











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用spaCy自然语言处理复盘复联无限战争(上)
2019年05月26日 由 sunlei 发表
310542
0
经过漫长的煎熬,《复仇者联盟4:终极游戏》终于上映。我,和世界上大多数人一样,在第一时间冲到电影院去看,体验《复仇4》是如何拯救世界并且结束第一个十年的故事的。为了平息我的紧张情绪,缓解等待,我想重温上一部电影《复联3:无限战争》,当然,由于我是一个搞技术的,我的回顾旅行将用到的是自然语言处理,简称NLP。
在本文中,我使用spaCy,一个NLP Python开源库来帮助我们处理和理解大量的文本,我分析了电影的脚本来研究以下项目:
如果你对代码和技术词汇不感兴趣,那遇到我你真走运!我在本文中使用的词汇和术语大多是非技术性的,对用户友好的,所以即使你没有NLP、AI、机器学习那些扑朔迷离高深词汇的 *insert buzzword here*的经验,你也应该能够掌握我想要传达的信息。

实验中使用的数据或文本语料库(通常在NLP中称为语料库)是电影脚本。然而,在使用数据之前,我必须清理它。因此,我删除一些不必要的东西,如评论,描述一个动作,或者场景例如“[灭霸粉碎了宇宙魔方,得到了空间原石……]”, 以及说台词的角色的名字(实际上,这个名字是用来知道谁说什么,但不作为实际语料库的一部分,不用于分析)。此外,作为spaCy数据处理步骤的一部分,我忽略了标记为停止词的术语,换句话说,就是常用的单词,如“I”、“you”、“an”。而且,我只使用引理,也就是每个单词的规范形式。例如,动词“talk”、“talking”和“talking”是同一个词的不同形式,其根本是“talk”。
要以spaCy处理一段文本,首先需要加载语言模型,然后调用文本语料库上的模型。结果是一个Doc对象,一个保存处理过的文本的对象。
(在spaCy中创建Doc对象)
现在我们已经有了一个干净的、经过处理的语料库,是时候开始了!
整部电影中出现最多的十大动词、名词、副词和形容词
仅仅看动词出现的次数就能知道电影的整体动作或情节吗?本文的第一个图表说明了这一点。
[caption id="attachment_40653" align="aligncenter" width="640"]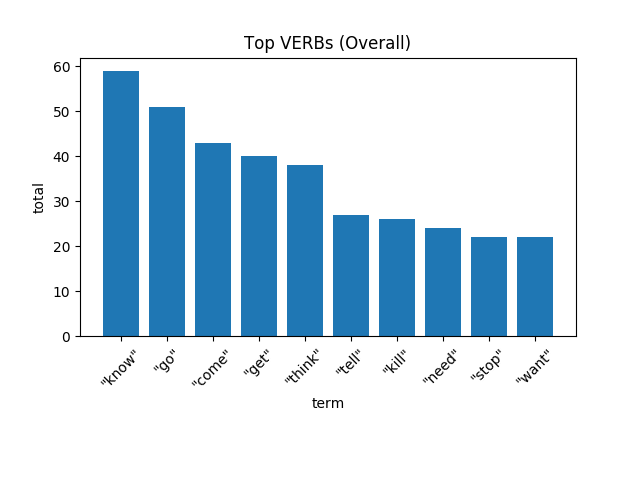 “我知道”、“你认为”是一些最常见的短语[/caption]
“我知道”、“你认为”是一些最常见的短语[/caption]
“知道”、“走”“来”,“得到”,“想”,“告诉”,“杀”,“需要”,“停止”和“希望”。我们能从中推断出什么?因为我看过好几次这部电影——也暗示我有偏见——我愿意根据这些动词来总结《复仇者联盟3:无限战争》是关于了解、思考和调查如何去阻止某物或某个人的。
这就是我们如何获得spaCy的动词:
那么描述动词的副词呢?
