











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用Google的Quickdraw创建MNIST样式数据集
2018年06月01日 由 xiaoshan.xiang 发表
544660
0
对于那些运行深度学习模型的人来说,MNIST是无处不在的。手写数字的数据集有许多用途,从基准测试的算法(在数千篇论文中引用)到可视化,比拿破仑的1812年进军更为普遍。数字如下所示:
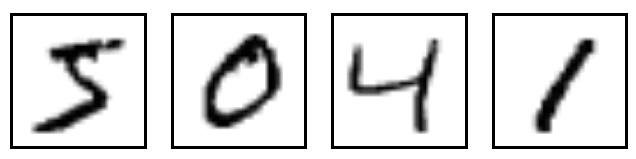
它经久不衰的主要原因是缺乏替代品。在这篇文章中,我想介绍另一种方法,就是Google的QuickDraw数据集。2017年QuickDraw数据集应用于Google的绘图游戏Quick,Draw。该数据集由5000万幅图形组成。图纸如下所示:

我想了解您如何使用这些图纸并创建自己的MNIST数据集。Google使每个图纸变为可用的28x28灰度位图文件,这些可以作为MNIST 28x28灰度位图图像的替代品。并且Google已经将数据集公开。所有数据都位于Google的云端控制台中,但是对于这些图像,您需要使用numpy_bitmaps的这个链接。
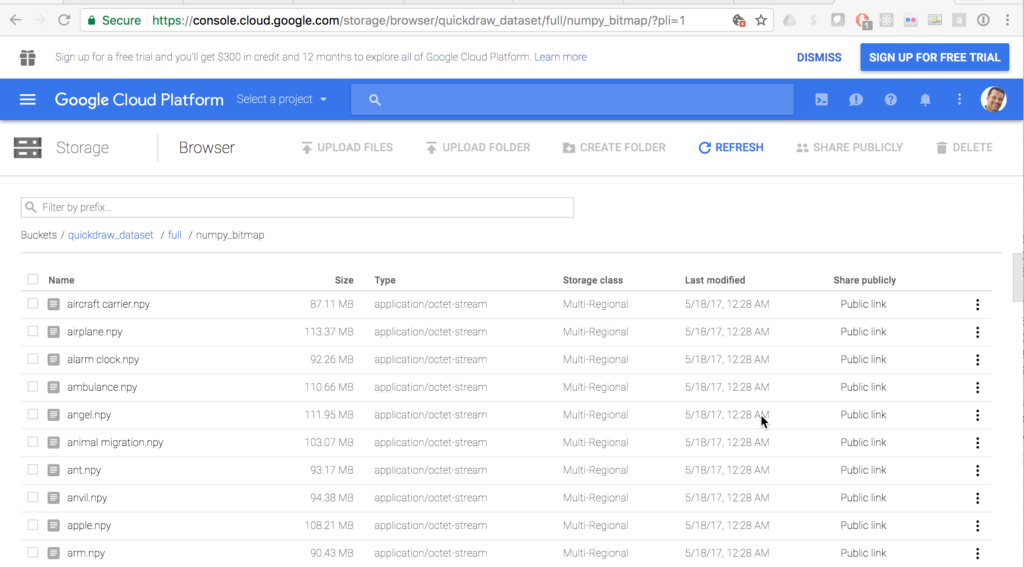
您应该到达一个允许您下载任何类别图像的页面。然后选择类别,我选择眼镜,脸,铅笔和电视机。通过脸这个类别可以知道精细的绘画可能更难学习,您应该选择其他有趣的类别。

接下来的挑战是获得这些.npy文件并使用它们。这是一个简短的python gist ,我用来阅读.npy文件并将它们组合起来创建一个可以用来替代MNIST的含有80,000个图像的数据集。它们以hdf5格式保存,这种格式是跨平台的,经常用于深度学习。
我使用这个数据集代替MNIST。在Keras 教程中,使用Python中的自动编码器进行一些工作。下图显示了顶部的原始图像,并使用自动编码器在底部显示重建的图像。

接下来我使用了一个R语言的变分自编码器的数据集。以下是导入数据的代码片段:
这是使用自定义的quickdraw数据集的可视化的潜在空间。

本文为编译文章,作者Rajiv Shah,原网址为
http://projects.rajivshah.com/blog/2017/07/14/QuickDraw/
它经久不衰的主要原因是缺乏替代品。在这篇文章中,我想介绍另一种方法,就是Google的QuickDraw数据集。2017年QuickDraw数据集应用于Google的绘图游戏Quick,Draw。该数据集由5000万幅图形组成。图纸如下所示:
构建您自己的QuickDraw数据集
我想了解您如何使用这些图纸并创建自己的MNIST数据集。Google使每个图纸变为可用的28x28灰度位图文件,这些可以作为MNIST 28x28灰度位图图像的替代品。并且Google已经将数据集公开。所有数据都位于Google的云端控制台中,但是对于这些图像,您需要使用numpy_bitmaps的这个链接。
您应该到达一个允许您下载任何类别图像的页面。然后选择类别,我选择眼镜,脸,铅笔和电视机。通过脸这个类别可以知道精细的绘画可能更难学习,您应该选择其他有趣的类别。
接下来的挑战是获得这些.npy文件并使用它们。这是一个简短的python gist ,我用来阅读.npy文件并将它们组合起来创建一个可以用来替代MNIST的含有80,000个图像的数据集。它们以hdf5格式保存,这种格式是跨平台的,经常用于深度学习。
用QuickDraw代替MNIST
我使用这个数据集代替MNIST。在Keras 教程中,使用Python中的自动编码器进行一些工作。下图显示了顶部的原始图像,并使用自动编码器在底部显示重建的图像。
接下来我使用了一个R语言的变分自编码器的数据集。以下是导入数据的代码片段:
library(rhdf5)
x_test <- t(h5read("x_test.h5", "name-of-dataset"))
x_train <- t(h5read("x_train.h5", "name-of-dataset"))
y_test <- (h5read("y_test.h5", "name-of-dataset"))
y_train <- (h5read("y_train.h5", "name-of-dataset"))
这是使用自定义的quickdraw数据集的可视化的潜在空间。
本文为编译文章,作者Rajiv Shah,原网址为
http://projects.rajivshah.com/blog/2017/07/14/QuickDraw/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
如何用R语言进行深度学习?








广告


写评论取消
回复取消