











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用Keras的Python深度学习模型的学习率方案
2017年08月05日 由 yuxiangyu 发表
23020
0
训练神经网络或大型深度学习模型是一项很难的优化任务。
传统的训练神经网络的算法称为随机梯度下降。你可以通过在训练中改变学习率来提高性能和提高训练速度。
在这篇文章中,你将了解如何使用Keras深度学习库在Python中使用不同的学习率方案。
看完这篇文章后,你会知道:
让我们开始吧。

调节随机梯度下降优化程序的学习率可以提高性能并减少训练时间。
这可能被称为学习率退火或学习率自适应。这里我们将这种方法称为学习率方案,它默认使用不变的学习率为每个训练周期更新网络权重。
在训练过程中,最简单也是最常用的学习率适应是随时间减小学习率的技术。当使用较大的学习率时,在训练过程的开始更新幅度很大,然后降低学习率,从而使训练过程中的训练更新变小。
它的效果是早期迅速学习权重,然后再进行微调。
两个流行和易于使用的学习率方案如下:
接下来,我们将介绍如何根据Keras使用这些学习率方案。
Keras有内置的基于时间的学习率方案。
随机梯度下降优化算法通过SGD类的一个称为衰变的参数实现。此参数用于基于时间的学习率衰减方案,方程如下:
当衰减参数为零(默认值)时,对学习率没有影响。
当指定衰减参数时,会让学习率从上一个周期减少给定的量。
例如,如果我们设置初始学习率为0.1,衰减为0.001,则前5个周期将调整学习率如下:
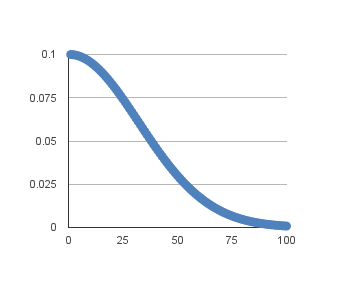
将其扩展到100个周期时,学习率(y轴)与周期(x轴)的变化图:
你可以通过设置衰减值来创建一个很好的默认方案,如下所示:
下面的示例演示了如何在Keras中使用基于时间的学习率适应方案。
它介绍了电离层二分类问题。这是一个可从UCI Machine Learning库下载的小型数据集。将数据文件放在你的工作目录中,文件名为“ionosphere.csv”。
电离层数据集适用于神经网络,因为所有输入值都是相同量纲的小的数字。
一个小的神经网络模型被有34个神经元的单独隐藏层构建,并用来纠正激活的函数。输出层具有单个神经元,并使用sigmoid激活函数来输出probability-like的值。
随机梯度下降的学习率设定为0.1。该模型训练了50个周期,衰变参数设置为0.002,计算为0.1 / 50。另外,在使用自适应学习率时,使用动量可能是一个好主意。在这种情况下,我们使用的动量值为0.8。
完整的示例如下所示:
# Time Based Learning Rate Decay
from pandas import read_csv
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
from sklearn.preprocessing import LabelEncoder
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load dataset
dataframe = read_csv("ionosphere.csv", header=None)
dataset = dataframe.values
# split into input (X) and output (Y) variables
X = dataset[:,0:34].astype(float)
Y = dataset[:,34]
# encode class values as integers
encoder = LabelEncoder()
encoder.fit(Y)
Y = encoder.transform(Y)
# create model
model = Sequential()
model.add(Dense(34, input_dim=34, kernel_initializer='normal', activation='relu'))
model.add(Dense(1, kernel_initializer='normal', activation='sigmoid'))
# Compile model
epochs = 50
learning_rate = 0.1
decay_rate = learning_rate / epochs
momentum = 0.8
sgd = SGD(lr=learning_rate, momentum=momentum, decay=decay_rate, nesterov=False)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
# Fit the model
model.fit(X, Y, validation_split=0.33, epochs=epochs, batch_size=28, verbose=2)
该模型对67%的数据集进行了训练,并使用33%的验证数据集进行了评估。
