











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






深度理解和可视化ResNets
2019年05月25日 由 深深深海 发表
249183
0
 研究人员观察到,当涉及卷积神经网络时,越深越好是有意义的。因为模型应该更有能力(它们适应任何空间的灵活性增加,因为它们有更大的参数空间可供探索)。
研究人员观察到,当涉及卷积神经网络时,越深越好是有意义的。因为模型应该更有能力(它们适应任何空间的灵活性增加,因为它们有更大的参数空间可供探索)。然而,人们注意到,在一定的深度之后,性能会下降。这是VGG的瓶颈之一。它们不能像我们想要的那样深入,因为它们开始失去泛化能力。
动机
由于神经网络是良好的函数近似器,它们应该能够轻松地解决识别函数,其中函数的输出变为输入本身。
遵循相同的逻辑,如果我们绕过模型的第一层的输入,将其作为模型的最后一层的输出,网络应该能够预测它之前学习的任何函数,并将输入添加其中。
直觉告诉我们,学习f(x)= 0对网络来说很容易。
ResNets解决了什么问题
ResNets解决的问题之一是消失梯度。这是因为当网络太深时,经过链式法则的多次应用,计算损失函数的梯度很容易缩小到零。在权重上的结果没有更新其值,因此没有执行任何学习中。
使用ResNets,梯度可以直接向后跳过连接,从后面的层向后流动到初始过滤器。
架构
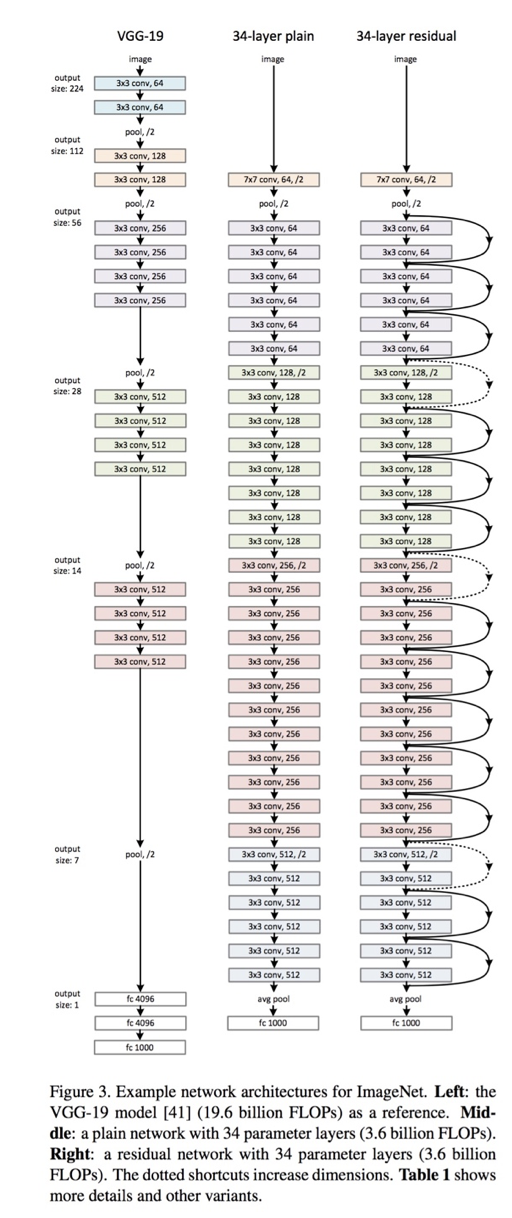
图1.原始论文中的ResNet 34
由于ResNet大小不同,取决于模型的每一层有多大,以及它有多少层,为了解释这些网络之后的结构,我们将遵循作者在论文中描述的。
如果你看了这篇论文,你可能会看到一些像以下那样的数字和表格,让我们详细了解每一步来描述这些数字。
