











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






DataRobot和葡萄酒项目:数据科学的优雅融合
2019年05月24日 由 人工智能爱好者 发表
709444
0

DataRobot承诺自动机器学习,其中它选择最合适的机器学习算法,自动优化数据预处理,应用特征工程,并调整每个算法的参数。它创建并排列高度精确的模型,并为数据和预测目标推荐要部署的最佳模型。所以,当使用DataRobot的机会出现时,我决定尝试一下。
在本教程中,我使用了UCI机器学习库中的葡萄酒质量数据集,该数据集包含4898种白葡萄酒样品的质量评级(标签)。这些质量等级从3到9不等,其中9表示葡萄酒的最佳质量。有了这些不同的标签,我将其视为一个多类分类问题。为了简单,我将其转换为三个不同的类别(low=[3,4,5],med=[6],high=[7,8,9])。其特点是葡萄酒的理化性质(共11个),我们利用这些理化性质来预测葡萄酒的质量。最后,我将数据分为两组,一组是培训数据集,另一组是测试数据集,以演示对新数据进行预测。DataRobot期望训练数据以平面文件的形式出现。对于这里使用的葡萄酒数据集,所需的准备工作非常少,您可以在Github上找到此教程的完整代码,了解中间步骤。
准备好培训数据并通过我的Python会话建立连接后,我创建了三个不同的项目来展示DataRobot在我的数据上可以使用的三种不同模式。分别是全自动驾驶模式、快速自动驾驶模式和手动模式。我称之为三个项目对应的三种模式:项目_Wine1、项目_Wine2和项目_Wine3。培训过程完成后,我将演示如何从各种模型中检索结果,以及如何使用所选模型生成新数据的预测。
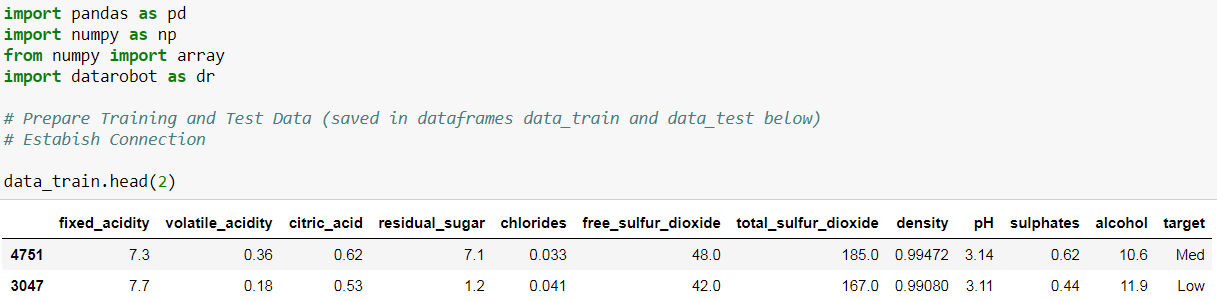
自动驾驶模式
当一个给定的数据集,datarobot开始recommending A市的blueprints那是适当的任务的所有权利。图A是一系列的步骤或一paths,该数据集将通过市场会有这种预期从之前的生产数据。有可能为多blueprints同样取决于标的算法的预处理步骤,你可以杠杆和一个或更多的与他们的模型参数自动调谐。datarobot定义城市ITS模型冰的蓝图,训练数据的大小和特点。
