











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Babylon:建立AI医生的数据挑战(2/5):准确性
2019年05月16日 由 文灬森特 发表
616752
0

挑战2:对于有意或无意地向我们提供不准确信息的会员,我们能做些什么?
这是一个由五部分组成的博客系列的第二部分,探讨了我们在构建个人人工智能医生时所面临的一些挑战。
到目前为止,我们一直在处理我们收集的具有相同潜在价值的所有数据——每个数据点的最终价值仅仅取决于用例。
但事实是,并非所有数据点都是平等的。
如果我们只看成员直接提供的数据,每个数据点的内在价值取决于成员的自我意识、健康素养和意图。
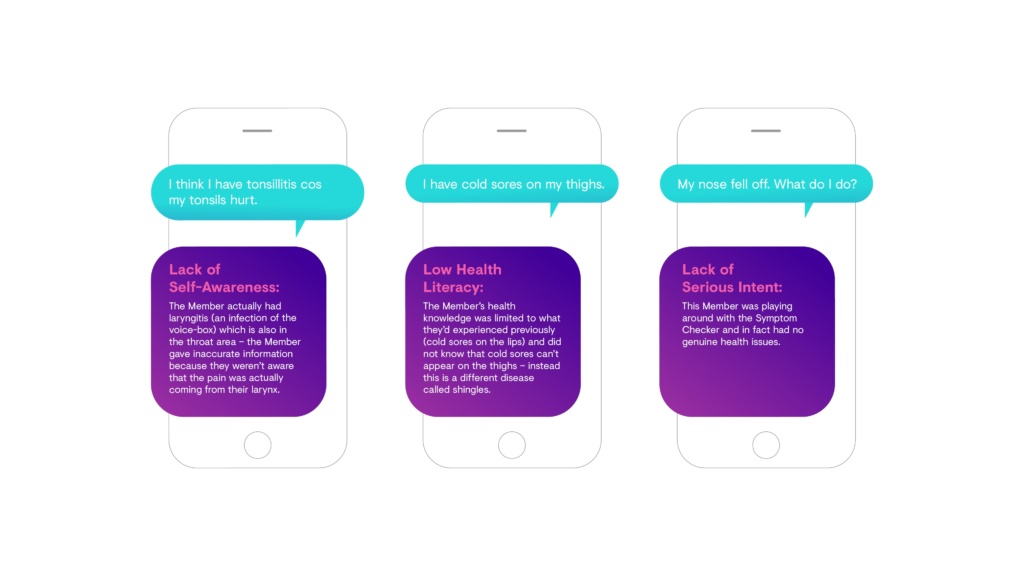
图4:一些例子来说明为什么我们不能总是依赖我们的成员提供的数据点
不准确的信息会损害我们给予人们所需关怀的能力。我们的症状检查程序将根据错误的症状识别错误的潜在可能原因;我们的机器学习模型的培训将被错误的患者数据误导。
问题:对于那些故意或无意地给我们提供不准确信息的会员,我们能做些什么?
首先,我们必须区分具有不同可信度的数据点。有很多方法可以做到这一点,但精度不同。我们画的越精确,就越需要努力去实现。
遵循80:20的规则,总是从简单开始。
一个简单的方法是为每个数据源分配一个相对的可信级别。
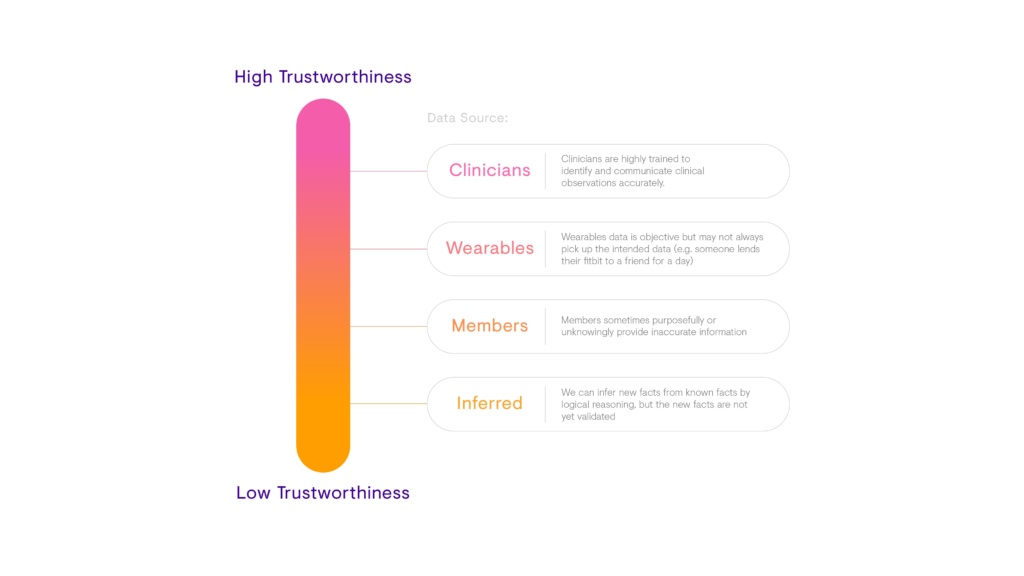
图5:Babylon不同数据源的相对可信度的简单谱
第4课:从一个简单的“硬编码”方法开始,以确定信任每个数据点的程度
在基于可信度将数据分为不同的存储桶之后,我们可以考虑在使用这些数据时如何对每个存储桶进行不同的处理。
就像关联性一样,这一切都归结为目标。
例如,我们为全科医生咨询提供的数据需要最大的准确性,因为错误的决定最终可能危及生命。
然而,对健康检查的不准确输入最坏的结果是,建议不适合个人,但仍然旨在改善他们的健康。
我们对使用潜在不准确信息的容忍度首先取决于围绕特定用例的法规要求。如果法规没有规定,我们的容忍度阈值取决于基于不准确信息做出错误决策的潜在影响。潜在影响越大,我们的容忍度就越低。
第5课:数据精度公差阈值因用例而异
当然,如果我们不必担心不可靠的数据,那就更好了。
虽然很难在不知情的情况下解决成员提供不准确数据的问题(他们不知道自己不知道什么),但我们有一些方法可以解决成员故意提供不准确数据的问题。
这有助于理解会员行为背后的心理。
有了Babylon症状检查程序,我们知道会员故意提供虚假数据的两个常见原因:1)实验和2)游戏。
实验:人们喜欢和症状检查程序一起玩来测试它的功能,或者只是为了好玩。为了让成员们满足这个愿望,同时确保它不会干扰Babylon服务的严重使用,我们选择不停止实验行为,而是找到方法来分离实验与真实的互动。我们为我们的国民保健系统成员做这件事的一个方法就是简单地问他们是否真的想让我们把他们刚刚告诉我们的内容添加到他们的国民保健系统健康记录中。
游戏:有些人想强制症状检查程序给出一定的输出。他们这样做是因为他们认为产出在某种程度上是有回报的。因此,我们通过将“奖励”相关联的行为模式分离来减少游戏。
第6课:了解成员激励他们尽其所能提供准确数据的动机

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消