











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Facebook为加速AI训练和推理开源一系列硬件平台
2019年03月15日 由 老张 发表
550385
0
 每月为27亿人提供一系列应用和服务并不容易,近年来,Facebook已经从通用硬件转移到了专用加速器,这些加速器可以保证其数据中心的性能,功耗和效率,特别是在AI领域。为此,它宣布了下一代用于AI模型训练的硬件平台Zion,以及针对AI推理优化的定制专用集成电路(ASIC)Kings Canyon,以及视频转码Mount Shasta。
每月为27亿人提供一系列应用和服务并不容易,近年来,Facebook已经从通用硬件转移到了专用加速器,这些加速器可以保证其数据中心的性能,功耗和效率,特别是在AI领域。为此,它宣布了下一代用于AI模型训练的硬件平台Zion,以及针对AI推理优化的定制专用集成电路(ASIC)Kings Canyon,以及视频转码Mount Shasta。Facebook表示,这三个平台将大大加速AI训练和推理。“AI用于各种服务,以帮助人们进行日常互动,并为他们提供独特的个性化体验,在整个Facebook的基础设施中使用AI工作负载,使我们的服务更具相关性,并改善使用我们服务的人们的体验。”
Zion专为处理包括CNN,LSTM和SparseNN在内的神经网络架构的频谱而量身定制,包括三个部分:一个带有八个NUMA CPU插槽的服务器,一个八加速器芯片组,以及Facebook与供应商无关的OCP加速器模块(OAM)。它拥有高内存容量和带宽,这得益于两个高速结构(连接所有CPU的连贯结构,以及连接所有加速器的结构),以及灵活的架构,可以使用机架顶部(TOR)网络交换机在一个机架内扩展到多个服务器。
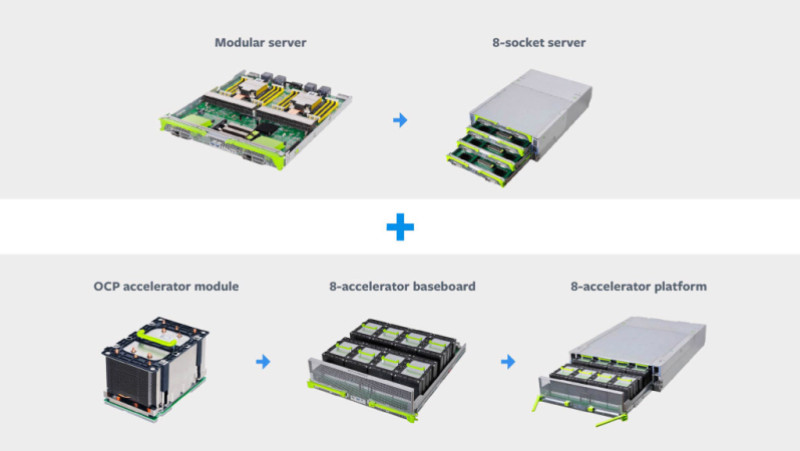
Lee,Rao和Arnold解释道,“由于加速器具有高内存带宽但内存容量低,我们希望通过对模型进行分区来有效地使用可用的聚合内存容量,使得更频繁访问的数据驻留在加速器上,而访问频率较低的数据驻留在带有CPU的DDR内存,所有CPU和加速器的计算和通信都是平衡的,并通过高速和低速互连高效运行。”
至于专为推理任务而设计的Kings Canyon,它分为四个部分:Kings Canyon推理M.2模块,Twin Lakes单插槽服务器,Glacier Point v2载卡和Facebook的Yosemite v2机箱。Facebook表示正在与Esperanto,Habana,英特尔,Marvell和高通公司合作开发支持INT8和高精度FP16工作负载的ASIC芯片。
Kings Canyon中的每台服务器都结合了M.2 Kings Canyon加速器和一个连接Twin Lakes服务器的Glacier Point v2载卡;Kings Canyon模块包括ASIC、内存和其他支持组件,CPU主机通过PCIe通道与加速器模块通信,而Glacier Point v2打包了一个集成的PCIe开关,允许服务器一次访问所有模块。
Lee、Rao和Arnold说,“通过适当的模型划分,我们可以运行非常大的深度学习模型。例如,对于SparseNN模型,如果单个节点的内存容量不足以满足给定模型,我们可以在两个节点之间进一步分割模型,从而增加模型可用的内存量,这两个节点通过多主机NIC连接,允许高速事务。”
Mount Shasta是与Broadcom和Verisilicon合作开发的ASIC,专为视频转码而开发。在Facebook的数据中心内,它将被安装在带有集成散热器的M.2模块上,位于可容纳多个M.2模块的Glacier Point v2(GPv2)载板中。
该公司表示,平均而言,它预计这些芯片的效率会比目前的服务器高出多倍。它的目标是在10W功率范围内以60fps输入流编码至少两倍4K。
团队表示,“我们希望我们的Zion,Kings Canyon和Mount Shasta能够分别减轻AI训练,AI推理和视频转码方面不断增长的工作量,我们将通过硬件和软件协同设计努力继续改进设计,我们欢迎其他人一起来加速这一过程。”

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消