











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






从浅到深全面理解梯度下降:原理,类型与优势
2019年05月11日 由 深深深海 发表
873974
0
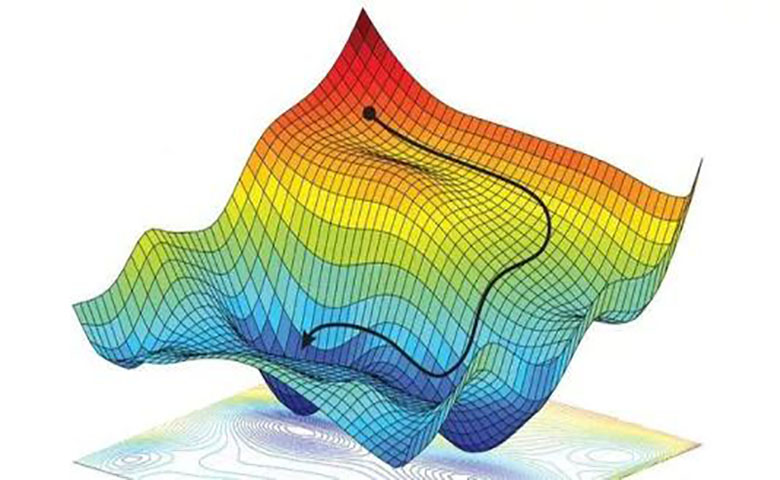 梯度下降是迄今为止最流行的优化策略,用于机器学习和深度学习。它在训练模型时使用,可以与每个算法结合使用,易于理解和实现。
梯度下降是迄今为止最流行的优化策略,用于机器学习和深度学习。它在训练模型时使用,可以与每个算法结合使用,易于理解和实现。因此,每个使用机器学习的人都应该理解它的概念。阅读这篇文章后,你将了解梯度下降的工作原理,使用的类型,以及它们的优势。
本文分为以下几个部分:
- 介绍
- 什么是梯度
- 怎么运行
- 学习率
- 如何确保它正常运行
- 梯度下降的类型(批量梯度下降,随机梯度下降,小批量梯度下降)
- 总结
介绍
梯度下降法用于训练机器学习模型。它是一种基于凸函数的优化算法,通过迭代调整参数,将给定函数最小化到它的局部最小值。
它只是用来找到一个函数参数(系数)的值,使一个成本函数尽可能地最小化。
首先定义初始参数值,然后从梯度下降开始,使用微积分迭代调整值,以便最小化给定的成本函数。但要完全理解它的概念,首先需要知道梯度是什么。
什么是梯度
梯度衡量的是:如果稍微改变输入,函数输出会发生多大变化。
它只是根据误差的变化来衡量所有权重的变化。你还可以将梯度视为函数的斜率。梯度越高,斜率越陡,模型学习速度越快。但如果斜率为零,模型将停止学习。从数学的角度来说,梯度是关于其输入的偏导数。
想象一下,一个人想要爬山,而且想用尽可能少的步数。最初时他会往最陡的方向迈出很大的一步,只要不靠近山顶就可以一直保持这样的步幅。当他接近登顶时,他的步幅会越来越小,因为他不想前功尽弃。这个过程就可以使用梯度以数学方式描述。
请看下面的图片。想象一下,它以俯视图展示了山丘,红色的箭头显示了登山者的步幅。在这种情况下,可以把梯度想象成一个向量,其中包含人可以走的最陡的一步的方向,以及以这样的步幅应该走多长时间。
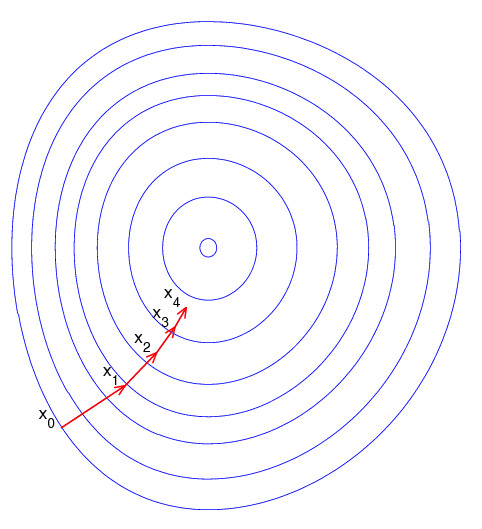
请注意,从X0到X1的梯度比从X3到X4的梯度长得多。这是因为那里山的陡度/坡度较小,这决定了向量的长度。这与登山的例子完美契合,因为山坡越来越陡峭,就说明你爬得越高。因此,对于登山者来说,坡度的减小伴随着坡度的减小和步长的减小。
怎么运行
梯度下降可以被认为是到山谷的底部,而不是爬上山。这是因为它是最小化给定函数的最小化算法。
