











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






CapeAnalytics:AI生成的数据质量评估
2019年05月22日 由 Oshor 发表
444456
0
机器在过去十年中产生的数据量惊人。但是,为了确定如何将数据合并到业务流程中并用于通知决策,彻底了解数据的质量是至关重要的。但是,如何判断质量,特别是当数据集来自复杂的算法或人工智能模型时?
数据质量有许多方面,它通常被定义为准确性。简而言之,数据反映的是真实世界吗?准确性的子集包括关于数据完整性和数据中不一致性的问题。第二个因素是数据的可预测性。这些数据能告诉我们一些潜在的结果吗?
在本系列文章中,我们将介绍帮助企业判断人工智能生成数据源的准确性、可预测性、一致性和及时性的概念和想法,以及每一个概念和想法如何影响决策能力。
无论数据是人工生成的还是机器生成的,任何大型数据集中都会有错误。实际上,没有数据源是完全正确的。无论数据是用于保险、医疗保健还是其他领域,都应该考虑错误的分布和普遍性。如果可以对错误进行特征化和理解,则可以将数据集最佳地用于决策目的,因为错误不再被视为随机分布在数据集之间。在观察错误时,重要的是要考虑到有两种不同的类型:I型(假阳性)和II型(假阴性)。
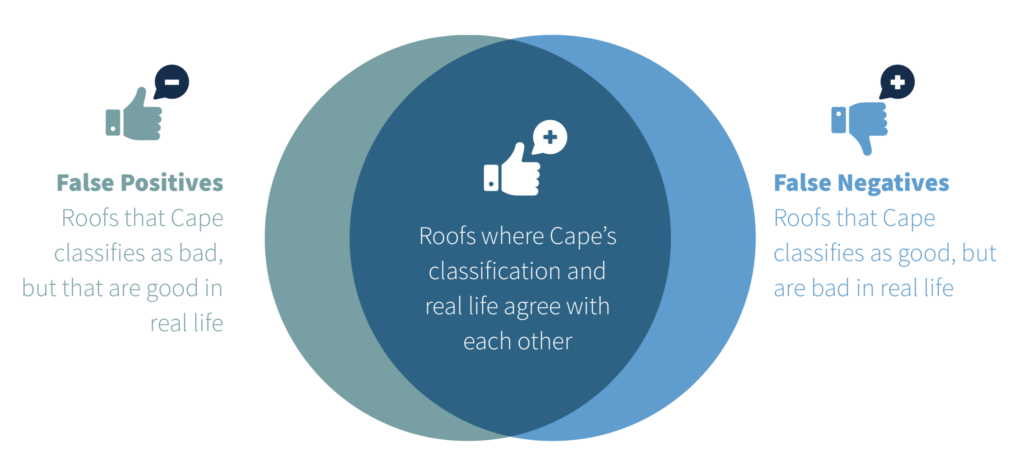
下面是一个简单的例子,展示了人工智能模型中的假阳性和阴性会如何表现出来,这个模型精确定位了屋顶质量差(屋顶被分类为好或坏)。
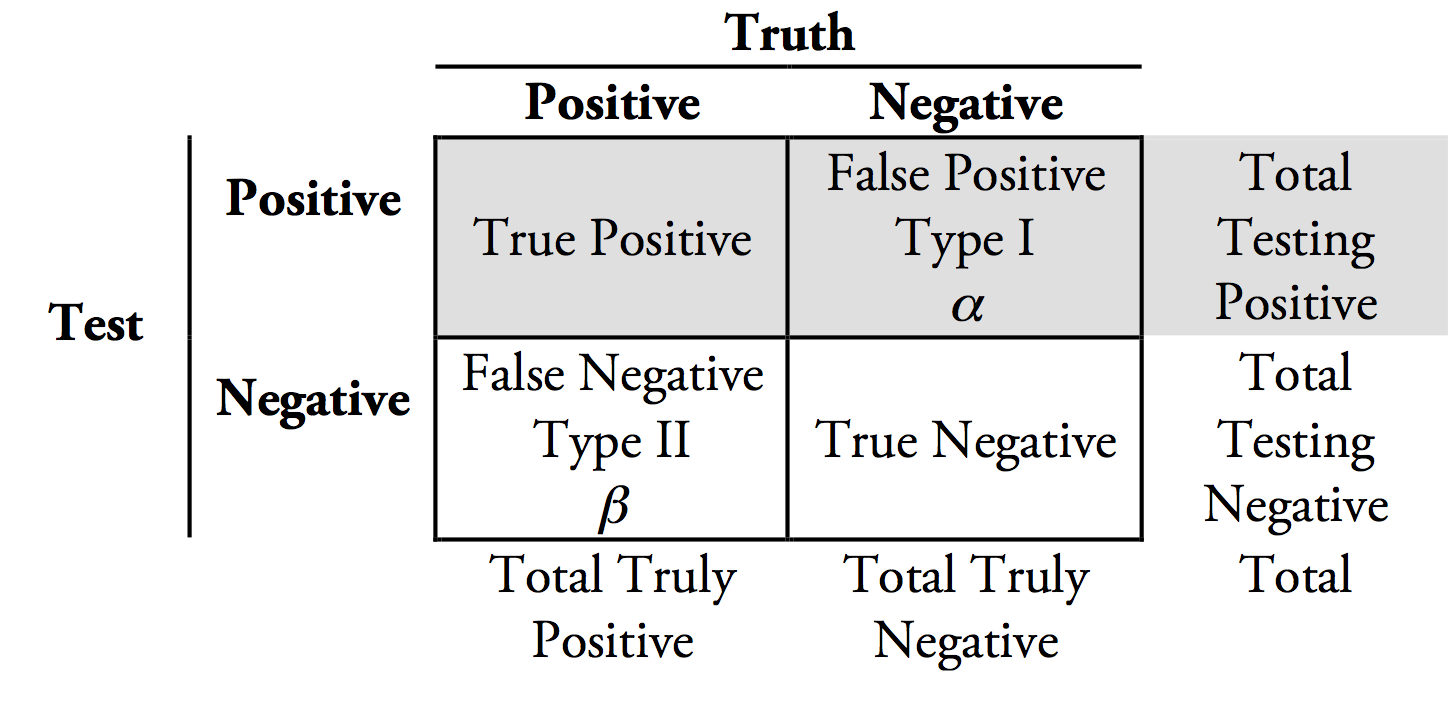
事实上,假阳性和阴性是一个更大的概念框架的一部分,这是机器学习的基础。这个框架称为混淆矩阵,如下所示:
