AI模型的边缘部署,包括模型加速,特别是对于使用神经网络的Android开发人员,以及基于Keras的连接修剪套件和额外的量化增强功能。
其他方面的变化:
- 支持控制流,这对于诸如递归神经网络的模型的操作是必不可少的;
- 使用Lite模型优化CPU性能,可能涉及与其他公司的合作关系;
- 扩展GPU委托操作的覆盖范围并最终确定API以使其普遍可用。
TensorFlow的演进史
自谷歌首次公开TensorFlow 1.0以来已经两年多了,在这段时间里,为了支持AI从业者的工作,已经发生了很多变化。
最近增加的主要数据可能是TensorFlow数据集,这是一组现成的公共研究数据集,于上周发布。大约有30个流行的数据集在发布时可用。
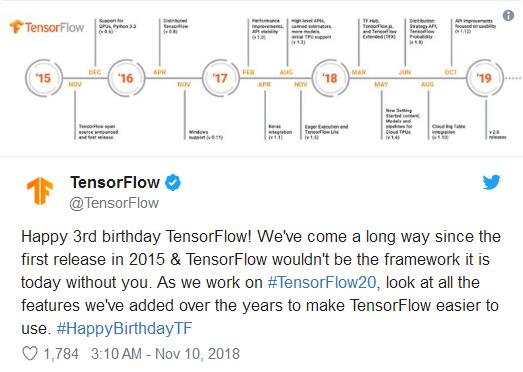
Monga表示自1.0发布以来最重大的变化包括TensorFlow Lite;可重复使用的机器学习模块的中央存储库TensorFlow Hub;研究人员使用的Tensor2Tensor深度学习模型库。为使用机器学习的研究人员提供的TensorFlow概率Python库也是向前迈出的重要一步。
许多建立在TensorFlow之上的库和框架也被引入,比如用于强化学习的智能体和用于生成对抗网络的TFGAN。
谷歌还逐渐开放了对TensorFlow Extended的访问权限,TensorFlow Extended是谷歌内部使用的工具,开发人员可以管理模型,预处理数据,更好地了解训练时模型的变化。
“在过去的一年里,我们已经慢慢地推出了各种各样的东西,现在我们实际上已经发布了整个东西作为一种方式来协调它,让你真正管理整个机器学习管道。”
TensorBoard于2017年9月推出,允许开发人员在训练时观察其AI模型的可视化。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消