











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用深度学习从非结构化文本中提取特定信息
2019年05月16日 由 sunlei 发表
933296
0

这是与我们工作有关的一系列技术职务中的第一个。在iki项目中,涵盖了一些机器学习的应用案例和用于解决各种自然问题的深度学习技术的语言处理和理解问题。
在这篇文章中,我们将处理从非结构化文本中提取某些特定信息的问题。我们需要从用户的简历Curriculam Vitaes(CVs)中提取他们的技能,即使他们是以“正在部署”之类的任意方式编写的生产服务器上的定量交易算法。
这篇文章有一个演示页面,检查我们模型在你的简历上的性能。
语言模型
现代语言模型(ULMfit, ELMo)使用无监督学习技术,比如在更具体的监督训练步骤之前,在大型文本语料库上创建嵌入的RNNs,以获得语言结构的一些原始“知识”。相反,在某些情况下,您需要一个针对非常特定和小数据集训练的模型。这些模型对一般语言结构的知识几乎为零,只具有特殊的文本特征。一个经典的例子将是一个用于电影评论或新闻数据集的幼稚情感分析工具——最简单的工作模型只能在“好”或“坏”形容词同义词和一些强调词出现的情况下运行。在我们的研究中,我们利用了这两种方法。
一般来说,当我们分析一些文本语料库时,我们要看的是每个文本的整个词汇。流行的文本矢量化方法,如tfidf、word2vec或GloVe模型,都使用整个文档的词汇表来创建向量,除了停止词(例如冠词、代词和其他一些非常通用的语言元素,在这样的统计平均过程中几乎没有语义意义)。如果有一个更具体的任务,并且您有一些关于文本语料库的附加信息,那么您可能会说一些信息比另一些更有价值。例如,要对烹饪食谱进行一些分析,从文本中提取配料或菜名类是很重要的。另一个例子是从CVs的语料库中提取专业技能。例如,如果我们能够将每一份简历与提取出来的技能向量联系起来,从而对其进行矢量化,就能让我们实现更成功的行业职位集群。
例子:
简历:数据科学家,精通机器学习、大数据、开发、统计和分析。我的数据科学家团队实现了Python机器学习模型集成、叠加和特性工程,显示了预测分析的高准确率。利用Doc2Vec单词嵌入和神经网络,建立了一个推荐系统。
提取专业技能:机器学习、大数据、开发、统计学、分析学、Python机器学习模型集成、叠加、特征工程、预测分析、Doc2Vec、单词嵌入、神经网络。
步骤1:语音标记部分
[caption id="attachment_40309" align="aligncenter" width="826"]
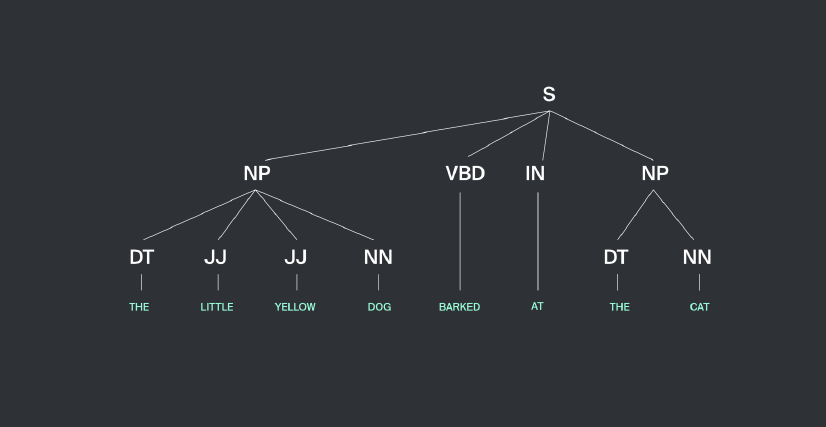 NLTK书,第7章,图2.2:一个基于NP块的简单正则表达式的例子。[/caption]
NLTK书,第7章,图2.2:一个基于NP块的简单正则表达式的例子。[/caption]实体提取是文本挖掘类问题的一部分,即从非结构化文本中提取结构化信息。让我们仔细看看建议的实体提取方法。至于技能主要出现在所谓的名词短语萃取过程中,我们的第一步是实体识别由NLTK库内置方法。词性标注方法提取名词短语(NP)和代表之间的关系构建树名词短语和句子的其他部分。NLTK库中有许多工具可以执行这样的短语分解。