运行示例显示分类准确度为99.14%。这比没有学习速率衰减或动量的基线(95.69%)还要高。
使用深入学习模式的另一个流行的学习率方案是在训练周期特定次数下有计划的降低学习率。
通常这种方法是通过到每一个固定周期时学习率减半来实现的。例如,我们可能初始学习率为0.1,每10个周期下降0.5。前10个训练周期将使用0.01的值,在接下来的10个周期,将使用0.05的学习率,等等。
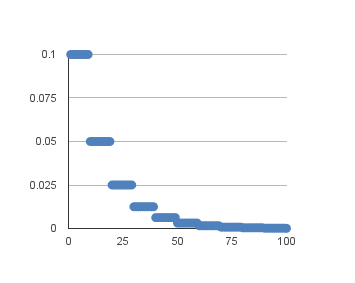
如果我们将这个例子的学习率绘制到100个周期,你可以得到下面的图表。显示学习率(y轴)与周期(x轴)的关系。
我们可以使用Keras中LearningRateScheduler回调来实现这个模型。
LearningRateScheduler回调允许我们定义要调用的函数,将周期数作为参数,并将学习率返回到随机梯度下降中使用。使用时,随机梯度下降指定的学习率被忽略不计。
在下面的代码中,我们在Ionosphere数据集上使用了与之前的例子一样的单一的隐藏层网络。定义了一个新的step_decay()函数,它实现了以下方程:
其中InitialLearningRate是初始学习率,如0.1,DropRate是每次改变时学习率修改的量,如0.5,Epoch是当前的周期数,EpochDrop是学习率改变的频率,如10 。
请注意,我们将SGD类中的学习率设置为0,以表明它不被使用。不过,如果你希望这种学习率方案中有动量,你可以在SGD中设定一个动量项。
运行该示例导致验证数据集的分类准确度为99.14%,现在再次对该模型的基线的改进
本节列出了使用神经网络学习率方案时需要考虑的一些提示和技巧。
阅读这篇文章后,你学到了:
原文:http://machinelearningmastery.com/using-learning-rate-schedules-deep-learning-models-python-keras/
传统的训练神经网络的算法称为随机梯度下降。你可以通过在训练中改变学习率来提高性能和提高训练速度。
在这篇文章中,你将了解如何使用Keras深度学习库在Python中使用不同的学习率方案。
看完这篇文章后,你会知道:
- 如何配置和评估time-based学习率方案。
- 如何配置和评估drop-based学习率方案。
让我们开始吧。
训练模型的学习率计划
调节随机梯度下降优化程序的学习率可以提高性能并减少训练时间。
这可能被称为学习率退火或学习率自适应。这里我们将这种方法称为学习率方案,它默认使用不变的学习率为每个训练周期更新网络权重。
在训练过程中,最简单也是最常用的学习率适应是随时间减小学习率的技术。当使用较大的学习率时,在训练过程的开始更新幅度很大,然后降低学习率,从而使训练过程中的训练更新变小。
它的效果是早期迅速学习权重,然后再进行微调。
两个流行和易于使用的学习率方案如下:
- 根据周期逐步降低学习率。
- 在特定周期,标记骤降学习率。
接下来,我们将介绍如何根据Keras使用这些学习率方案。
Time-Based学习率方案
Keras有内置的基于时间的学习率方案。
随机梯度下降优化算法通过SGD类的一个称为衰变的参数实现。此参数用于基于时间的学习率衰减方案,方程如下:
LearningRate = LearningRate * 1/(1 + decay * epoch)
当衰减参数为零(默认值)时,对学习率没有影响。
LearningRate = 0.1 * 1/(1 + 0.0 * 1)
LearningRate = 0.1
当指定衰减参数时,会让学习率从上一个周期减少给定的量。
例如,如果我们设置初始学习率为0.1,衰减为0.001,则前5个周期将调整学习率如下:
Epoch Learning Rate
1 0.1
2 0.0999000999
3 0.0997006985
4 0.09940249103
5 0.09900646517
将其扩展到100个周期时,学习率(y轴)与周期(x轴)的变化图:
你可以通过设置衰减值来创建一个很好的默认方案,如下所示:
Decay = LearningRate / Epochs
Decay = 0.1 / 100
Decay = 0.001
下面的示例演示了如何在Keras中使用基于时间的学习率适应方案。
它介绍了电离层二分类问题。这是一个可从UCI Machine Learning库下载的小型数据集。将数据文件放在你的工作目录中,文件名为“ionosphere.csv”。
电离层数据集适用于神经网络,因为所有输入值都是相同量纲的小的数字。
一个小的神经网络模型被有34个神经元的单独隐藏层构建,并用来纠正激活的函数。输出层具有单个神经元,并使用sigmoid激活函数来输出probability-like的值。
随机梯度下降的学习率设定为0.1。该模型训练了50个周期,衰变参数设置为0.002,计算为0.1 / 50。另外,在使用自适应学习率时,使用动量可能是一个好主意。在这种情况下,我们使用的动量值为0.8。
完整的示例如下所示:
# Time Based Learning Rate Decay
from pandas import read_csv