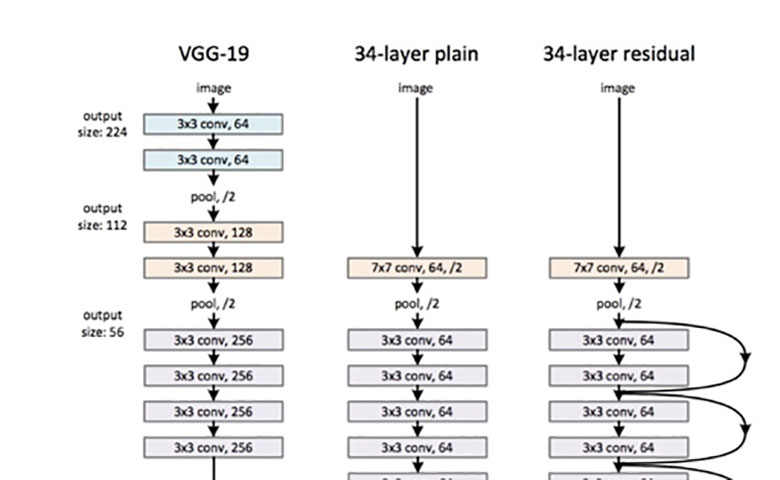
在这里,我们可以看到ResNet(右边)包含一个卷积和池化步骤(橙色),然后是4层相似的行为。
每一层遵循相同的模式,它们分别使用固定的特征映射维度(F)[64,128,256,512]执行3x3卷积,每2次卷积绕过输入。此外,宽度(W)和高度(H)在整个层中保持恒定。
虚线是因为输入体积的尺寸发生了变化(当然由于卷积而减少)。注意,层之间的这种减少是通过在每层的第一次卷积时步幅从1增加到2来实现的,而不是通过池运算,我们通常将池运算视为向下采样器。
表中总结了每一层的输出大小和结构中每一点卷积核的维数。
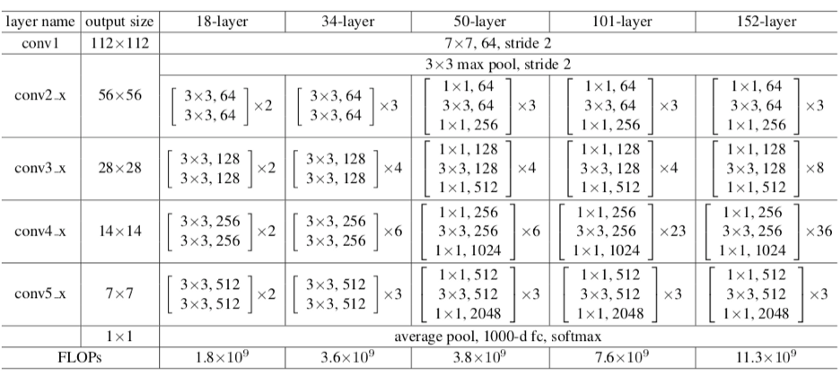
图2. ResNet 34的输出和卷积内核的大小
但这是不可见的。我们想要图像,一张图片胜过千言万语!
下文中的图3是我喜欢看卷积模型的方式,我将从中解释每一层。
我更倾向于观察实际通过模型的体积是如何改变它们的大小的。这种方法更容易理解特定模型的机制,能够根据我们的特定需求调整它,我们将看到仅仅更改数据集就会强制更改整个模型的体系结构。此外,我将尝试遵循与PyTorch官方实现相近的符号,以便稍后在PyTorch上实现它。
例如,论文主要针对ImageNet数据集解释了ResNet。但是我第一次想要使用ResNets的套装进行实验时,我必须在CIFAR10上进行。显然,由于CIFAR10输入图像是(32x32)而不是(224x224),因此需要修改ResNets的结构。
如果你希望控制修改以应用于ResNet,则需要了解详细信息。这个教程是应用于CIFAR10的当前教程的简化版。
那么,让我们一层一层看吧!