我们可以将一个模型定义为一个正则表达式,给出句子分解(例如,我们可以将一个短语定义为许多形容词加上一个名词),或者我们可以用NLTK中抽取的名词短语示例来教授一个带有标记的文本数量的模型。这一步的结果是接收到许多实体,其中一些是目标技能,一些不是——此外,技能简历可以包含一些其他实体,如地点、人员、对象、组织等等。
步骤2:候选人分类的深度学习架构
下一步是实体分类。这里的目标很简单——区分技能与“非技能”。用于培训的特征集由候选短语的结构和上下文组成。显然,为了训练一个模型,我们必须创建一个带标签的训练集,我们手工地为1500个提取出的实体进行训练,其中包括技能和“非技能”。
我们从来没有试图将我们的模型适用于一些有限的硬编码技能集,该模型背后的核心思想是学习英语CVs中的技能语义,并使用该模型提取不可见的技能。
每个单词的向量都由一些二进制特征组成,比如数字或其他特殊字符的出现(技能通常包含数字和符号:c#、Python3)、第一个字母或整个单词的大写(SQL)。我们还检查一个单词是否出现在英语词汇表和一些主题列表中,如名称、地名等。使用所列特性的最终模型在实体测试集上显示了74.4%的正确结果。使用另一种二进制特征描述候选英语前缀和后缀的存在,提高了模型在测试集上的性能,正确率高达77.3%。此外,在模型的特征集中添加编码部分语音的热门向量,将我们的结果提高到了84.6%。
一个可靠的语义词嵌入模型不能在CV数据集上进行训练,它太小、太窄,要解决这个问题,你应该使用在其他一些非常大的数据集上训练的词嵌入。我们使用了50维的手套模型向量,这使得我们的模型在测试集中的正确率达到了89.1%。您可以通过上传简历中的文本,在我们的演示中使用最终的模型。

常见的语言标签(NLTK POS tagger, Stanford POS tagger)经常在简历的短语标注任务中出错。原因在于,通常简历忽略语法是为了突出经验,并给它一些结构(人们在句子开头用谓语,而不是主语,有时短语缺少适当的语法结构),很多单词都是特定的术语或名称。我们必须编写自己的POS标记器来解决上述问题。
利用Keras神经网络进行分类,该神经网络具有三个输入层,每个输入层都设计用来接收特殊类别的数据。第一个输入层采用可变长度向量,由上述候选短语的特征组成,候选短语可以有任意数量的单词。该特征向量由LSTM层处理。
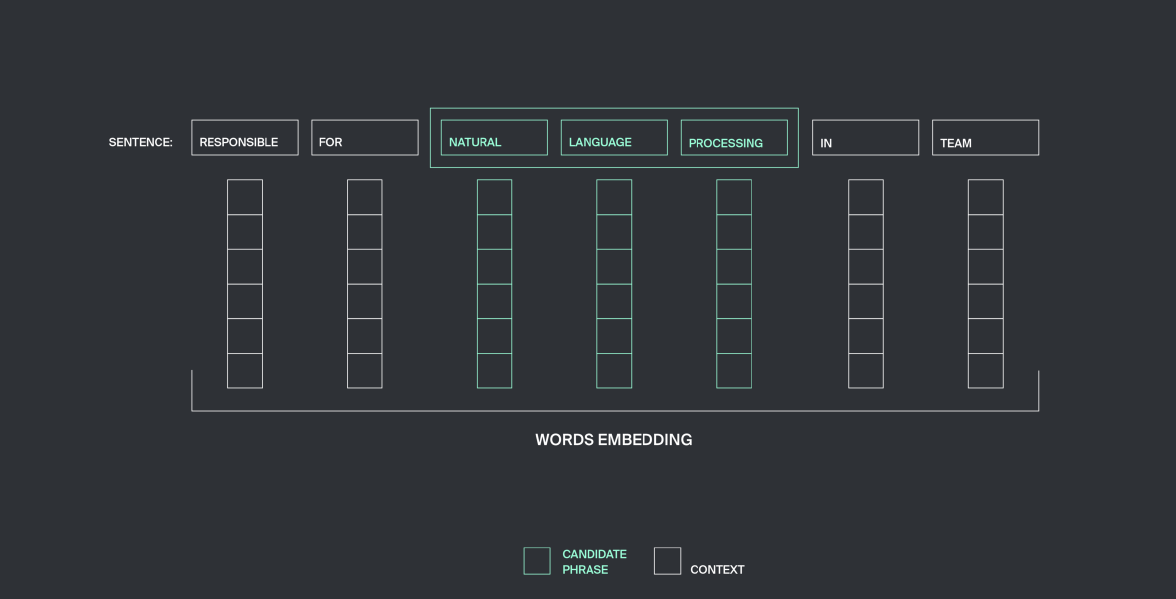
第二个可变长度向量带来了上下文结构信息。对于给定的窗口大小n,我们取候选短语右侧的n个相邻单词和左侧的n个单词,这些单词的向量表示形式被连接到可变长度向量中,并传递到LSTM层。我们发现最优n=3。
第三输入层具有固定长度,并利用候选短语及其上下文-协调最大值和最小值的一般信息处理矢量,其中,在其他信息中,表示整个短语中存在或不存在许多二进制特征。
在这里,我们称这种建筑为SkillsExtractor。
[caption id="attachment_40312" align="aligncenter" width="820"]
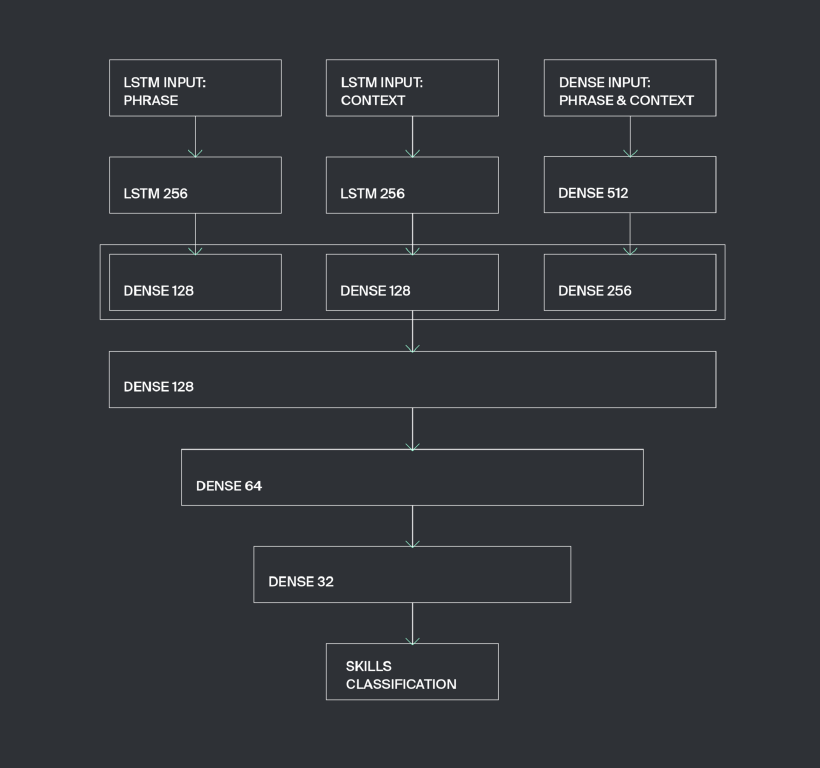 技能提取器网络架构[/caption]
技能提取器网络架构[/caption]Keras的实施方式如下:
class SkillsExtractorNN:
def __init__(self, word_features_dim, dense_features_dim):
lstm_input_phrase = keras.layers.Input(shape=(None, word_features_dim))
