











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






不只是拼写检查:用深度学习增强源码开发和自然语言编辑
2019年05月06日 由 sunlei 发表
28152
0

“这是我的会议文件,你觉得怎么样?“经过数小时的文字和插图的折磨,分享一份文件草案是一个非常自豪的时刻。通常情况下,当你的同事对你的文件进行了大量的修改之后,你肯定会感到尴尬。其中许多可能是简单的语法或样式修正,或是引用请求,一些对作者或编辑来说都不如对内容实质内容的反馈那样令人满意或有价值的小建议。指出拼写错误单词的最基本反馈形式已经是无处不在的自动化,但是……是否还有其他更复杂的编辑任务类可以学习和自动化?
学习编辑表示
深度学习在生成和理解自然语言和源代码方面有着很好的成绩。这项工作的主要挑战是设计一种专门编码编辑的方法,以便通过深度学习技术对编辑进行处理和自动化。为了理解我们的方法,请设想以下类比:
假如有一台具有大量设置的复印机。例如,可能有黑白与彩色、放大或缩小文档以及选择纸张大小的开关。我们可以将这些设置的组合表示为一个矢量,为了简洁起见,我们在这里称为Δ,它描述了复印机上所有各种旋钮和开关的配置。复印原始文档x-使用设置Δ生成新文档x+,其中应用了编辑,例如从颜色到黑白的转换。编辑本身由影印机应用,而Δ只是这些编辑的高级表示。也就是说,Δ编码情感“产生黑白拷贝”,由影印机来解释这种编码,并产生低级指令来微调给定输入x-的内部引擎。
将其转化为源代码或自然语言编辑的应用,类比中的复印机被神经网络取代,编辑表示Δ是提供给该网络的低维向量。我们限制了这个向量的能力,以鼓励系统只对编辑的高级语义进行编码,例如,“将输出转换为黑白”,而不是像“使像素(0,0)变白,使像素(0,1)变黑……”这样的低级语义。这意味着给定两个不同的输入文档x-和x-,Δ应该执行相同的编辑,如下所示的示例源代码。
[caption id="attachment_39926" align="aligncenter" width="1024"]
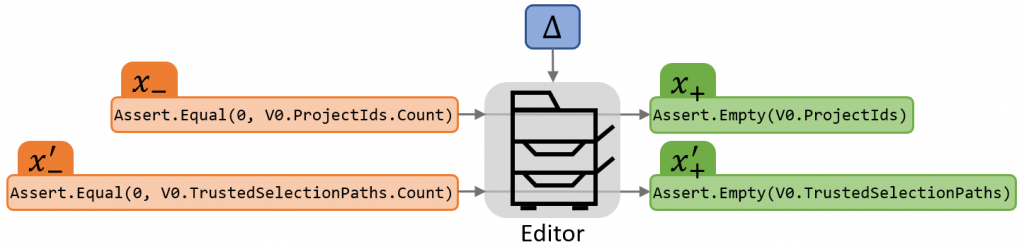 用Δ表示的低维向量的能力受到限制,以鼓励编辑或神经网络学习只编码编辑的高级语义。这意味着给定两个不同的输入文档x-和x–',Δ应该执行相同的编辑。[/caption]
用Δ表示的低维向量的能力受到限制,以鼓励编辑或神经网络学习只编码编辑的高级语义。这意味着给定两个不同的输入文档x-和x–',Δ应该执行相同的编辑。[/caption]在这种情况下,用Δ表示的语义编辑是“零计数断言被空性断言替换”。
到目前为止,我们已经描述了一个编辑器网络,它实现了一个给定编辑表示向量Δ的编辑。但我们如何学会将观察到的编辑转化为高水平的表示形式Δ呢?
这类似于学习复印机上的无数开关和旋钮在没有手册或开关上的任何标签的情况下所做的工作。为此,我们收集了一个包含原始(x-)和编辑(x+)版本的编辑库。对于源代码编辑,我们从Github上的开源代码提交创建了一个新的数据集;对于自然语言编辑,我们使用了一个以前存在的维基百科编辑数据集。在此基础上,我们使用第二个神经网络(称为编辑编码器)从x和x+计算了编辑表示Δ。
编辑和编辑编码器网络联合训练。我们要求整个系统从x和x+中计算出编辑表示形式Δ,这样编辑就可以使用Δ和x-构造一个与原始x+相同的x~+。因此,编辑编码器和编辑人员相互适应,通过Δ传递有意义的编辑信息。
[caption id="attachment_39927" align="aligncenter" width="526"]
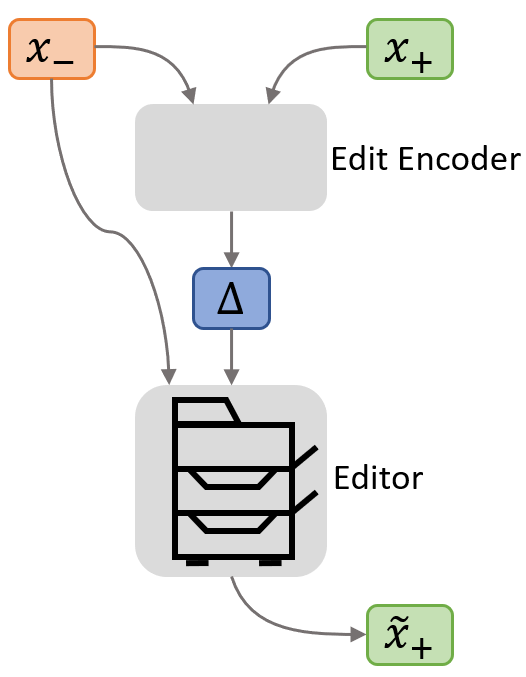 为了将观察到的编辑转化为高层次的表示形式Δ,两个神经网络(编辑网络和编辑编码器网络)被联合训练来从x和x+中计算编辑表示形式Δ,这样编辑可以使用Δ和x-构造与原始x+相同的x+。[/caption]