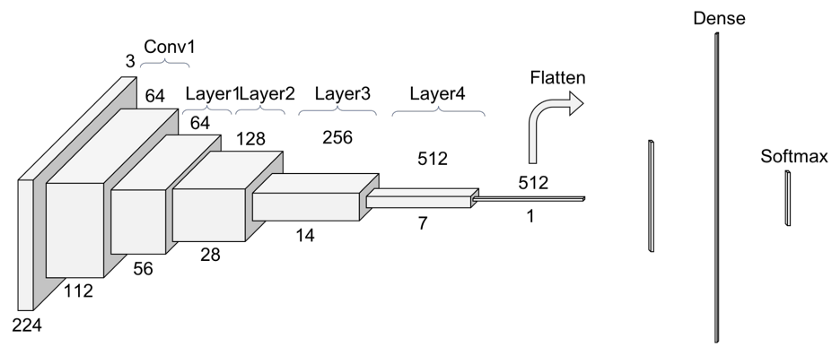
图3. ResNet 34的另一个视图
卷积1
在进入公共层行为之前,在ResNet上进行的第一步是一个块,在此称为Conv1,由卷积+批量标准化+最大池运算组成。
所以,首先是卷积运算。在图1中,我们可以看到它们使用的内核大小为7,特征映射大小为64。你需要推断它们在每个维度上都填充了3次0,并在PyTorch文档中进行检查。
考虑到这一点,在图4中可以看出该运算的输出大小将是(112×122) 。由于每个卷积滤波器(64位)在输出体积 中提供一个通道,我们最终得到一个(112x112x64)输出体积 ,注意,这与简化解释的批量维度无关。
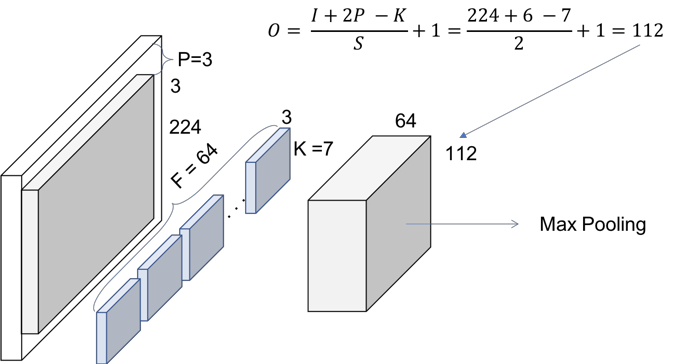
图4. Conv1—卷积
下一步是批量标准化,它不会更改体积大小。最后,我们有(3x3)最大池化运算,步幅为2。我们还可以推断,它们首先填充输入的体积,因此最终的体积具有所需的尺寸。
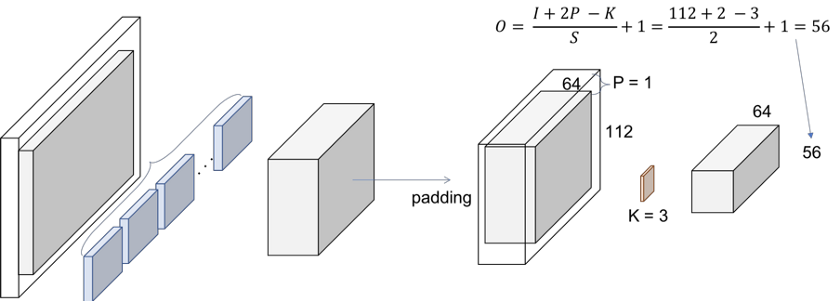
图5. Conv1—最大池化
ResNet层
那么,让我们解释这个重复的名称——块。ResNet的每一层都由几个块组成。这是因为当ResNets更深入时,它们通常通过增加块内的运算数来实现,但总层数仍为4. 此处的运算是指卷积的批量标准化和ReLU激活到输入,除了块的最后一个运算,该运算没有ReLU。
因此,在PyTorch实现中,他们区分包含2个运算的块:基本块,以及包含3个运算的块:瓶颈块。请注意,通常每个运算都称为层,但我们已经将层用于一组块中。
