











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Facebook开发基于文本的冒险游戏,研究AI智能体的对话和行为
2019年03月11日 由 明知不问 发表
747362
0
 AI可以编写新闻快讯,并在提示下连贯地重复一些内容,但它能学会驾驭一款基于文本的幻想游戏吗?Facebook AI研究,洛林计算机科学及其应用研究实验室,以及伦敦大学学院的研究人员就此问题展开研究,并发表论文“Learning to Speak and Act in a Fantasy Text Adventure Game”。
AI可以编写新闻快讯,并在提示下连贯地重复一些内容,但它能学会驾驭一款基于文本的幻想游戏吗?Facebook AI研究,洛林计算机科学及其应用研究实验室,以及伦敦大学学院的研究人员就此问题展开研究,并发表论文“Learning to Speak and Act in a Fantasy Text Adventure Game”。研究人员特别研究了基于对话的影响,即两个人之间交流所必需的相互知识、信念和假设的集合对AI智能体理解它们周围的虚拟世界的影响。为此,他们以大规模的众包文本冒险形式建立了一个研究环境LIGHT,在这个环境中,AI系统和人类作为玩家角色进行互动。
论文作者写道,目前的技术水平只使用语言数据的统计规律,对语言所描述的世界没有明确的理解。框架允许从行动和对话中学习,我们希望LIGHT可以让人类与之交流变得有趣,从而在未来能够与我们的模型互动。LIGHT中的所有话语都来源于人类注释者,继承了自然语言的模糊性、共参照等特性,使之成为一个具有挑战性的语言和行为基础学习平台。
人类注释者的任务是制作背景故事(“从前,明亮的白色石头是葬礼建筑的核心”),位置名称(“冰冻苔原”,“云中城市”),角色类别(“挖墓人”),包含描述,个性和所有物品的角色列表(“巫师”,“骑士”,“乡村文员”)。然后研究人员分别将不同的众包对象和随附的描述,以及一系列动作(“获取”,“丢弃”,“放置”,“给予”)和表情(“脸红”,“哭泣”,“皱眉”)分开。
LIGHT现在包括基于一组区域和生物群落(如“乡村”,“森林”和“墓地”)的663个位置的自然语言描述,以及3462个物体和1755个角色。
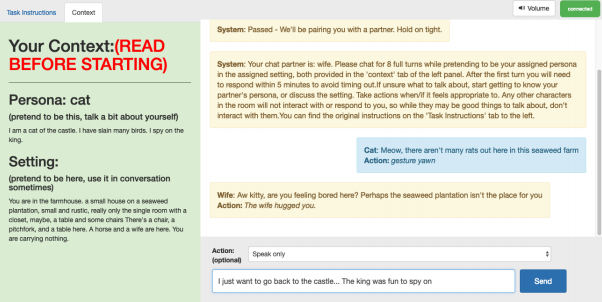
随着游戏世界界限的建立,该团队着手编制角色驱动互动的数据集。他们在一个随机位置有两个由人控制的角色,轮流执行一个行为并说一件事。研究人员记录了10777个关于动作,表情和对话的片段,他们用这些训练了几个AI模型。
使用Facebook ParlAI的PyTorch机器学习框架,研究人员首先设计了一个AI模型,可以根据基础信息(设置,角色,对象)和上下文嵌入为每个句子生成单独的表示,从而为最有希望的候选词打分。
接下来用BERT构建两个系统:bi-ranker,他们将其描述为一个快速而实用的模型;另一个是cross-ranker,一种较慢的模型,允许上下文和响应之间更多的相互关联。最后,他们使用另一组AI模型来编码上下文特性(例如对话,角色和设置)并生成动作。
那么AI玩家表现如何呢?实际上很好,它们擅长依靠过去的对话,并根据游戏世界不断变化的状态来调整预测,基于当地环境细节的对话,如描述、对象和角色,能够让AI控制的智能体更好地预测行为。
研究人员指出,这些模型虽然没有在性能方面超过人类,但是增加更多基础信息(例如过去的行为,角色或设置描述)的实验得到了显着改善。事实上,对于像对话预测这样的任务,即使对话和角色没有变化,AI也能够产生适合给定设置的输出,这表明它们获得了语境化的能力。
研究人员写道:“我们希望这项工作能够使未来的基于语言学习的研究成为可能,并进一步提高智能体对完整世界进行建模的能力,并能够与其他智能体一起完成目标。”
论文:
arxiv.org/pdf/1903.03094.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消