[caption id="attachment_40654" align="aligncenter" width="640"]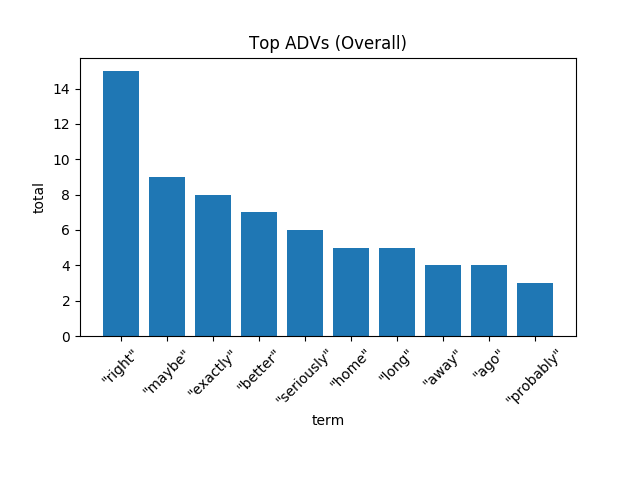 “我真的不知道你的头是怎么塞进头盔里的”——奇异博士[/caption]
“我真的不知道你的头是怎么塞进头盔里的”——奇异博士[/caption]
对于一部关于阻止紫薯精毁灭半个宇宙的电影来说,口语副词中有很多积极意义的成分,比如“right”、“exactly”和“better”。
所以,我们知道了动作,以及它们是如何被描述的,现在是时候看看名词了。
[caption id="attachment_40655" align="aligncenter" width="640"]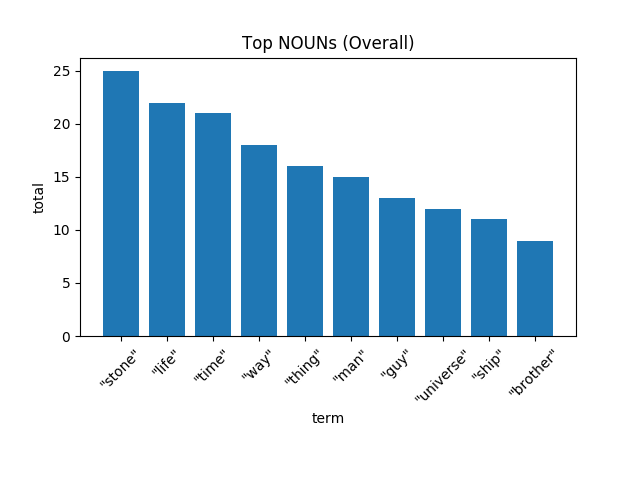 “这将是以命换命。灭霸终将会得到那块石头。——暗夜比邻星[/caption]
“这将是以命换命。灭霸终将会得到那块石头。——暗夜比邻星[/caption]
看到“石头”作为第一个出现次数最多的结果并不奇怪,毕竟这部电影是围绕他们的。出现在第二位的“生命”这个词,这是灭霸想要摧毁的东西,紧随其后的是“时间”,而这正是《复仇者联盟》所剩无多的(注:“时间”也可以归因于提到了时间宝石)。
最后,我将用形容词或描述名词的单词来结束本节。与副词类似,我们也有“good”和“right”等表达积极意义的词汇,以及“okay”和“sure”等表示肯定的词汇。
[caption id="attachment_40656" align="aligncenter" width="640"]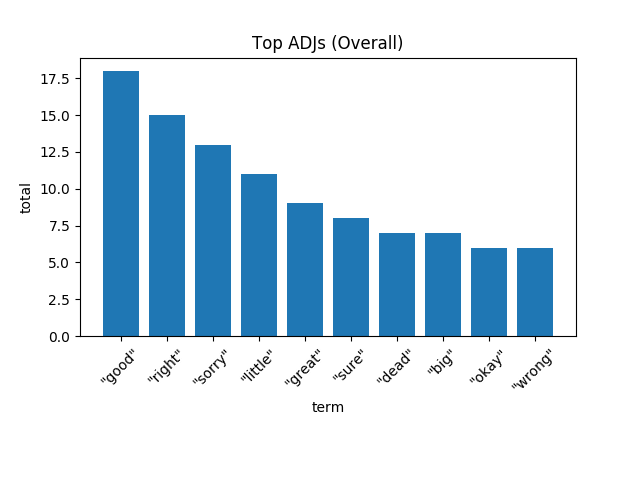 “I'm sorry, little one.” (对不起,小家伙)——灭霸[/caption]
