











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌开源AI图像分割模型,用Cloud TPU快速准确地进行图像分割
2019年04月25日 由 董灵灵 发表
741141
0
 自去年起,谷歌的TPU芯片是谷歌云平台客户可以使用的最新一代芯片,专为人工智能推理和训练任务量身定制,如图像识别,自然语言处理和强化学习。
自去年起,谷歌的TPU芯片是谷歌云平台客户可以使用的最新一代芯片,专为人工智能推理和训练任务量身定制,如图像识别,自然语言处理和强化学习。为了支持开发应用程序的开发,谷歌采用了稳定的开源架构,如BERT(语言模型),MorphNet(优化框架)和UIS-RNN(扬声器二值化系统),通常还配有数据集。
现在,谷歌今天开源了两个新的图像分割模型,并声称这两个模型都在Cloud TPU pod上实现了最先进的性能。
图像分割
模型Mask R-CNN和DeepLab v3 +,自动标记图像中的区域并支持两种类型的分割。图像分割是标记图像中区域的过程,通常低至像素级别。有两种常见的图像分割类型:
实例分割:此过程为一个或多个对象类的每个单独实例提供不同的标签。在包含多人的全家福中,此类型的模型会用不同颜色自动突出显示每个人。
语义分段:此过程根据图像的对象或纹理类别标记图像的每个像素。例如,城市街道场景的图像中的像素可以被标记为“路面”,“人行道”,“建筑物”,“行人”或“车辆”。
自动驾驶,地理空间图像处理和医学成像以及其他应用通常需要这两种类型的分割。对于某些照片和视频编辑过程,图像分割甚至是一个令人兴奋的新推动因素,包括散景和背景去除。