lstm_input_cont = keras.layers.Input(shape=(None, word_features_dim))
dense_input = keras.layers.Input(shape=(dense_features_dim,))
lstm_emb_phrase = keras.layers.LSTM(256)(lstm_input_phrase)
lstm_emb_phrase = keras.layers.Dense(128, activation='relu')(lstm_emb_phrase)
lstm_emb_cont = keras.layers.LSTM(256)(lstm_input_cont)
lstm_emb_cont = keras.layers.Dense(128, activation='relu')(lstm_emb_cont)
dense_emb = keras.layers.Dense(512, activation='relu')(dense_input)
dense_emb = keras.layers.Dense(256, activation='relu')(dense_emb)
x = keras.layers.concatenate([lstm_emb_phrase, lstm_emb_cont, dense_emb])
x = keras.layers.Dense(128, activation='relu')(x)
x = keras.layers.Dense(64, activation='relu')(x)
x = keras.layers.Dense(32, activation='relu')(x)
main_output = keras.layers.Dense(2, activation='softplus')(x)
self.model = keras.models.Model(inputs=[lstm_input_phrase, lstm_input_cont, dense_input],
outputs=main_output)
optimizer = keras.optimizers.Adam(lr=0.0001)
self.model.compile(optimizer=optimizer, loss='binary_crossentropy')
为了方便使用,我们加入fit方法进行神经网络训练,使用交叉验证和预测函数自动停止,形成候选短语特征向量的预测。在模型训练中,Adam优化器取得了较好的效果,学习速度降低到0.0001。我们选择binary_crossentropy作为损失函数,因为该模型被设计成分成两个类。
def fit(self, x_lstm_phrase, x_lstm_context, x_dense, y,
val_split=0.25, patience=5, max_epochs=1000, batch_size=32):
x_lstm_phrase_seq = keras.preprocessing.sequence.pad_sequences(x_lstm_phrase)
x_lstm_context_seq = keras.preprocessing.sequence.pad_sequences(x_lstm_context)