下面的等式描述了梯度下降的作用:“b”描述了登山者的下一个位置,而“a”代表了他当前的位置。减号是指梯度下降的最小化部分。中间的“gamma”是等待因子,梯度项(Δf(a))只是最陡下降的方向。
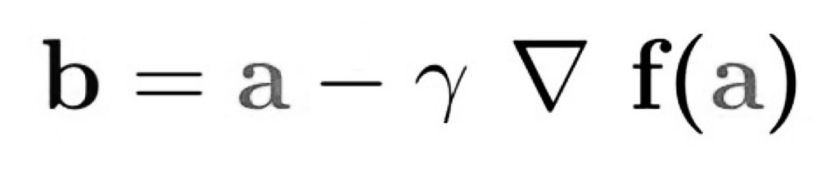
所以这个公式基本上告诉你下一个你需要去的位置,这是最陡下降的方向。
但是为了确保你完全掌握这个概念,我们将引入另一个例子。
想象一下,你正在处理机器学习问题,并希望使用梯度下降训练算法,以最小化成本函数J(w,b)并通过调整其参数(w和b)达到其局部最小值。
我们来看看下面的图片,它是梯度下降的一个例子。横轴表示参数(w和b),成本函数J(w,b)表示在纵轴上。你还可以在图像中看到渐变下降是凸函数。
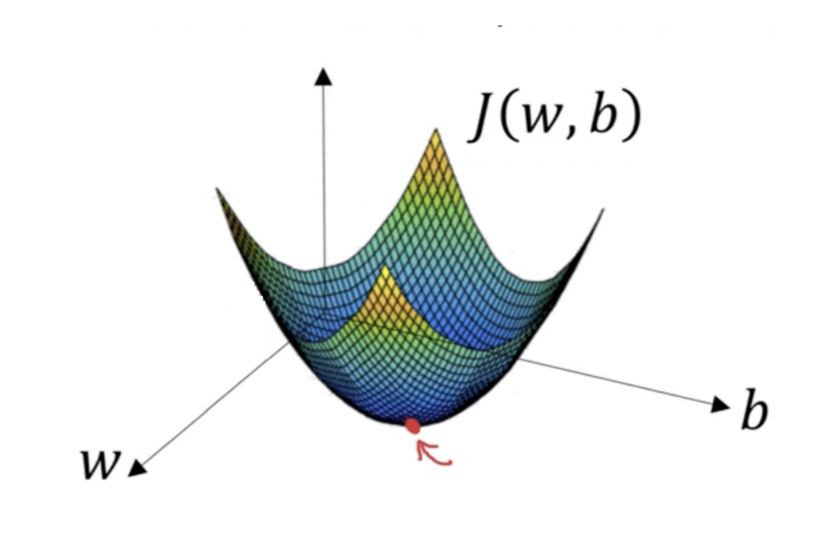
我们希望找到W和B的值,这些值对应于成本函数的最小值(用红色箭头标记)。首先找到正确的值,我们用一些随机数初始化W和B的值,然后从那个点(在我们的插图顶部附近的某处)开始进行梯度下降。然后,它沿着最陡的下行方向(例如,从图的顶部到底部)一步一步地向下移动,直到到达成本函数尽可能小的点。
学习率的重要性
梯度下降进入局部最小值方向的步长取决于学习率。它决定了我们向最佳权重移动的速度快慢。
为了使梯度下降达到局部最小值,我们必须将学习率设置为适当的值,既不太低也不太高。
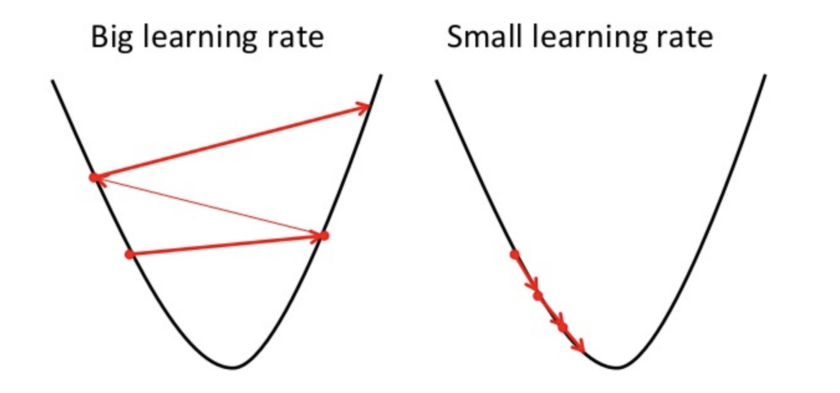
这样做是因为如果它的步幅太大,它可能不会达到局部最小值,因为它只是在梯度下降的凸函数之间来回反弹,就像你在下面图像的左侧看到的那样。而如果将学习速率设置为非常小的值,则梯度下降最终将达到局部最小值,但可能会花费太多时间,就像图像的右侧那样。
你可以通过在图表上绘制学习率来检查学习率是否表现良好,我们将在下面的部分中讨论。
如何确保它正常运行
确保梯度下降正常运行的一种好方法是将成本函数绘制为梯度下降运行。将迭代次数放在x轴上,将成本函数的值放在y轴上。这使你可以在每次梯度下降迭代后查看成本函数的值。这可以让你轻松发现学习率的合适程度。你只需为它尝试不同的值并将它们全部绘制在一起。
你可以在左下方看到这样的情况,右边的图像显示了好的和坏的学习率之间的差异:
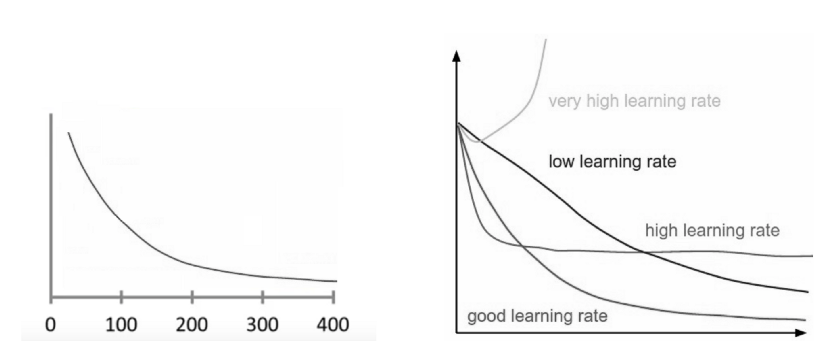
如果梯度下降工作正常,则每次迭代后成本函数应减少。
当梯度下降不再能够降低成本函数并且或多或少地保持在同一水平时,我们可以说它已经聚合了。请注意,梯度下降需要聚合的迭代次数有时会有很大差异。它可能需要50次迭代,有时需要60000次甚至300万次。因此,迭代次数很难提前估算。