高性能,高精度,低成本
当选择使用图像分割模型时,需要考虑许多因素:准确度目标,达到此准确度的总训练时间,每次训练运行的成本等。为了快速启动分析,团队在标准图像分割数据集上训练了Mask R-CNN和DeepLab v3 +,并在下表中收集了许多这些指标。
使用Mask R-CNN进行实例分割:
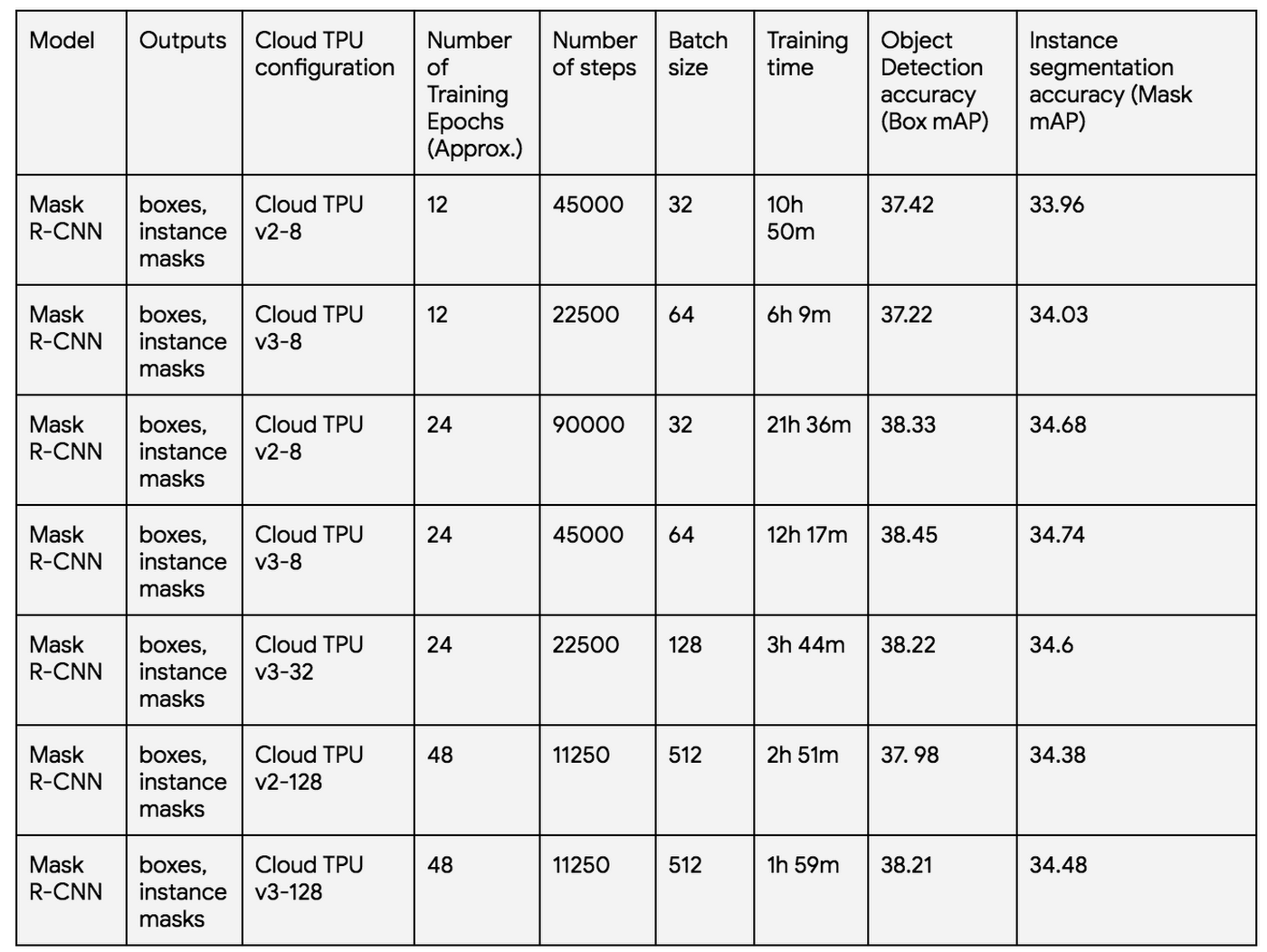
在COCO数据集上测量的掩模R-CNN训练性能和准确度
使用DeepLab v3 +进行语义分割:
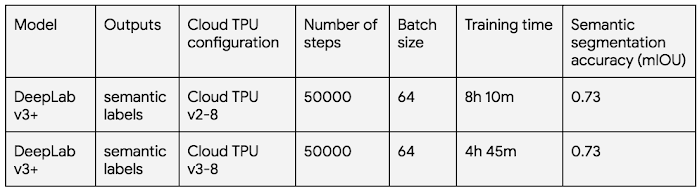
在PASCAL VOC 2012数据集上测量DeepPab v3 +训练性能和准确度
云TPU可以帮助你轻松地训练最先进的图像分割模型,并且通常可以非常快速地达到可用的准确度。前两个Mask R-CNN训练运行以及上表中的两个DeepLab v3 +运行成本低于50美元。
通过提供这些开源图像分割模型并针对一系列云TPU配置进行优化,目标是使ML研究人员,ML工程师,应用程序开发人员,学生等能够快速,经济地训练自己的模型,并满足广泛的现实世界的图像分割需求。
Mask R-CNN和DeepLab v3 +

Mask R-CNN是一个两阶段实例分割模型,可用于将图像中的多个对象定位到像素级别。模型的第一阶段从输入图像中提取特征(独特模式)以生成可能感兴趣对象的区域提议。第二阶段对这些区域提议进行细化和过滤,预测每个高可信度对象的类,并为每个对象生成像素级掩码。
DeepLab v3 +是一种快速准确的语义分割模型,可以轻松标记图像中的区域。例如,照片编辑应用程序可能会使用DeepLab v3 +自动选择风景照片中山脉上方的所有天空像素。另一方面,DeepLab 3+优先考虑分割速度。在最新一代TPU硬件(v3)上使用TensorFlow机器学习框架用开源PASCAL VOC 2012图像语料库进行训练,它能够在不到五个小时的时间内完成。
本周,谷歌在Colaboratory平台上,提供了掩码R-CNN和DeepLab 3+的教程和笔记。TPU已应用于多种主要产品中,包括谷歌翻译、谷歌相册、谷歌搜索、谷歌助手和 Gmail。Cloud TPU 使世界各地的企业都能采用此加速器技术来加速处理其在谷歌云上的机器学习工作负载。
开源:
Mask R-CNN:github.com/tensorflow/tpu/tree/master/models/official/mask_rcnn
DeepLab v3 +:github.com/tensorflow/tpu/tree/master/models/experimental/deeplab
教程:
Mask R-CNN:cloud.google.com/tpu/docs/tutorials/mask-rcnn
DeepLab v3 +:cloud.google.com/tpu/docs/tutorials/deeplab

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消