“I'm sorry, little one.” (对不起,小家伙)——灭霸[/caption]
由特定角色提到较多的动词和名词
之前,我们看到了电影中提到的最常见的动词和名词。虽然这些知识让我们对电影的整体感觉和情节有了一定的了解,但它并没有过多地讲述角色的个人经历。因此,我使用了与查找前十名动词和名词相同的程序,但是是在角色级别上。
因为电影中有很多角色,所以我只选择了一些台词比较合理的角色,加上一些我最喜欢的角色:)。这些角色分别是钢铁侠、奇异博士、卡魔拉、雷神托尔、火箭浣熊、星爵、乌木·莫和灭霸。对不起,队长,你没有入选。
下面的图片显示了这些角色使用的最多的名词。
[caption id="attachment_40657" align="aligncenter" width="1280"]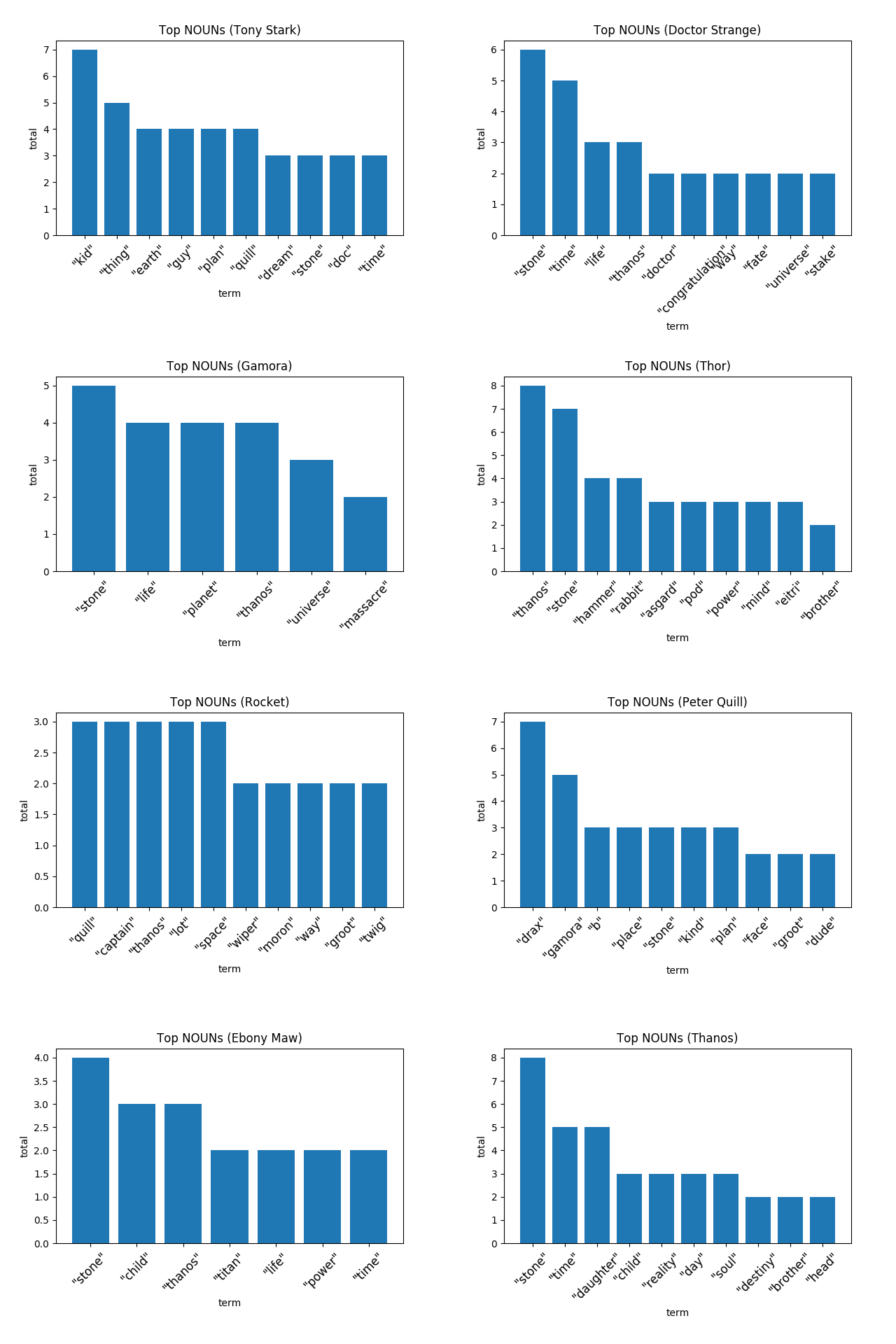 星爵到底为什么这么频繁地叫德拉克斯?[/caption]
星爵到底为什么这么频繁地叫德拉克斯?[/caption]
神奇的是,在大多数情况下,我们亲爱的英雄们最常用的名词都是伙伴的名字。例如,托尼说了9次“孩子”(指蜘蛛侠),火箭叫了3次奎尔(星爵),而星爵自己叫了7次德拉克斯(更像是尖叫)。
通过进一步的观察,我们可以推断出对每个角色心中最重要的东西。以钢铁侠为例,数据表明地球对他来说非常重要的。与他相似的是卡魔拉,她总是想着更高的目标——“生命”、“宇宙”和“行星”——并最终为此付出了代价。奇异博士还有另一个目标——保护他的石头——他反复提到。还有雷神索尔(Thor),他和灭霸之间有恩怨涉及家国,连提了8次灭霸的名字,以及新的朋友长得像兔子的火箭浣熊的名字。最后,还有疯狂的灭霸,他不停地诉说想要集齐无限宝石,或者呼唤他的女儿。