我们现在正面临一个基本的问题。输入体积是Conv1的最后一个输出体积。让我们看看图6,找出这个块里面发生了什么。
块1
1卷积
我们正在复制纸上每一层的简化运算。
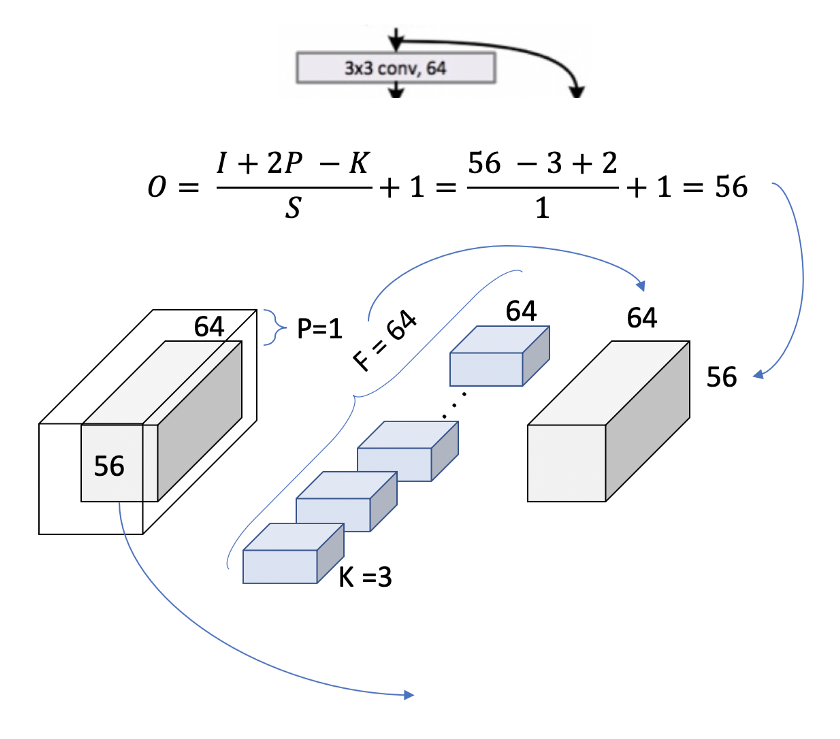
图6.层1,块1,运算1
我们现在可以在表中使用[3x3,64]内核进行双重检查,输出大小为[56x56]。我们可以看到,卷积的大小在块内不会发生变化。这是因为使用填充= 1并且步幅也是1。让我们看看它如何扩展到整个块,以覆盖表中出现的2 [3x3,64]。
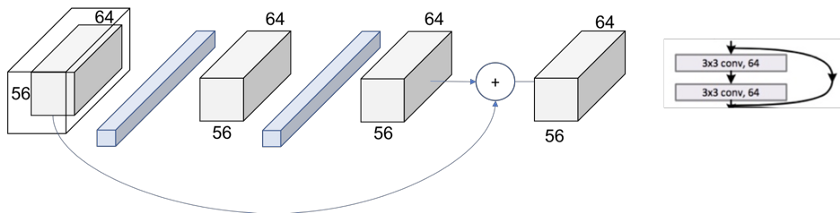
图7.层1,块1
相同的过程可以扩展到整个层,然后如图8所示。现在,我们可以完全读取表的整个单元格。
我们可以看到在层内有[3x3,64] x 3次。

图8.层1
模式
下一步是从整个块升级到整个层。在图1中,我们可以看到各层如何通过颜色区分。但是,如果我们看一下每一层的第一个运算,我们会发现第一个层使用的步长是2,而不是其他层使用的1。
这意味着通过网络对卷进行下采样是通过增加步长来实现的,而不是像CNN那样的池化运算。事实上,在我们的Conv1层中只执行了一次最大池运算,而在ResNet的末尾,即图1中完全连接的密集层之前,只执行一个平均池运算。
我们还可以看到ResNet层上的另一种重复模式,即表示维度变化的点层,这和我们刚才说的一致。每个层的第一个运算是减小维度,因此我们还需要调整通过跳过连接的卷积的大小,这样我们就可以像图7那样添加它们。