通常,模型输出是假阳性和假阴性之间的权衡,学习模型可以优化以最小化其中一个或另一个。当集成到业务决策中时,数据集中的两种错误可能具有不同的影响。因此,通过优化一个模型并将大多数错误降为单个类型,用户可以对模型结果有更多的信心,并且知道需要寻找什么潜在的问题。为了理解这是如何做到的,我们需要更深入地了解精确和回忆的概念。
精度描述了模型输出的纯度:正确结果的百分比。专注于精确性的模型将假阳性最小化。
另一方面,回顾描述了模型输出的完整性:模型正确返回的所有可能的正结果的百分比。一个专注于回忆的模型可以最小化错误的否定。
在示例中使用这些概念更容易理解。
假设有一位医生正在解释100次血液测试,并决定是否有疾病存在。在这种情况下,疾病的出现是一个积极的结果,没有疾病是一个消极的结果。如果医生对检查结果进行分析,确认一种疾病40次,但只有30次是正确的,那么她的准确率将为75%(30/40*100)。其中10例为假阳性,即使患者健康,也会被诊断为疾病。如果在100个测试中有50个病例,并且她正确诊断了其中30个,那么她的准确率将是60%(30/50*100)。20名患者接受了假阴性诊断:他们患有该病,但被告知他们健康。
在这里,我们可以清楚地看到在任何一个方向错误的不同代价。在这种情况下,很重要的一点是要有高的回忆能力,因此有疾病的人有最高的机会接受有益的治疗,即使这是以一些健康的人被误诊为代价的。
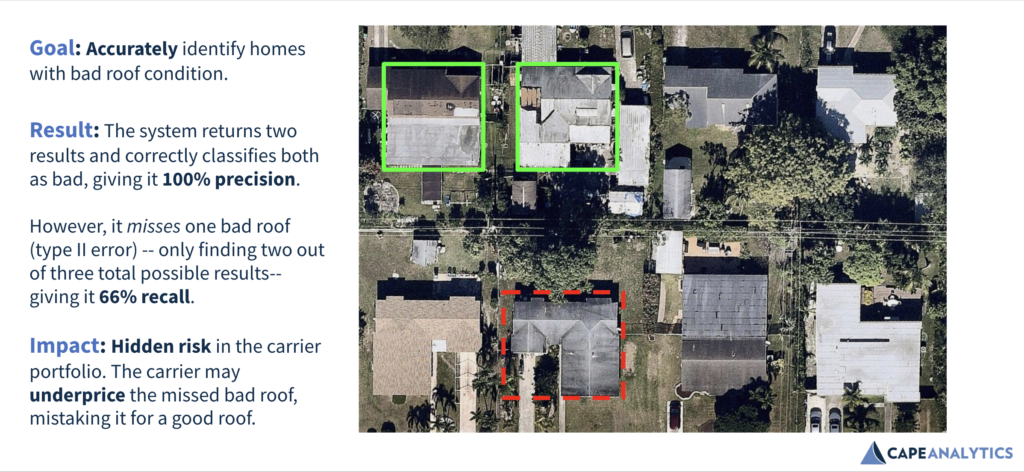
让我们将精确性和召回应用于保险用例。以下是针对精确性调整的机器学习模型的结果,保险公司希望Cape在识别不良屋顶条件(评估准确性)时尽量减少出错的机会。
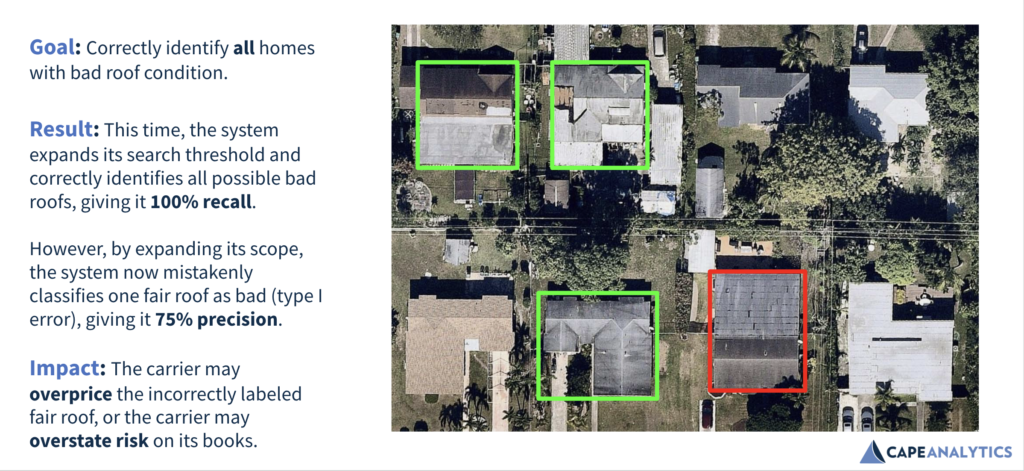
接下来是一个为召回而优化的模型的例子,用户希望在整个数据集中最小化丢失坏屋顶的可能性(评估完整性)。
