











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何用Python抓取最便宜的机票信息(下)
2019年05月08日 由 sunlei 发表
864962
0
上期回顾:如何用Python抓取最便宜的机票信息(上)
到目前为止,我们有一个函数来加载更多的结果,还有一个函数来抓取这些结果。我可以在这里结束这篇文章,您仍然可以手动使用这些工具,并在您自己浏览的页面上使用抓取功能,但我确实提到了一些关于向您自己发送电子邮件和其他信息的内容!这都在下一个功能里面。
它要求你填写城市和日期。从那里,它将打开kayak字符串中的地址,该字符串直接进入“最佳”结果页排序。在第一次刮取之后,我顺利地得到了价格最高的矩阵。它将用于计算平均值和最小值,与Kayak的预测一起在电子邮件中发送(在页面中,它应该在左上角)。这是在单一日期搜索中可能导致错误的原因之一,因为那里没有矩阵元素。
def start_kayak(city_from, city_to, date_start, date_end):
"""City codes - it's the IATA codes!
Date format - YYYY-MM-DD"""
kayak = ('https://www.kayak.com/flights/' + city_from + '-' + city_to +
'/' + date_start + '-flexible/' + date_end + '-flexible?sort=bestflight_a')
driver.get(kayak)
sleep(randint(8,10))
# sometimes a popup shows up, so we can use a try statement to check it and close
try:
xp_popup_close = '//button[contains(@id,"dialog-close") and contains(@class,"Button-No-Standard-Style close ")]'
driver.find_elements_by_xpath(xp_popup_close)[5].click()
except Exception as e:
pass
sleep(randint(60,95))
print('loading more.....')
# load_more()
print('starting first scrape.....')
df_flights_best = page_scrape()
df_flights_best['sort'] = 'best'
sleep(randint(60,80))
# Let's also get the lowest prices from the matrix on top
matrix = driver.find_elements_by_xpath('//*[contains(@id,"FlexMatrixCell")]')
matrix_prices = [price.text.replace('$','') for price in matrix]
matrix_prices = list(map(int, matrix_prices))
matrix_min = min(matrix_prices)
matrix_avg = sum(matrix_prices)/len(matrix_prices)
print('switching to cheapest results.....')
cheap_results = '//a[@data-code = "price"]'
driver.find_element_by_xpath(cheap_results).click()
sleep(randint(60,90))
print('loading more.....')
# load_more()
print('starting second scrape.....')
df_flights_cheap = page_scrape()
df_flights_cheap['sort'] = 'cheap'
sleep(randint(60,80))
print('switching to quickest results.....')
quick_results = '//a[@data-code = "duration"]'
driver.find_element_by_xpath(quick_results).click()
sleep(randint(60,90))
print('loading more.....')
# load_more()
print('starting third scrape.....')
df_flights_fast = page_scrape()
df_flights_fast['sort'] = 'fast'
sleep(randint(60,80))
# saving a new dataframe as an excel file. the name is custom made to your cities and dates
final_df = df_flights_cheap.append(df_flights_best).append(df_flights_fast)
final_df.to_excel('search_backups//{}_flights_{}-{}_from_{}_to_{}.xlsx'.format(strftime("%Y%m%d-%H%M"),
city_from, city_to,
date_start, date_end), index=False)
print('saved df.....')
