




















 top类别的第2页[/caption]
top类别的第2页[/caption] top类别的第3页[/caption]
top类别的第3页[/caption]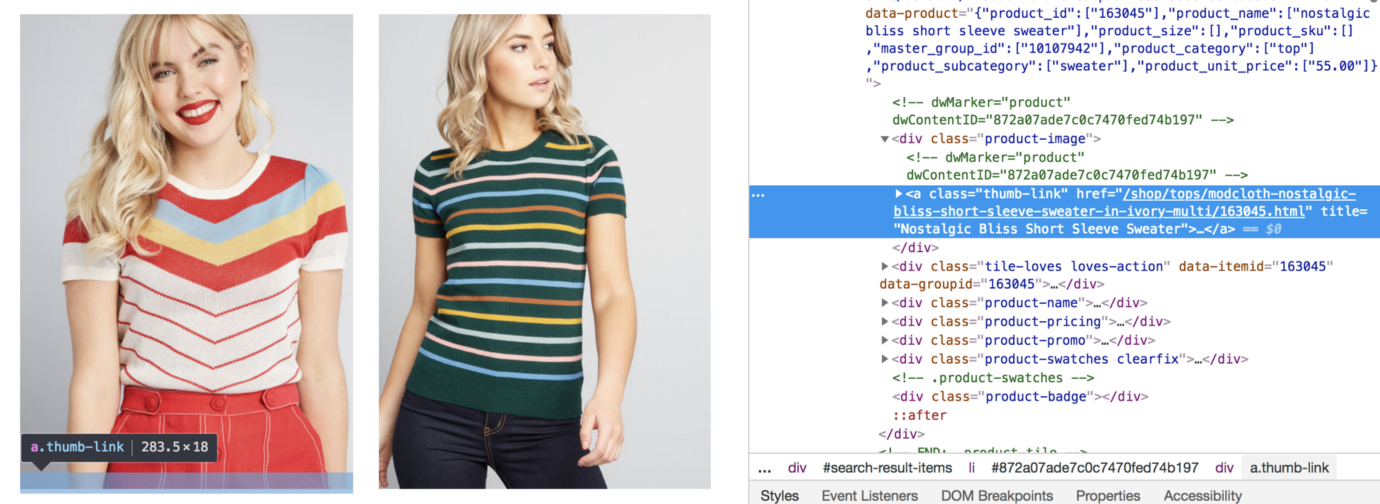
例如,在上面的图像中,具有名为pr-rd-content-block pr-accordion pr-accordion-collapsed的类的
from selenium.common.exceptions import NoSuchElementException, WebDriverException
import numpy as np
import random
## helper function to consolidate two dictionaries
def merge_two_dicts(x, y):
z = x.copy() # start with x's keys and values
z.update(y) # modifies z with y's keys and values & returns None
return z
scraped_data = []
## for each product in Tops category
for iterr in range(0,len(tops_link)):
init = 0
url = tops_link[iterr]
## open the URL in browser
try:
browser.get(url)
time.sleep(4)
except WebDriverException: ## when extracted URL is invalid
print('invalid url', iterr)
continue
## get the webpage content
content = browser.page_source
soup = BeautifulSoup(content, "lxml")
## repeat until we run of review pages
while(True):
## get the webpage content
content = browser.page_source
soup = BeautifulSoup(content, "lxml")
## extract reviewer details
reviewer_details = soup.find_all("div", {"class": "pr-rd-reviewer-details pr-rd-inner-side-content-block"})
## extract reviewers' name
reviewers_name = []
for reviewer in reviewer_details:
## In ModCloth, reviewer name appears as "By REVIEWER_NAME"
## Splitting at the end is to remove "By" to get only the actual reviewer name
reviewer_name = reviewer.find("p", {"class":"pr-rd-details pr-rd-author-nickname"}).text.split('\n')[-1].strip()
reviewers_name.append(reviewer_name)
## extract "isVerified" information
isVerified = soup.find_all("span", {"class": "pr-rd-badging-text"})
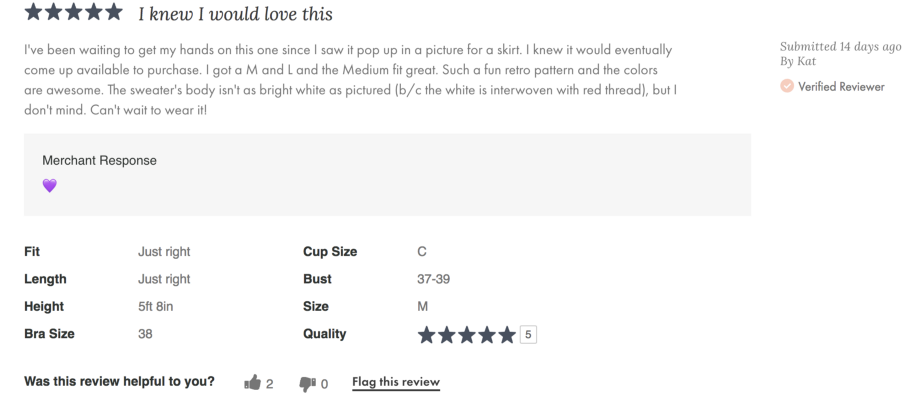
## extract the fit feedback and customer measurements data (review_metadata)
review_data = soup.find_all("article", {"class": "pr-review"})
review_metadata_raw = []
for i in range(len(review_data)):
review_metadata_raw.append(review_data[i].find("div", {"class": "pr-accordion-content"}))
## extract HTML elements which contain review metadata
review_metadata_elements = [review_metadata_raw[i].find_all("dl", {"class", "pr-rd-def-list"})
if review_metadata_raw[i] is not None else None
for i in range(len(review_metadata_raw))]
## extract actual data from HTML elements
review_metadata = []
for element in review_metadata_elements:
if element is None:
review_metadata.append(None)
continue
##
##
review_metadata.append([(element[i].find("dt").text.lower(), element[i].find("dd").text.lower())
if element is not None else ""
for i in range(len(element))])
## extract review text
review_text = [txt.text for txt in soup.find_all("p", {"class": "pr-rd-description-text"})]
review_summary = [txt.text for txt in soup.find_all("h2", {"class": "pr-rd-review-headline"})]
## extract item id
item_id = soup.find("div", {"class": "product-number"}).find("span").text
## extract item category
try:
category = soup.find("a", {"class":"breadcrumb-element"}).text.lower()
except AttributeError: ## if category not present, item is not available
time.sleep(15 + random.randint(0,10))
break