名词的表达非常有意义,但动词就不一样了。在下一张图片中你会看到,动词不像名词那样丰富多彩。像“知道”、“想要”和“得到”这样的词占据了大部分的榜首。然而,有一个角色可能拥有整个语料库中最独特的动词:乌木喉。如果你不记得了,乌木喉,是灭霸的头号追随者。他的目标是——除了得到时间之石——宣扬他主人的使命,他用“聆听”、“荣幸”等词语来谄媚主人。
[caption id="attachment_40658" align="aligncenter" width="1280"]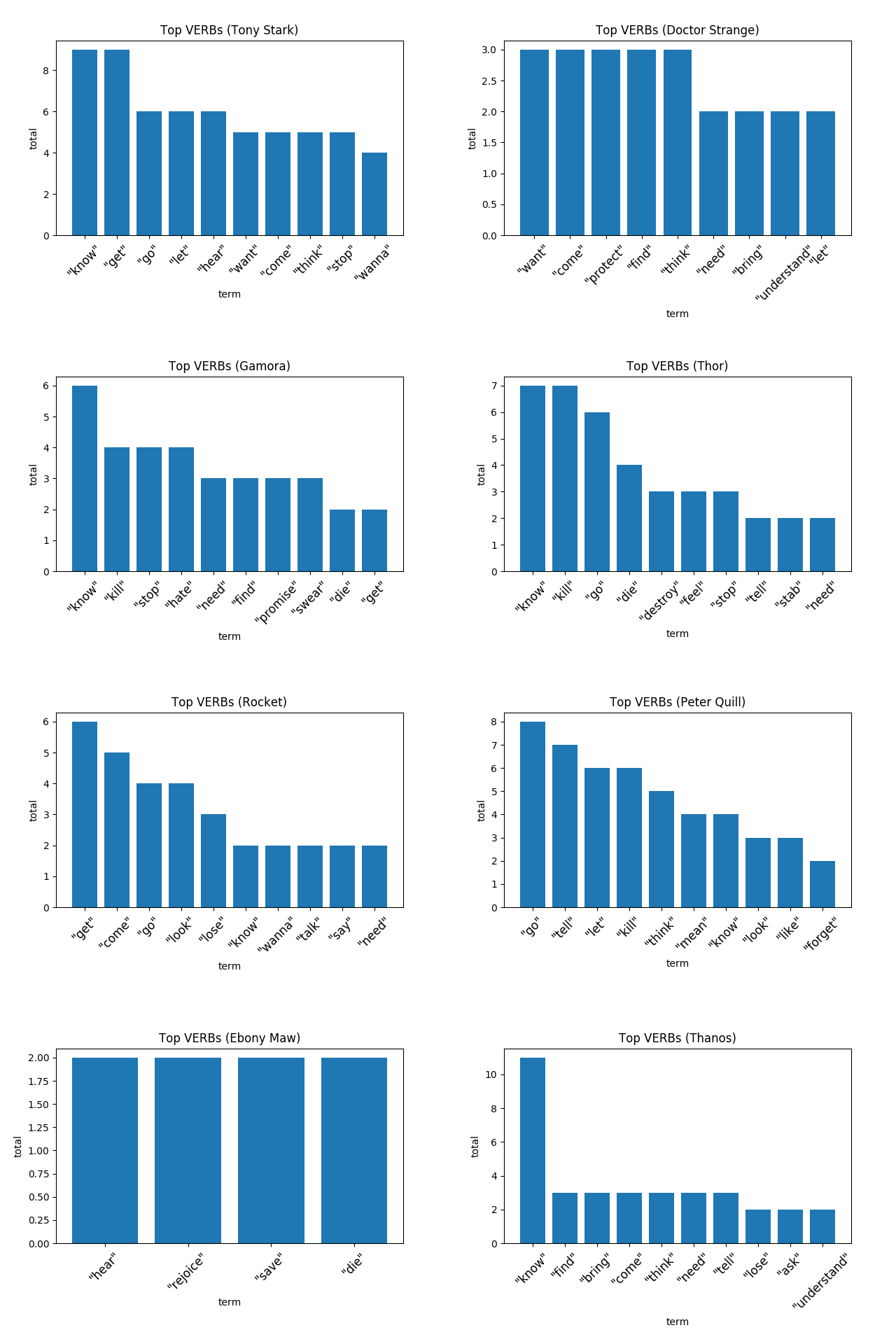 跪下聆听并感到荣幸吧!你有幸被最伟大的救世主拯救……——乌木喉[/caption]
跪下聆听并感到荣幸吧!你有幸被最伟大的救世主拯救……——乌木喉[/caption]
今天先更新到这里,最后来个彩蛋:格鲁特说得最多的是——
[caption id="attachment_40659" align="aligncenter" width="640"]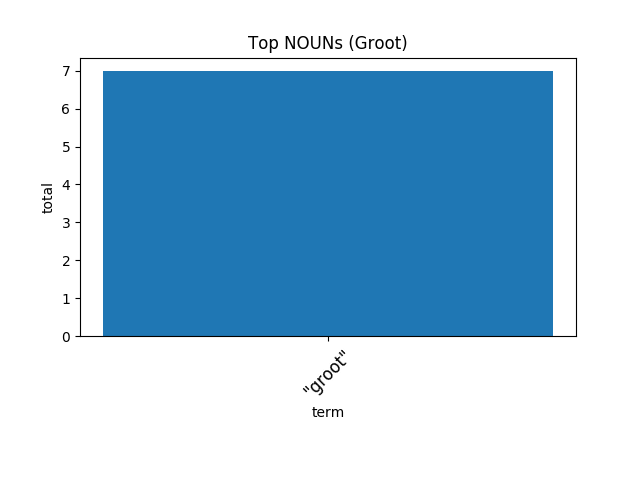 “I am Groot.”(我是格鲁特。)[/caption]
“I am Groot.”(我是格鲁特。)[/caption]

明天见~
在本文中,我使用spaCy,一个NLP Python开源库来帮助我们处理和理解大量的文本,我分析了电影的脚本来研究以下项目:
- 电影中排名前十的动词、名词、副词和形容词。
- 由特定角色说出的动词和名词。
- 电影中的30个命名实体。