还有一些算法可以自动告诉你梯度下降是否聚合,但你需要预先定义聚合的阈值,这也很难估计。这就是为什么这些简单的图是首选的聚合测试。
通过绘图监控梯度下降的另一个优点是,如果它不能正常工作,你可以很容易地发现,例如,如果成本函数在增加。在使用梯度下降法时,增加成本函数的主要原因是学习率太高。
如果你在图中看到你的学习曲线正在上升和下降,而没有真正达到较低的点,你也应该尝试降低学习率。当你开始用梯度下降法处理一个给定的问题时,只需尝试一下0.001、0.003、0.01、0.03、0.1、0.3、1等,看看哪一个表现最好。
梯度下降的类型
有三种流行的梯度下降类型,它们主要区别在于使用的数据量不同。
1.批量梯度下降(Batch Gradient Descent)
批量梯度下降(也称为vanilla gradient descent)计算训练数据集中每个示例的误差,但只有在评估了所有训练样本后,模型才会更新。整个过程就像一个循环,叫做训练周期。
其优点是计算效率高,产生稳定的误差梯度和聚合性。批量梯度下降的缺点是,稳定的误差梯度有时会导致聚合状态,这不是模型所能达到的最佳状态。它还要求整个训练数据集都在内存中,并且可供算法使用。
2.随机梯度下降(Stochastic Gradient Descent)
相反,随机梯度下降(SGD)对数据集中的每个训练示例都这样做。这意味着它将逐个更新每个训练示例的参数。这可以使SGD比批量梯度下降更快,具体取决于问题。一个优点是频繁的更新使我们得到一个非常详细的改进率。
事实上,频繁更新使这种方法在计算上成本更高。这些更新的频率也可能导致噪声梯度,使错误率不稳定波动,而不是缓慢下降。
3.小批量梯度下降(Mini Batch Gradient Descent)
小批量梯度下降是首选方法,因为它结合了前两种方法。它只是将训练数据集拆分成小批量,并为每个批量执行更新。因此,它平衡了随机梯度下降的稳健性和批量梯度下降的效率。
常见的小批量的大小介于50到256之间,但与任何其他机器学习技术一样,没有明确的规则,因为它们可能因不同的应用而异。请注意,它是你训练神经网络时的首选算法,也是深度学习中最常见的梯度下降类型。
总结
现在,你已经学到了很多关于梯度下降的知识。你应该已经了解了它的基本术语,并且了解了算法是如何工作的,为什么学习率是最重要的超参数,以及如何检查算法是否正确地学习。此外还有三种最常见的梯度下降类型及其优缺点,现在你可以尝试训练自己的模型啦!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消