y_onehot = onehot_transform(y)
self.model.fit([x_lstm_phrase_seq, x_lstm_context_seq, x_dense],
y_onehot,
batch_size=batch_size,
pochs=max_epochs,
validation_split=val_split,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss', patience=patience)])
def predict(self, x_lstm_phrase, x_lstm_context, x_dense):
x_lstm_phrase_seq = keras.preprocessing.sequence.pad_sequences(x_lstm_phrase)
x_lstm_context_seq = keras.preprocessing.sequence.pad_sequences(x_lstm_context)
y = self.model.predict([x_lstm_phrase_seq, x_lstm_context_seq, x_dense])
return y
函数的作用是:将特征序列列表转换为二维数组,其宽度等于列表中最长的序列。这样做是为了将可变长度的数据带到LSTM层,使其达到模型训练所需的格式。
onehot_transformfunction将目标值0和1转换为一个热向量[1,0]和[0,1]
def onehot_transform(y):
onehot_y = []
for numb in y:
onehot_arr = np.zeros(2)
onehot_arr[numb] = 1
onehot_y.append(np.array(onehot_arr))
return np.array(onehot_y)
只要一个实体及其上下文中的单词数量是任意的,使用稀疏固定长度向量看起来就不合理。因此,处理任意长度向量的递归神经网络是一种非常方便和自然的解决方案。实验证明,采用密集层处理固定长度向量和LSTM层处理不同长度向量的结构是最优的。
几种体系结构已经通过不同的LSTM密层组合进行了测试。得到的体系结构配置(层的大小和数量)在交叉验证测试中显示出最好的结果,这对应于训练数据的最佳使用。进一步的模型调优可以通过增加训练数据集的大小以及适当地缩放层的大小和数量来执行,如果对相同的数据集使用后者,则会导致模型过度拟合。
结果
所有用于模型培训的CVs都来自IT行业。我们很高兴地看到,我们的模型在设计、金融等其他行业的CVs数据集上也显示出相当合理的性能。显然,处理结构和样式完全不同的CVs会导致模型性能下降。我们还想指出,我们对“技能”概念的理解可能与他人不同。对于我们的模型来说,其中一个困难的情况是区分新公司名称中的技能,因为技能通常等同于软件框架,有时您无法区分这是一个提到的启动名称,还是一个新的JS框架或Python库。然而,在大多数情况下,我们的模型可能是一个有用的工具,自动CV分析和一些统计方法可以解决广泛的数据科学任务上的任意CV资料库。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
数据科学家常犯的十大编程错误
下一篇
揭秘反向传播算法,原理介绍与理解








广告


写评论取消
回复取消