- 每对人物台词之间的相似性,例如雷神和灭霸台词之间的相似性。
如果你对代码和技术词汇不感兴趣,那遇到我你真走运!我在本文中使用的词汇和术语大多是非技术性的,对用户友好的,所以即使你没有NLP、AI、机器学习那些扑朔迷离高深词汇的 *insert buzzword here*的经验,你也应该能够掌握我想要传达的信息。
处理数据
实验中使用的数据或文本语料库(通常在NLP中称为语料库)是电影脚本。然而,在使用数据之前,我必须清理它。因此,我删除一些不必要的东西,如评论,描述一个动作,或者场景例如“[灭霸粉碎了宇宙魔方,得到了空间原石……]”, 以及说台词的角色的名字(实际上,这个名字是用来知道谁说什么,但不作为实际语料库的一部分,不用于分析)。此外,作为spaCy数据处理步骤的一部分,我忽略了标记为停止词的术语,换句话说,就是常用的单词,如“I”、“you”、“an”。而且,我只使用引理,也就是每个单词的规范形式。例如,动词“talk”、“talking”和“talking”是同一个词的不同形式,其根本是“talk”。
要以spaCy处理一段文本,首先需要加载语言模型,然后调用文本语料库上的模型。结果是一个Doc对象,一个保存处理过的文本的对象。
import spacy
# load a medium-sized language model
nlp = spacy.load("en_core_web_md")
with open('cleaned-script.txt', 'r') as file:
text = file.read()
doc = nlp(text)
(在spaCy中创建Doc对象)
现在我们已经有了一个干净的、经过处理的语料库,是时候开始了!