## extract available product sizes
product_sizes = [i.text.strip().lower() for i in soup.find("ul", {"class": "swatches size"})
.find_all("li", {"class": "selectable variation-group-value"})]
item_info = {"category": category, "item_id": item_id, "product_sizes": product_sizes}
## consolidate all the extracted data
## ignore records which don't have any review metadata as fit feedback is an essential signal for us
scraped_data.extend([merge_two_dicts({"review_text": review_text[j], "review_summary": review_summary[j]},
merge_two_dicts(merge_two_dicts({"user_name":reviewers_name[j]},
{data[0]:data[1] for data in review_metadata[j]})
,item_info))
for j in range(len(reviewer_details)) if review_metadata_raw[j] is not None])
## if current page is the initial one, it contains only NEXT button (PREVIOUS is missing)
if init == 0:
try:
init = 1
## execute click on NEXT by utilizing the xpath of NEXT
browser.execute_script("arguments[0].click();",
browser.find_element_by_xpath('//*[@id="pr-review-display"]/footer/div/aside/button'))
time.sleep(10 + random.randint(0,5))
except NoSuchElementException: ## No NEXT button present, less than 10 reviews
time.sleep(15 + random.randint(0,10))
break
else:
try:
## execute click on NEXT by utilizing the xpath of NEXT
## if you notice, the xpath of NEXT is different here since PREVIOUS button is also present now
browser.execute_script("arguments[0].click();",
browser.find_element_by_xpath('//*[@id="pr-review-display"]/footer/div/aside/button[2]'))
time.sleep(10 + random.randint(0,5))
except NoSuchElementException: ## No NEXT button, no more pages left
time.sleep(15 + random.randint(0,10))
break
## save the extracted data locally
np.save('./scraped_data_tops.npy',scraped_data)
有几件事需要注意:
我们在很多地方都做过异常处理。这些是在运行脚本时遇到问题时逐步添加的。
第30-97行负责将感兴趣的数据提取并解析为字典格式。通常,人们更喜欢将提取的数据存储在本地并离线解析,然而,由于我的笔记本电脑存储空间有限,我更喜欢在运行中进行解析。
Selenium在第99-119行中派上用场。由于URL不会在不同的评论页面之间更改,所以导航的惟一方法是模拟单击按钮。我们使用了NEXT按钮的xpath来做同样的事情。
XPath可用于导航XML文档中的元素和属性。要识别元素的xpath,转到inspect screen,右键单击HTML代码并复制xpath,如下图所示。
[caption id="attachment_39720" align="aligncenter" width="920"]
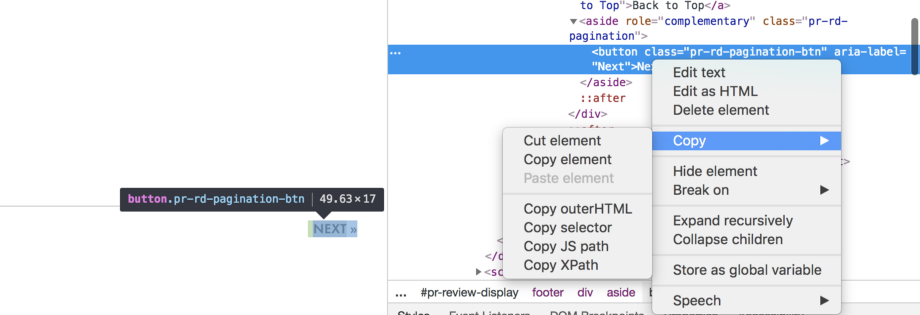 获取HTML元素XPath的方法;在本例中,为NEXT按钮[/caption]
获取HTML元素XPath的方法;在本例中,为NEXT按钮[/caption]这就完成了数据的提取和解析过程,之后我们的数据中的记录如下:
{
'bra size': '42',
'category': 'tops',
'cup size': 'd',
'fit': 'slightly small',
'height': '5ft 6in',
'hips': '46.0',
'item_id': '149377',
'length': 'just right',
'original_size': 'xxxl',
'product_sizes': {'l', 'm', 's', 'xl', 'xs', 'xxl', 'xxxl'},
'quality': '4rated 4 out of 5 stars',
'review_summary': 'I love love love this shi',
'review_text': "I love love love this shirt. I ordered up because it looked a little more fitted in the picture and I'm glad I did; if I had ordered my normal size it would probably have been snugger than I prefer. The material is good qualityit's semithick. And the design is just so hilariously cute! I'm going to see if this brand has other tees and order more.",
'shoe size': '8.00',
'shoe width': 'average',
'size': 16,
'user_name': 'erinmbundren'
}从表面上看,我们的工作已经完成了。然而,构建最终的数据集还有几个步骤,我们下次继续学习。