# We can keep track of what they predict and how it actually turns out!
xp_loading = '//div[contains(@id,"advice")]'
loading = driver.find_element_by_xpath(xp_loading).text
xp_prediction = '//span[@class="info-text"]'
prediction = driver.find_element_by_xpath(xp_prediction).text
print(loading+'\n'+prediction)
# sometimes we get this string in the loading variable, which will conflict with the email we send later
# just change it to "Not Sure" if it happens
weird = '¯\\_(ツ)_/¯'
if loading == weird:
loading = 'Not sure'
username = 'YOUREMAIL@hotmail.com'
password = 'YOUR PASSWORD'
server = smtplib.SMTP('smtp.outlook.com', 587)
server.ehlo()
server.starttls()
server.login(username, password)
msg = ('Subject: Flight Scraper\n\n\
Cheapest Flight: {}\nAverage Price: {}\n\nRecommendation: {}\n\nEnd of message'.format(matrix_min, matrix_avg, (loading+'\n'+prediction)))
message = MIMEMultipart()
message['From'] = 'YOUREMAIL@hotmail.com'
message['to'] = 'YOUROTHEREMAIL@domain.com'
server.sendmail('YOUREMAIL@hotmail.com', 'YOUROTHEREMAIL@domain.com', msg)
print('sent email.....')
我使用Outlook帐户(hotmail.com)测试了这一点。虽然我没有使用Gmail帐户来测试它来发送电子邮件,但是您可以搜索许多替代方法,我前面提到的那本书也有其他的方法来实现这一点。如果您已经有一个Hotmail帐户,那么您替换您的详细信息,它应该可以工作。
如果您想探索脚本的某些部分正在做什么,请复制它并在函数之外使用它。只有这样你才能完全理解。
利用我们刚刚创造的一切
在所有这些之后,我们还可以想出一个简单的循环来开始使用我们刚刚创建的函数并使它们保持忙碌。完成四个“花式”提示,让你实际写下城市和日期(输入)。因为当我们进行测试时,我们不希望每次都输入这些变量,在需要的时候用下面的显式方法替换它。
city_from = input('From which city? ')
city_to = input('Where to? ')
date_start = input('Search around which departure date? Please use YYYY-MM-DD format only ')
date_end = input('Return when? Please use YYYY-MM-DD format only ')
# city_from = 'LIS'
# city_to = 'SIN'
# date_start = '2019-08-21'
# date_end = '2019-09-07'
for n in range(0,5):
start_kayak(city_from, city_to, date_start, date_end)
print('iteration {} was complete @ {}'.format(n, strftime("%Y%m%d-%H%M")))
# Wait 4 hours
sleep(60*60*4)
print('sleep finished.....')如果你做到了这一步,恭喜你!我能想到的改进有很多,比如与Twilio集成,向您发送文本消息而不是电子邮件。您还可以使用VPN或更模糊的方法同时从多个服务器上研究搜索结果。有验证码的问题,可能会不时出现,但有解决这类问题的方法。我认为您在这里有一些非常可靠的基础,我鼓励您尝试添加一些额外的特性。也许您希望Excel文件作为附件发送。我总是欢迎建设性的反馈,所以请随时在下面发表评论。我试着回应每一个人!
[caption id="attachment_40013" align="aligncenter" width="496"]
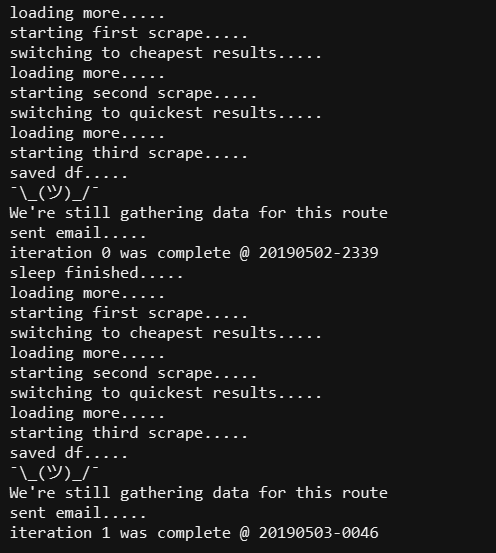 使用脚本的测试运行示例[/caption]
使用脚本的测试运行示例[/caption]如果您想了解更多关于web抓取的知识,我强烈推荐您使用python进行web抓取。我真的很喜欢这些例子和对代码如何工作的清晰解释。如果你更喜欢社交媒体的抓取,还有一本关于这个主题的好书,以后有机会在这里介绍给你们~

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消