跳过连接的这种差异在文中被称为Identity Shortcut和Projection Shortcut。Identity Shortcut是我们已经讨论过的,只需将输入体积绕过加法运算符即可。Projection Shortcut执行卷积运算,以确保此加法运算中的体积大小相同。从论文中我们可以看到有两个选项可以匹配输出大小。或者填充的输入体积或执行的1x1卷积。这里显示了第二个选项。
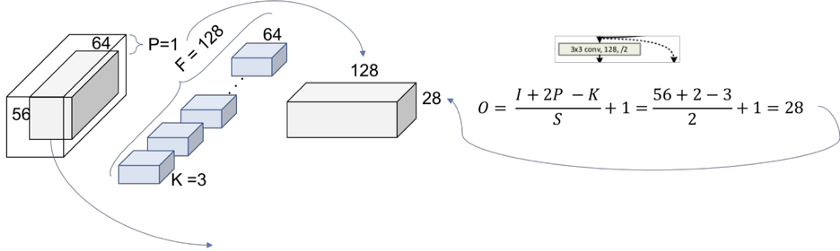
图9. 层2,块1,运算1
图9表示通过将步长增加到2而执行的向下采样。重复过滤器的数量是为了保持每个运算的时间复杂度(56 * 64 = 28 * 128)。注意,由于体积已被修改,因此现在无法执行加法运算。在Shortcut中,我们需要应用一种向下采样策略。1x1卷积方法如图10所示。
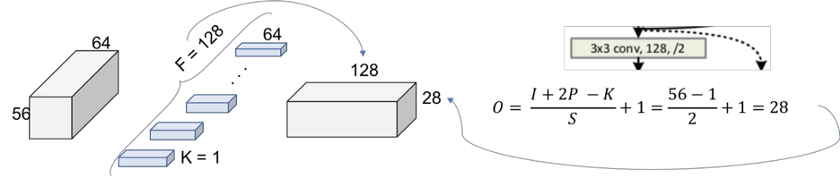
图10.Projection Shortcut
最后的图如图11所示,现在每个线程的2个输出体积具有相同大小并且可以添加。
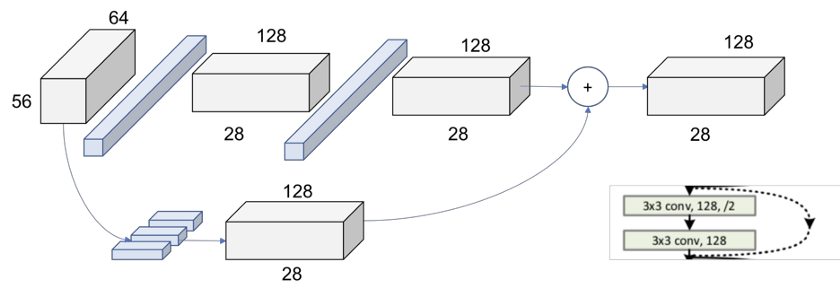
图11.层2,块1
在图12中,我们可以看到整个第二层的全局图。对于以下第3层和第4层,操作完全相同,仅更改传入体积的尺寸。
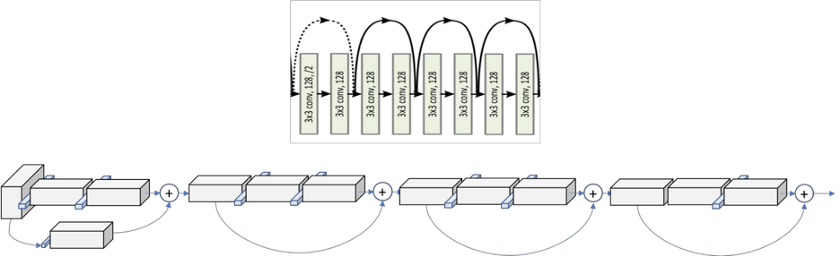
图12.层2
总结
ResNets遵循由作者构建的解释规则,顺应如下结构,如图2所示:
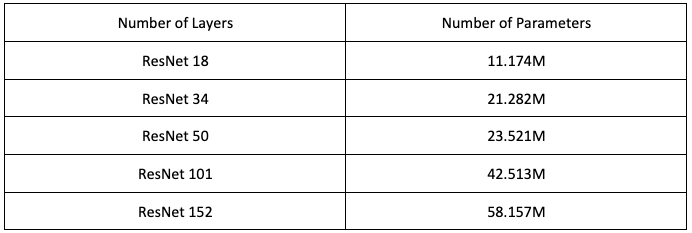
表1.对于ImageNet的ResNets架构

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消