











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






K近邻算法KNN的简述
2019年03月10日 由 sunlei 发表
127010
0
什么是KNN
K近邻算法又称KNN,全称是K-Nearest Neighbors算法,它是数据挖掘和机器学习中常用的学习算法,也是机器学习中最简单的分类算法之一。KNN的使用范围很广泛,在样本量足够大的前提条件之下它的准确度非常高。
KNN是一种非参数的懒惰学习算法。其目的是使用一个数据库,其中数据点被分成几个类来预测新样本点的分类。简单举个例子,你搬到了一个新的社区,想和你的邻居成为朋友。你开始与邻居交往了。你决定挑选和你的思维方式,兴趣和爱好相似的邻居。在这里思维方式,兴趣和爱好都是特色。您根据兴趣,爱好和思维相似性决定您的邻居朋友圈。这类似于KNN的工作方式所谓K近邻,就是K个最近的邻居的意思。KNN算法既可以做分类,也可以做回归。
K是什么?
K是用于识别新数据点的类似邻居的数字。
参考我们在新社区中的朋友圈的例子。我们根据共同的思维或爱好选择了3个我们希望成为非常亲密朋友的邻居。在这种情况下,K是3。
KNN使用K最近邻居来决定新数据点所属的位置。此决定基于特征相似性。
我们如何选择K的值?
K的选择对我们从KNN获得的结果产生了巨大影响。
我们可以采用测试集并绘制准确率或F1分数对不同的K值。
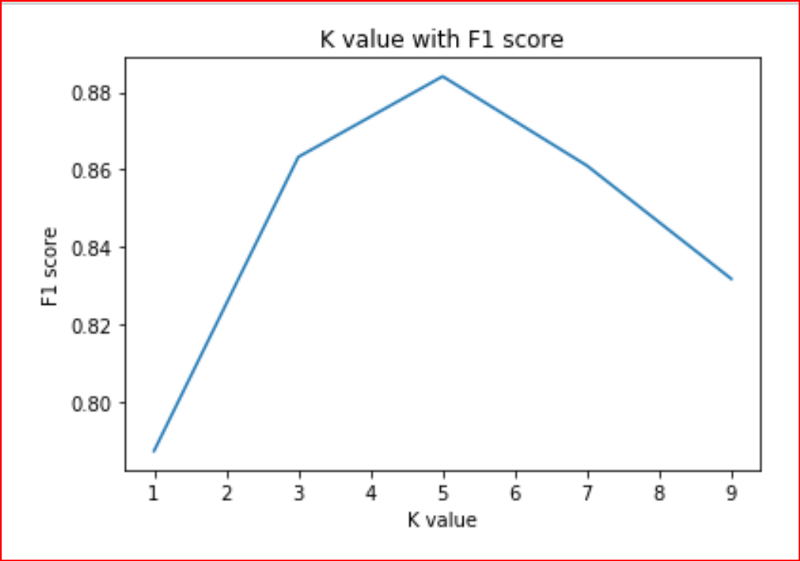
当K = 1时,我们看到测试集的错误率很高。因此,我们可以得出结论,当k = 1时,模型会过度拟合。
对于较高的K值,我们看到F1得分开始下降。当k = 5时,测试集达到最小错误率。这与K-means中使用的弯头方法非常相似。
在测试误差率的K值给出了K的最佳值。
[caption id="attachment_37603" align="aligncenter" width="800"]
 KNN算法原理[/caption]
KNN算法原理[/caption]我们可以使用K折叠交叉验证来评估KNN分类器的准确性。
KNN如何运作?
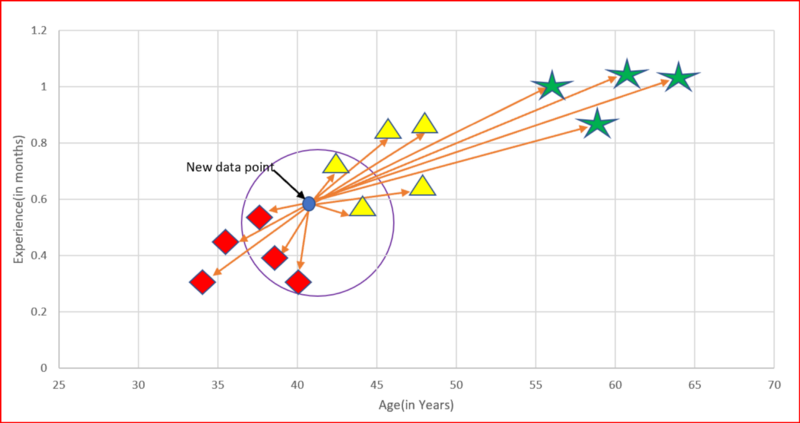
我们在组织中拥有年龄和经验以及薪水。我们想要预测年龄和经验可用的新候选人的工资。
步骤1:为K选择一个值。K应该是一个奇数。
步骤2:找到每个训练数据的新点距离。
步骤3:找到新数据点的K个最近邻居。
步骤4:对于分类,计算k个邻居中每个类别中的数据点的数量。新数据点将属于具有最多邻居的类。
对于回归,新数据点的值将是k个邻居的平均值。
[caption id="attachment_37604" align="alignnone" width="800"]
 KNN算法原理[/caption]
KNN算法原理[/caption]K = 5。我们将平均5个最近邻居的工资来预测新数据点的工资
如何计算距离?
可以使用计算距离
- 欧氏距离
- 曼哈顿距离
- 汉明距离
- 闵可夫斯基距离
欧几里德距离是两点之间的平方距离之和的平方根。它也被称为L2规范。
[caption id="attachment_37605" align="aligncenter" width="800"]
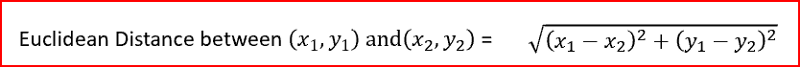 欧几里德距离[/caption]
欧几里德距离[/caption]曼哈顿距离是两点之间差异的绝对值之和。
[caption id="attachment_37606" align="aligncenter" width="765"]
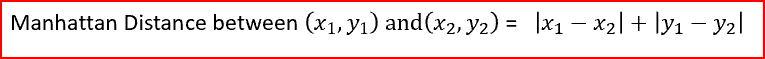 曼哈顿距离[/caption]
曼哈顿距离[/caption]用于分类变量。简单来说,它告诉我们两个分类变量是否相同。
[caption id="attachment_37607" align="aligncenter" width="726"]
 汉明距离[/caption]
汉明距离[/caption]Minkowski距离用于找出两点之间的距离相似性。当p = 1时,它变为曼哈顿距离,当p = 2时,它变为欧几里德距离
[caption id="attachment_37608" align="aligncenter" width="800"]
 闵可夫斯基距离[/caption]
闵可夫斯基距离[/caption]KNN的优点和缺点是什么?
K最近邻居的优点
简单的算法因此易于解释预测
非参数化,因此不对基础数据模式做出假设
用于分类和回归
与其他机器学习算法相比,最近邻居的训练步骤要快得多
K最近邻居的缺点
KNN在计算上是昂贵的,因为它在预测阶段搜索最近邻居的新点
由于KNN必须存储所有数据点,因此存储器要求很高
预测阶段非常昂贵
对异常值敏感,准确性受噪声或无关数据的影响。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消