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
from sklearn.preprocessing import LabelEncoder
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load dataset
dataframe = read_csv("ionosphere.csv", header=None)
dataset = dataframe.values
# split into input (X) and output (Y) variables
X = dataset[:,0:34].astype(float)
Y = dataset[:,34]
# encode class values as integers
encoder = LabelEncoder()
encoder.fit(Y)
Y = encoder.transform(Y)
# create model
model = Sequential()
model.add(Dense(34, input_dim=34, kernel_initializer='normal', activation='relu'))
model.add(Dense(1, kernel_initializer='normal', activation='sigmoid'))
# Compile model
epochs = 50
learning_rate = 0.1
decay_rate = learning_rate / epochs
momentum = 0.8
sgd = SGD(lr=learning_rate, momentum=momentum, decay=decay_rate, nesterov=False)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
# Fit the model
model.fit(X, Y, validation_split=0.33, epochs=epochs, batch_size=28, verbose=2)
该模型对67%的数据集进行了训练,并使用33%的验证数据集进行了评估。
运行示例显示分类准确度为99.14%。这比没有学习速率衰减或动量的基线(95.69%)还要高。
...
Epoch 45/50
0s - loss: 0.0622 - acc: 0.9830 - val_loss: 0.0929 - val_acc: 0.9914
Epoch 46/50
0s - loss: 0.0695 - acc: 0.9830 - val_loss: 0.0693 - val_acc: 0.9828
Epoch 47/50
0s - loss: 0.0669 - acc: 0.9872 - val_loss: 0.0616 - val_acc: 0.9828
Epoch 48/50
0s - loss: 0.0632 - acc: 0.9830 - val_loss: 0.0824 - val_acc: 0.9914
Epoch 49/50
0s - loss: 0.0590 - acc: 0.9830 - val_loss: 0.0772 - val_acc: 0.9828
Epoch 50/50
0s - loss: 0.0592 - acc: 0.9872 - val_loss: 0.0639 - val_acc: 0.9828
Drop-Based学习率方案
使用深入学习模式的另一个流行的学习率方案是在训练周期特定次数下有计划的降低学习率。
通常这种方法是通过到每一个固定周期时学习率减半来实现的。例如,我们可能初始学习率为0.1,每10个周期下降0.5。前10个训练周期将使用0.01的值,在接下来的10个周期,将使用0.05的学习率,等等。
如果我们将这个例子的学习率绘制到100个周期,你可以得到下面的图表。显示学习率(y轴)与周期(x轴)的关系。
我们可以使用Keras中LearningRateScheduler回调来实现这个模型。
LearningRateScheduler回调允许我们定义要调用的函数,将周期数作为参数,并将学习率返回到随机梯度下降中使用。使用时,随机梯度下降指定的学习率被忽略不计。
在下面的代码中,我们在Ionosphere数据集上使用了与之前的例子一样的单一的隐藏层网络。定义了一个新的step_decay()函数,它实现了以下方程:
LearningRate = InitialLearningRate * DropRate^floor(Epoch / EpochDrop)
其中InitialLearningRate是初始学习率,如0.1,DropRate是每次改变时学习率修改的量,如0.5,Epoch是当前的周期数,EpochDrop是学习率改变的频率,如10 。
请注意,我们将SGD类中的学习率设置为0,以表明它不被使用。不过,如果你希望这种学习率方案中有动量,你可以在SGD中设定一个动量项。
# Drop-Based Learning Rate Decay
import pandas
