











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






英伟达一键图像转换!无监督图像到图像转换算法开源
2019年05月10日 由 深深深海 发表
620462
0
 当看到老虎时,你可以毫无压力地想象出老虎伏卧着的样子,因为我们看过其它动物伏卧的样子,所以很容易能够进行联想。
当看到老虎时,你可以毫无压力地想象出老虎伏卧着的样子,因为我们看过其它动物伏卧的样子,所以很容易能够进行联想。
然而,现有的无监督图像到图像转换模型想要实现这点,就需要有很多训练图片。这极大地限制了它们的使用。

英伟达等研究机构希望这样的模型可以解决模仿问题。
在线转换
下面是模型进行的转换,不止是静态,动态也可以:

事实证明,食物也能够进行转换:

研究提供了一个demo界面可以在线转换,选择宠物图片并上传,画一个紧密的矩形覆盖宠物的头部,只需左键单击鼠标,拖动并释放,然后点击转换即可查看结果。
用一张可爱的猫咪图片尝试一下:

结果:

想尝试的小伙伴:
nvlabs.github.io/FUNIT/petswap.html
转换框架
虽然无监督图像到图像转换方法已经取得了显著的成功,但它们仍然在两个方面受到限制。
- 首先,通常需要在训练时间内看到来自目标类的大量图像。
- 其次,在测试时间内,不能将用于转换任务的训练模型重新用于另一转换任务。
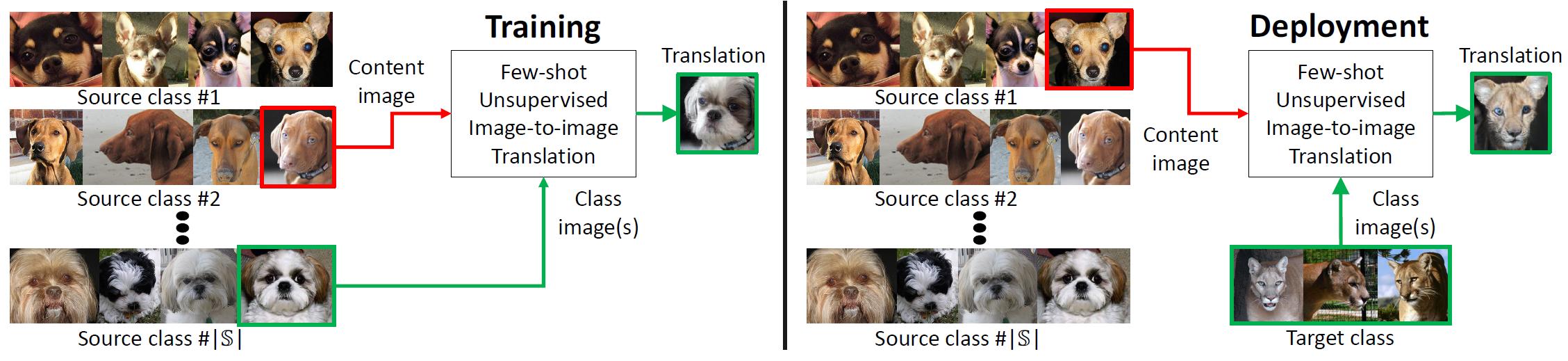 通过人类从少数例子中汲取新物体的本质的能力中汲取灵感,我们开发了一种几乎无需监督的图像到图像转换算法,该算法适用于以前没见到过的目标类别。在测试时指定,仅由几个示例图像指定,模型通过将对抗训练方案与新颖的网络设计相结合,实现了这种能力。
通过人类从少数例子中汲取新物体的本质的能力中汲取灵感,我们开发了一种几乎无需监督的图像到图像转换算法,该算法适用于以前没见到过的目标类别。在测试时指定,仅由几个示例图像指定,模型通过将对抗训练方案与新颖的网络设计相结合,实现了这种能力。我们提出了几个无监督的图像到图像转换框架(FUNIT)来解决这个限制。在训练时间内,FUNIT模型学习在从一组源类中采样的任何两个类之间转换图像。
在测试时间内,模型会显示一些模型从未见过的目标类的图像。该模型利用这些少量示例图像将源类的输入图像转换为目标类。
测试结果

我们展示了动物脸部,鸟,花卉和食物转换的结果。其中:
- y1和y2是测试期间可用的目标类的少数示例图像;
- x是源类的输入图像;
- x bar是从源类到目标类的转换。
模型能够将豹子转换为沙皮狗,即使它在训练时间从未见过沙皮狗图像。
结果表明,模型能够成功将源类的图像转换为新类中的相似图像,输出图像也十分逼真。
开源:
github.com/nvlabs/FUNIT
论文:
arxiv.org/pdf/1905.01723.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消