











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Gboard的全新手写识别AI可以减少40%的错误
2019年03月08日 由 bie管我叫啥 发表
702971
0
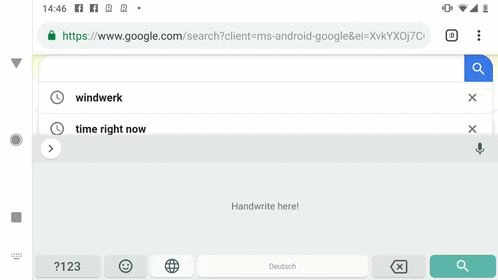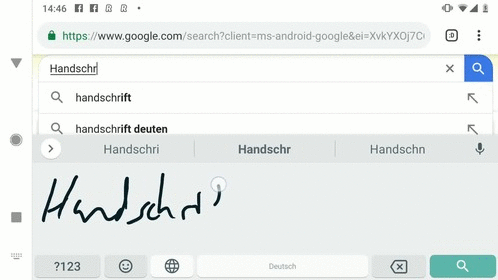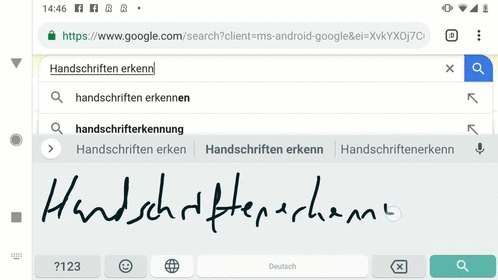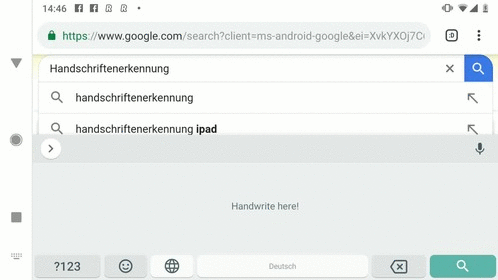
 谷歌在Gboard中改进了手写识别功能,使用更快的AI系统,错误比其原来的机器学习模型少20%到40%。
谷歌在Gboard中改进了手写识别功能,使用更快的AI系统,错误比其原来的机器学习模型少20%到40%。高级软件工程师Sandro Feuz和Pedro Gonnet写道,“机器学习的进步促成了新的模型架构和训练方法,允许修改初始方法且构建一个单一的模型,对整个输入进行操作,我们在今年年初在Gboard为所有基于拉丁语脚本的语言推出了这些新模型。”
大多数手写识别器都使用触点来识别手写的拉丁字符。手写输入被表示为一个笔画序列,这些笔画依次包含时间戳点的序列。Gboard首先对触点坐标进行归一化处理,以保证不同采样率和精度的设备之间的触点坐标保持一致,然后将其转换为计算机图形学中常用的三次贝塞尔曲线参数曲线序列。
Feuz和Gonnet说,这些序列的主要优势在于,它们比输入点的底层序列更紧凑。在这一端,每条曲线都由一个由起点、终点和控制点定义的多项式(变量和系数的表达式)来表示。单词“go”可能包含186个这样的点,代表字母G的四条三次贝塞尔曲线(和两个控制点),字母O由三条曲线组成的序列表示。
这些序列被输入到一个训练有素的递归神经网络中,以识别所写字符,这是一个双向准递归神经网络(QRNN),能够有效并行化的网络,因此具有良好的预测性能。
重要的是,QRNN还保持了权重的数量,即组成网络的数学函数或节点之间的连接强度,这些函数或节点相对较小,减少了文件大小。
那么AI模型如何制作曲线的正面或反面?答案是通过产生列和行的矩阵,其中每列对应于一个输入曲线,并且每行对应于字母表中的字母。网络的输出与基于字符的语言模型组合,该语言模型将奖励奖励到语言中常见的字符序列并且对不常见的序列进行惩罚,并分别将接触点序列转换为与单个曲线对应的较短序列。最后,给定一组曲线序列,基于QRNN的识别器输出字符概率序列。
Gboard的手写识别堆栈在设备上运行,这是团队通过将识别模型(在谷歌的TensorFlow机器学习框架中训练)转换为TensorFlow Lite模型而实现的壮举。与完整的TensorFlow实施相比,这不仅可以降低推理时间,还可以减少Gboard的存储空间。
团队表示,“我们将继续推动改进拉丁语言语言识别器,手写团队已经在努力为Gboard中所有支持的手写语言推出新模型。”

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消