在跑第一项目对全自动驾驶模式。在自动驾驶模式(这是默认的模式也在datarobot)和对这种特殊数据集,datarobot生成22和28 blueprints方式在这些blueprints模型中。
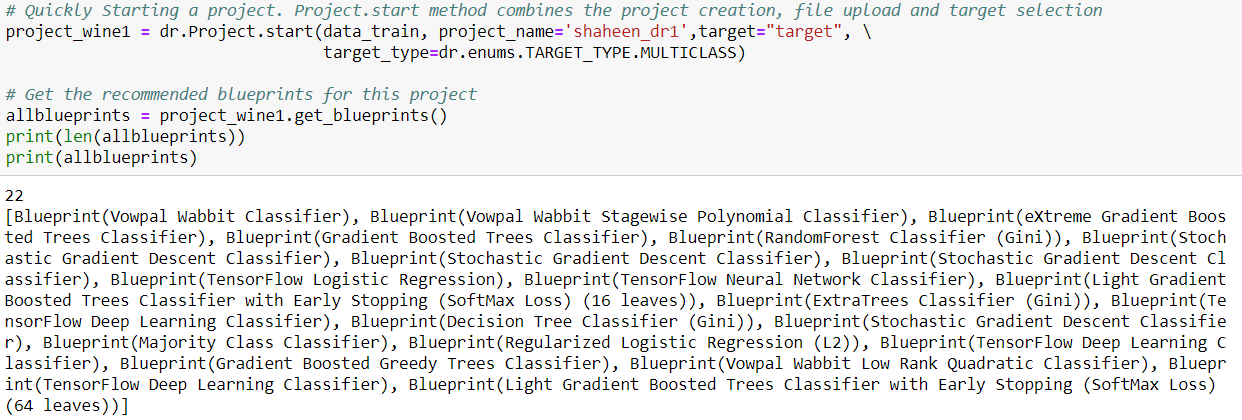
我比较的使用精度度量创建的所有模型,然后选择了一个模型并详细检查了它的性能。然后,我上传了上面的测试数据,用这个模型得到结果。
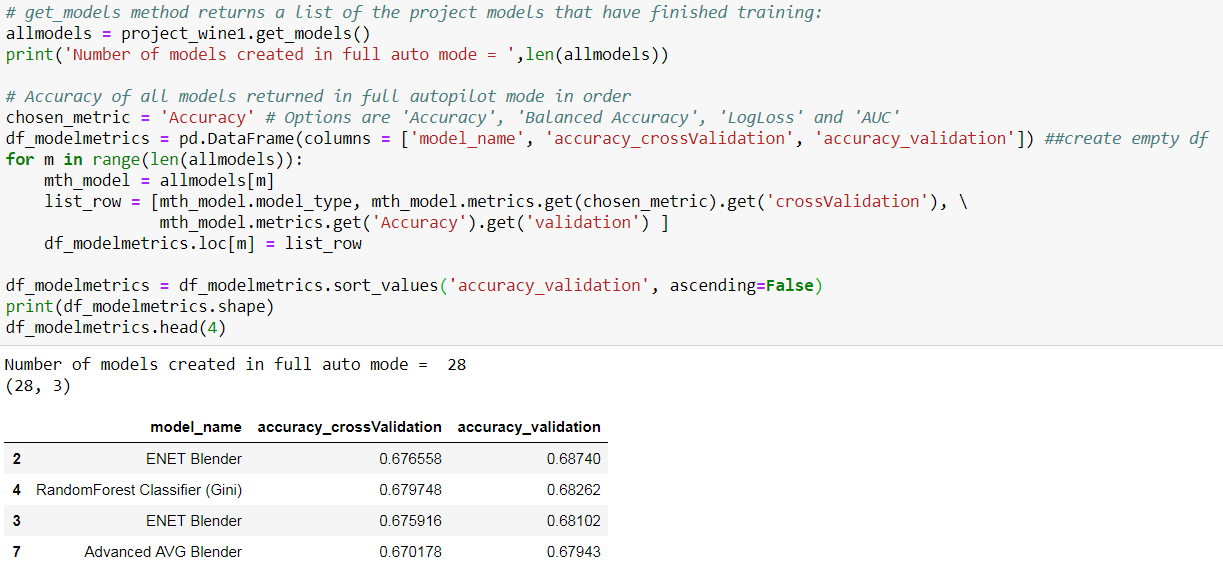
接下来,我发现了一个极端梯度增强模型,并详细检查了模型的度量,并用它来预测测试数据。
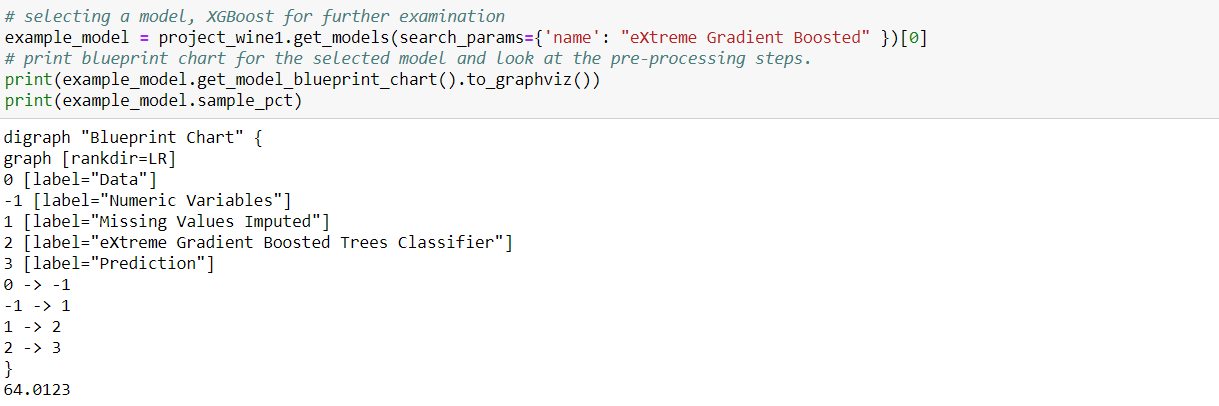
培训数据表现
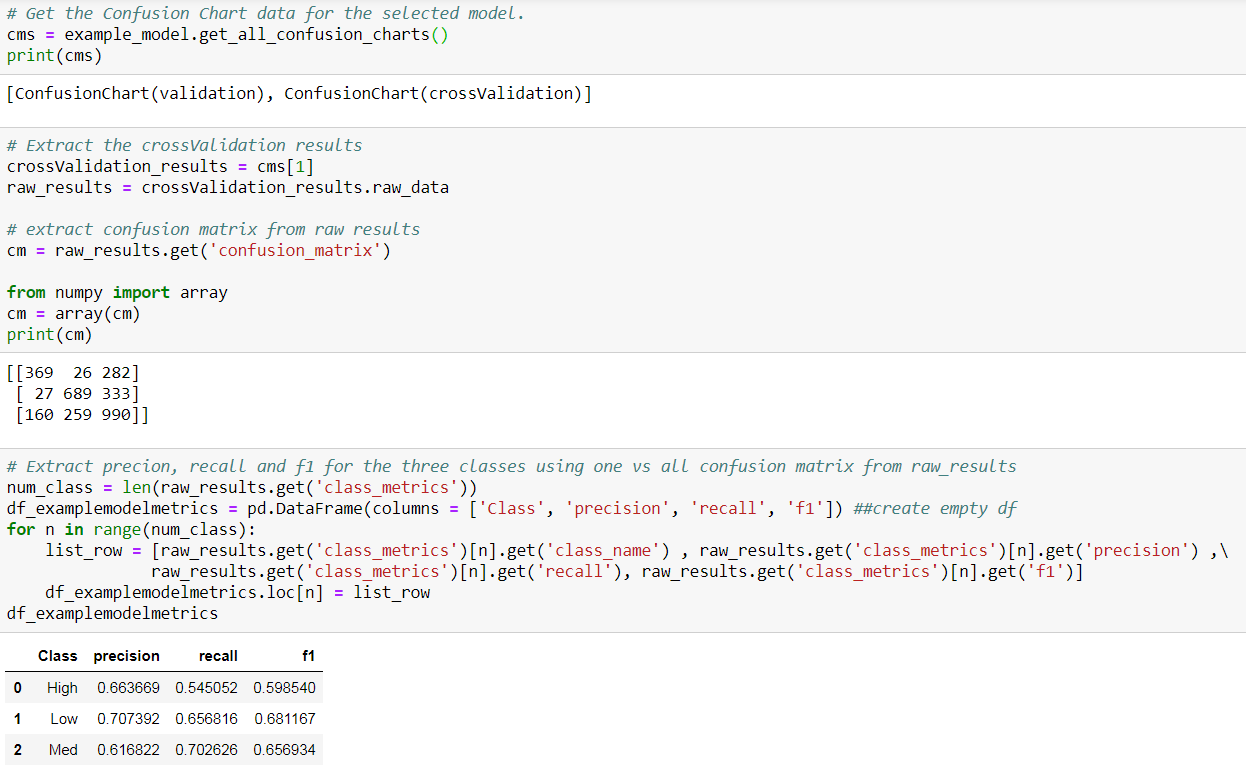
我提取了混淆矩阵,并检索了所选模型的精度和召回信息。注意,DataRobot会自动划分上传的训练数据,并报告样本外的表现,这是一种良好的数据科学实践。
测试数据性能
接下来,我想研究所选模型在测试数据上的性能。我上传了测试数据,开始了一项预测工作,并检索了预测结果。