这个例子展示了最小化误报(精确性)和最小化误报(召回)之间的权衡,以及一个用例对某些用例可能更好,而对其他用例可能更差。如果用户知道数据集最有可能出错的方向,那么他们可以选择一个用例,在这个方向出错的成本低于在另一个方向出错的成本。
例如,在Cape,我们设计了具有高召回率的车顶状况评级模型,并建议运营商使用该模型将大型政策投资组合过滤为其承销商应审查的少量潜在不良风险。在这个用例中,我们希望避免让不好的风险“从裂缝中溜走”,因为一个高质量屋顶被定价为高质量屋顶的成本在未来可能会导致比预期更大的损失。
另一方面,保险公司在自动化关键业务决策时,如在应用时拒绝客户、仅基于数据而不进行任何人工审查时,希望获得高精度。在这种情况下,保险公司需要精确性,以便最大限度地减少将好的风险错误地分类为坏的风险,以及在这一过程中失去好的潜在客户的可能性。
随着时间的推移,提高模型精度或召回的能力会对数据的有用性产生很大的下游影响。在Cape Analytics,我们不断改进我们的模型,以提高精度和召回率,并为客户提供可用于定制实施的额外元数据。仅在2018年,我们就将损失预测屋顶状况评分属性的精度提高了30%,从而最大限度地减少了所有的误报。这种持续的改进使我们的客户有信心知道他们正在使用当今市场上最好的数据。
混淆矩阵、误报和否定、精确与回忆,这些概念帮助我们了解如何测量数据准确性。不过,正如引言中提到的,精度只是方程式的一部分。另一个主要因素是数据的可预测性。数据是否提供了一些能够帮助我们预测未来客户行为或结果的信号?
在本系列的第二部分中,我们将深入讨论这个以及更多内容。
数据质量有许多方面,它通常被定义为准确性。简而言之,数据反映的是真实世界吗?准确性的子集包括关于数据完整性和数据中不一致性的问题。第二个因素是数据的可预测性。这些数据能告诉我们一些潜在的结果吗?