from pandas import read_csv
import numpy
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
from sklearn.preprocessing import LabelEncoder
from keras.callbacks import LearningRateScheduler
# learning rate schedule
def step_decay(epoch):
initial_lrate = 0.1
drop = 0.5
epochs_drop = 10.0
lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lrate
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load dataset
dataframe = read_csv("ionosphere.csv", header=None)
dataset = dataframe.values
# split into input (X) and output (Y) variables
X = dataset[:,0:34].astype(float)
Y = dataset[:,34]
# encode class values as integers
encoder = LabelEncoder()
encoder.fit(Y)
Y = encoder.transform(Y)
# create model
model = Sequential()
model.add(Dense(34, input_dim=34, kernel_initializer='normal', activation='relu'))
model.add(Dense(1, kernel_initializer='normal', activation='sigmoid'))
# Compile model
sgd = SGD(lr=0.0, momentum=0.9, decay=0.0, nesterov=False)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
# learning schedule callback
lrate = LearningRateScheduler(step_decay)
callbacks_list = [lrate]
# Fit the model
model.fit(X, Y, validation_split=0.33, epochs=50, batch_size=28, callbacks=callbacks_list, verbose=2)
运行该示例导致验证数据集的分类准确度为99.14%,现在再次对该模型的基线的改进
...
Epoch 45/50
0s - loss: 0.0546 - acc: 0.9830 - val_loss: 0.0634 - val_acc: 0.9914
Epoch 46/50
0s - loss: 0.0544 - acc: 0.9872 - val_loss: 0.0638 - val_acc: 0.9914
Epoch 47/50
0s - loss: 0.0553 - acc: 0.9872 - val_loss: 0.0696 - val_acc: 0.9914
Epoch 48/50
0s - loss: 0.0537 - acc: 0.9872 - val_loss: 0.0675 - val_acc: 0.9914
Epoch 49/50
0s - loss: 0.0537 - acc: 0.9872 - val_loss: 0.0636 - val_acc: 0.9914
Epoch 50/50
0s - loss: 0.0534 - acc: 0.9872 - val_loss: 0.0679 - val_acc: 0.9914
使用学习率方案的提示
本节列出了使用神经网络学习率方案时需要考虑的一些提示和技巧。
- 提高初始学习率。因为学习率极有可能从更大的值中下降,至少在开始时一个更大的学习率会让权重变化更大,允许你从之后的微调中受益。
- 使用大的动量。使用更大的动量值将有助于优化算法在学习率缩小到小值时,继续向正确的方向更新。
- 尝试不同的方案。因为我们不清楚哪种学习率方案最适合你的问题,所以要尝试不用的配置选项。另外,你也可以试着以指数方式改变它,甚至改变那些对你在训练或测试数据集上的模型准确性做出反应的方案。
总结
阅读这篇文章后,你学到了:
- 如何配置和评估time-based学习率方案。
- 如何配置和评估drop-based学习率方案。
原文:http://machinelearningmastery.com/using-learning-rate-schedules-deep-learning-models-python-keras/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消