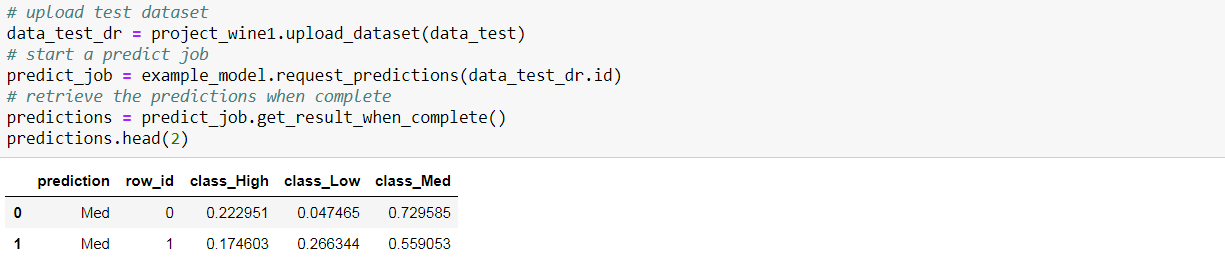
将检索结果作为数据框检索,可以使用scikit-learn轻松计算性能指标。
特征影响
DataRobot还可以进行功能影响,衡量模型中每个功能的相关性。计算预测解释的先决条件是您需要计算模型的特征影响(每个模型只需要执行一次)。
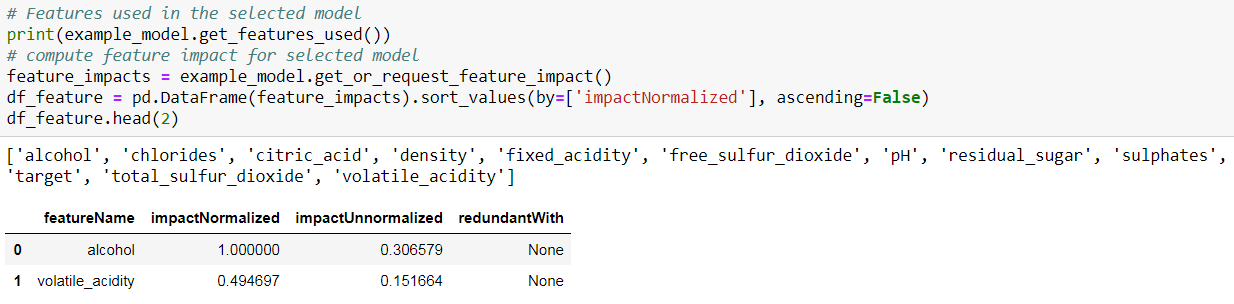
'impactUnnormalized'是在随机改组给定特征之后进行预测时误差度量分数的差异程度,同时保持所有其他特征相同。'impactNormalized'被归一化,因此最大值为1.在两种情况下,较大的值表示更重要的特征。如果在考虑其他特征后判断特征是冗余的,则将其包括在模型中对于附加精度没有太大贡献。'redundantWith'值是与此功能具有最高相关性的要素的名称。与功能影响一起,DataRobot还可以计算 数据集的每一行的预测解释。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消