在本系列文章中,我们将介绍帮助企业判断人工智能生成数据源的准确性、可预测性、一致性和及时性的概念和想法,以及每一个概念和想法如何影响决策能力。
无论数据是人工生成的还是机器生成的,任何大型数据集中都会有错误。实际上,没有数据源是完全正确的。无论数据是用于保险、医疗保健还是其他领域,都应该考虑错误的分布和普遍性。如果可以对错误进行特征化和理解,则可以将数据集最佳地用于决策目的,因为错误不再被视为随机分布在数据集之间。在观察错误时,重要的是要考虑到有两种不同的类型:I型(假阳性)和II型(假阴性)。
下面是一个简单的例子,展示了人工智能模型中的假阳性和阴性会如何表现出来,这个模型精确定位了屋顶质量差(屋顶被分类为好或坏)。
事实上,假阳性和阴性是一个更大的概念框架的一部分,这是机器学习的基础。这个框架称为混淆矩阵,如下所示:
通常,模型输出是假阳性和假阴性之间的权衡,学习模型可以优化以最小化其中一个或另一个。当集成到业务决策中时,数据集中的两种错误可能具有不同的影响。因此,通过优化一个模型并将大多数错误降为单个类型,用户可以对模型结果有更多的信心,并且知道需要寻找什么潜在的问题。为了理解这是如何做到的,我们需要更深入地了解精确和回忆的概念。
精度描述了模型输出的纯度:正确结果的百分比。专注于精确性的模型将假阳性最小化。
另一方面,回顾描述了模型输出的完整性:模型正确返回的所有可能的正结果的百分比。一个专注于回忆的模型可以最小化错误的否定。
在示例中使用这些概念更容易理解。
假设有一位医生正在解释100次血液测试,并决定是否有疾病存在。在这种情况下,疾病的出现是一个积极的结果,没有疾病是一个消极的结果。如果医生对检查结果进行分析,确认一种疾病40次,但只有30次是正确的,那么她的准确率将为75%(30/40*100)。其中10例为假阳性,即使患者健康,也会被诊断为疾病。如果在100个测试中有50个病例,并且她正确诊断了其中30个,那么她的准确率将是60%(30/50*100)。20名患者接受了假阴性诊断:他们患有该病,但被告知他们健康。
在这里,我们可以清楚地看到在任何一个方向错误的不同代价。在这种情况下,很重要的一点是要有高的回忆能力,因此有疾病的人有最高的机会接受有益的治疗,即使这是以一些健康的人被误诊为代价的。
让我们将精确性和召回应用于保险用例。以下是针对精确性调整的机器学习模型的结果,保险公司希望Cape在识别不良屋顶条件(评估准确性)时尽量减少出错的机会。
接下来是一个为召回而优化的模型的例子,用户希望在整个数据集中最小化丢失坏屋顶的可能性(评估完整性)。
这个例子展示了最小化误报(精确性)和最小化误报(召回)之间的权衡,以及一个用例对某些用例可能更好,而对其他用例可能更差。如果用户知道数据集最有可能出错的方向,那么他们可以选择一个用例,在这个方向出错的成本低于在另一个方向出错的成本。
例如,在Cape,我们设计了具有高召回率的车顶状况评级模型,并建议运营商使用该模型将大型政策投资组合过滤为其承销商应审查的少量潜在不良风险。在这个用例中,我们希望避免让不好的风险“从裂缝中溜走”,因为一个高质量屋顶被定价为高质量屋顶的成本在未来可能会导致比预期更大的损失。
另一方面,保险公司在自动化关键业务决策时,如在应用时拒绝客户、仅基于数据而不进行任何人工审查时,希望获得高精度。在这种情况下,保险公司需要精确性,以便最大限度地减少将好的风险错误地分类为坏的风险,以及在这一过程中失去好的潜在客户的可能性。
随着时间的推移,提高模型精度或召回的能力会对数据的有用性产生很大的下游影响。在Cape Analytics,我们不断改进我们的模型,以提高精度和召回率,并为客户提供可用于定制实施的额外元数据。仅在2018年,我们就将损失预测屋顶状况评分属性的精度提高了30%,从而最大限度地减少了所有的误报。这种持续的改进使我们的客户有信心知道他们正在使用当今市场上最好的数据。
混淆矩阵、误报和否定、精确与回忆,这些概念帮助我们了解如何测量数据准确性。不过,正如引言中提到的,精度只是方程式的一部分。另一个主要因素是数据的可预测性。数据是否提供了一些能够帮助我们预测未来客户行为或结果的信号?
在本系列的第二部分中,我们将深入讨论这个以及更多内容。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消