为了将观察到的编辑转化为高层次的表示形式Δ,两个神经网络(编辑网络和编辑编码器网络)被联合训练来从x和x+中计算编辑表示形式Δ,这样编辑可以使用Δ和x-构造与原始x+相同的x+。[/caption]探索所学的表达
既然我们可以在低维向量空间中表示编辑,那么我们就可以开始解决我们的初始问题:哪些更复杂的编辑任务类可以自动化?
回答这一问题的第一步是调查我们的系统是否能够学会区分不同类型的编辑。为此,我们对系统进行了90000 C#代码编辑的培训,然后使用经过培训的编辑编码器对3000个特别标记的编辑进行编码。在标记的集合中,每个编辑都是由16个手工重构规则(称为RoslynFixers)之一生成的。例如,修正器是rcs1089,它的描述是“使用++/–运算符而不是赋值”。当应用时,它将“x=x+1”等语句替换为“x++”。我们收集了编辑编码器为每个标记的编辑生成的编辑表示Δ,并使用t-sne投影在二维中可视化这些向量;在下面的图中,一个点的颜色表示它是从哪个定影器生成的。
我们观察到,大多数编辑都是根据所应用的重构规则正确地聚集在一起的,这表明编辑编码器很好地为相似的语义编辑分配了相似的表示Δ,并分离了不同类型的编辑。
[caption id="attachment_39928" align="aligncenter" width="512"]
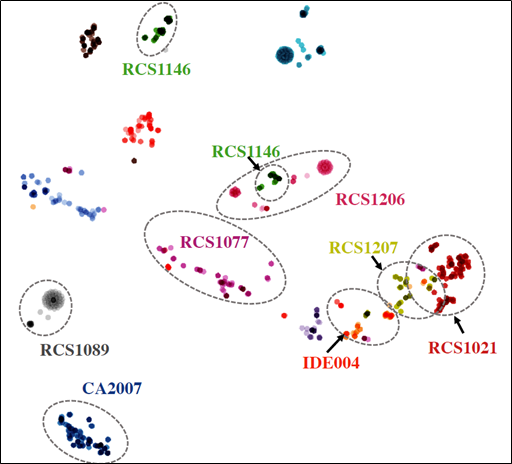 一个T-SNE可视化的编辑编码器生成的16个手工重构规则称为Roslyn Fixers显示,编码器能够分配类似的表示类似的语义编辑。点的颜色指示从哪个固定器生成它。[/caption]
一个T-SNE可视化的编辑编码器生成的16个手工重构规则称为Roslyn Fixers显示,编码器能够分配类似的表示类似的语义编辑。点的颜色指示从哪个固定器生成它。[/caption]我们对自然语言的编辑也观察到了类似的结果。我们的系统将语义上有意义的编辑聚集在一起。例如,当系统接受维基百科编辑培训时,其中一个编辑集群表示在句子中添加介词短语,如“在月球上”和“在市场上”,另一个则表示在人名中添加中间名。
应用学习到的编辑
我们认为,当分析了大量的编辑语料库并识别了编辑聚类时,可以从聚类中心提取规范化编辑向量,并将其应用到新文档中,以生成自动化编辑过程的建议。为了研究这是否可行,我们再次使用由RoslynFixers生成的编辑数据集。
为了评估将编辑表示转换到新上下文的效果,我们考虑了两对编辑,x和x+以及y和y+。我们从第一对计算了一个编辑表示Δ,并要求我们的编辑将其应用于y–。例如,我们考虑将“x=x+1”替换为“x++”的编辑,然后尝试将结果编辑表示应用于“foo=foo+1”。在我们的实验中,我们发现在大约50%的示例中,编辑器结果将与预期的编辑结果匹配。然而,这在很大程度上取决于编辑的复杂性:在RCS1089生成的示例中,精度为96%,而具有“optimize stringbuilder.append/appendline call”描述并重写长代码序列的RCS1197只获得5%的精度。
虽然我们的ICLR研究了文本和代码中的编辑表示问题,但我们提出的方法只是对这些有趣数据的早期探索。我们看到许多研究机会来提高方法的精度,并将其应用到其他设置中。潜在的应用程序确实令人兴奋:从数万名专业编辑、软件开发人员和设计师的工作中学习到的文本、代码或图像的自动改进。这可能意味着即使在要求你的同事编辑你的下一篇会议文件之后,你也要保持那种自豪的时刻,快乐的写作吧!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
十分钟机器学习入门








广告


写评论取消
回复取消