











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Petuum:使用语言模型作为鉴别器,推动自然语言生成(NLG)
2019年04月19日 由 三分之一光年 发表
641013
0

NLG是人工智能研究和开发中最令人兴奋的项目之一。Petuum和我们的人工智能专家领导团队正在突破界限,寻找能够更好地控制生成文本的各种属性(如情感和其他风格属性)的方法。NLG是使用人工智能算法从数据中生成可理解和连贯的书面或口头语言。NLG基本上可以把许多计算机可读形式的数据翻译成人类准备好的书面和口头语言。在Petuum中,NLG的一个主要关注领域是改进我们快速准确地生成类人、语法正确且可读的文本的能力,这些文本包含从输入推断出的所有相关信息。
NeurIPS 2018论文:使用语言模型作为鉴别器的无监督文本样式传输
题为“ 使用语言模型作为鉴别器的无监督文本样式传输 ”的论文展示了Petuum在自然语言生成(NLG)方面的思想领导力。
本文重点介绍了一种使用目标域语言模型作为NLG鉴别器的新技术。通过使用语言模型作为鉴别器,该团队演示了如何在三个无监督的文本样式传输任务中表现优于传统的二元分类器鉴别器,包括单词替换解密,情感修改和相关语言翻译。
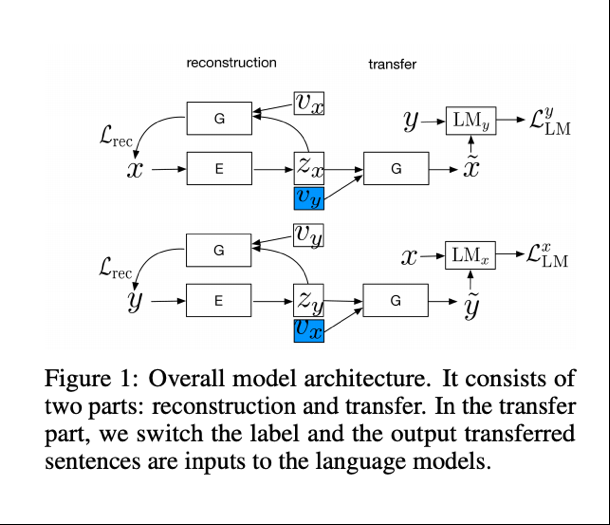
与传统的二元分类器鉴别器的比较
以前的无监督文本样式转换工作采用了带样式鉴别器的编码器、解码器结构来学习分离的表示。编码器将一个句子作为输入,并输出一个独立于样式的内容。与传统的二元分类器鉴别器相比,语言模型可以为训练生成器提供更稳定、信息更丰富的训练信号。在基于生成对抗网络(gans)的无监督式传输系统中,二元分类器通常用作鉴别器,以确保传输的句子与目标域中的句子相似。二元分类器鉴别器方法的一个困难是,鉴别器提供的错误信号可能不稳定,不足以训练生成器生成流利的语言。
作为结构化鉴别器的语言模型
通过利用petuum团队使用语言模型作为结构化鉴别器的方法,可以在培训期间放弃某些步骤,从而使过程更加稳定。
研究小组比较了将语言模型用作结构化鉴别器模型与之前使用卷积网络(CNN)作为鉴别器以及广泛的其他方法的工作。结果表明,该方法在三个任务上都取得了较好的效果:词义替换译解、情感修饰和相关的语言翻译。
词汇和语言衍生出我们如何交流、理解我们周围的世界、学习和分享我们的知识。通过提高NLG的能力,我们希望保留单词背后的力量和意义,通过人工智能帮助力量“明年的话语”。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消