整部电影中出现最多的十大动词、名词、副词和形容词
仅仅看动词出现的次数就能知道电影的整体动作或情节吗?本文的第一个图表说明了这一点。
[caption id="attachment_40653" align="aligncenter" width="640"]
“我知道”、“你认为”是一些最常见的短语[/caption]“知道”、“走”“来”,“得到”,“想”,“告诉”,“杀”,“需要”,“停止”和“希望”。我们能从中推断出什么?因为我看过好几次这部电影——也暗示我有偏见——我愿意根据这些动词来总结《复仇者联盟3:无限战争》是关于了解、思考和调查如何去阻止某物或某个人的。
这就是我们如何获得spaCy的动词:
import spacy
# load a medium-sized language model
nlp = spacy.load("en_core_web_md")
with open('cleaned-script.txt', 'r') as file:
text = file.read()
doc = nlp(text)
# map with frequency count
pos_count = {}
for token in doc:
# ignore stop words
if token.is_stop:
continue
# pos should be one of these:
# 'VERB', 'NOUN', 'ADJ' or 'ADV'
if token.pos_ == 'VERB':
if token.lemma_ in pos_count:
pos_count[token.lemma_] += 1
else:
pos_count[token.lemma_] = 1
print("top 10 VERBs {}".format(sorted(pos_count.items(), key=lambda kv: kv[1], reverse=True)[:10]))
那么描述动词的副词呢?
[caption id="attachment_40654" align="aligncenter" width="640"]
“我真的不知道你的头是怎么塞进头盔里的”——奇异博士[/caption]对于一部关于阻止紫薯精毁灭半个宇宙的电影来说,口语副词中有很多积极意义的成分,比如“right”、“exactly”和“better”。
所以,我们知道了动作,以及它们是如何被描述的,现在是时候看看名词了。
[caption id="attachment_40655" align="aligncenter" width="640"]
“这将是以命换命。灭霸终将会得到那块石头。——暗夜比邻星[/caption]看到“石头”作为第一个出现次数最多的结果并不奇怪,毕竟这部电影是围绕他们的。出现在第二位的“生命”这个词,这是灭霸想要摧毁的东西,紧随其后的是“时间”,而这正是《复仇者联盟》所剩无多的(注:“时间”也可以归因于提到了时间宝石)。
最后,我将用形容词或描述名词的单词来结束本节。与副词类似,我们也有“good”和“right”等表达积极意义的词汇,以及“okay”和“sure”等表示肯定的词汇。
[caption id="attachment_40656" align="aligncenter" width="640"]
“I'm sorry, little one.” (对不起,小家伙)——灭霸[/caption]由特定角色提到较多的动词和名词
之前,我们看到了电影中提到的最常见的动词和名词。虽然这些知识让我们对电影的整体感觉和情节有了一定的了解,但它并没有过多地讲述角色的个人经历。因此,我使用了与查找前十名动词和名词相同的程序,但是是在角色级别上。
因为电影中有很多角色,所以我只选择了一些台词比较合理的角色,加上一些我最喜欢的角色:)。这些角色分别是钢铁侠、奇异博士、卡魔拉、雷神托尔、火箭浣熊、星爵、乌木·莫和灭霸。对不起,队长,你没有入选。
下面的图片显示了这些角色使用的最多的名词。
[caption id="attachment_40657" align="aligncenter" width="1280"]
星爵到底为什么这么频繁地叫德拉克斯?[/caption]神奇的是,在大多数情况下,我们亲爱的英雄们最常用的名词都是伙伴的名字。例如,托尼说了9次“孩子”(指蜘蛛侠),火箭叫了3次奎尔(星爵),而星爵自己叫了7次德拉克斯(更像是尖叫)。
通过进一步的观察,我们可以推断出对每个角色心中最重要的东西。以钢铁侠为例,数据表明地球对他来说非常重要的。与他相似的是卡魔拉,她总是想着更高的目标——“生命”、“宇宙”和“行星”——并最终为此付出了代价。奇异博士还有另一个目标——保护他的石头——他反复提到。还有雷神索尔(Thor),他和灭霸之间有恩怨涉及家国,连提了8次灭霸的名字,以及新的朋友长得像兔子的火箭浣熊的名字。最后,还有疯狂的灭霸,他不停地诉说想要集齐无限宝石,或者呼唤他的女儿。
名词的表达非常有意义,但动词就不一样了。在下一张图片中你会看到,动词不像名词那样丰富多彩。像“知道”、“想要”和“得到”这样的词占据了大部分的榜首。然而,有一个角色可能拥有整个语料库中最独特的动词:乌木喉。如果你不记得了,乌木喉,是灭霸的头号追随者。他的目标是——除了得到时间之石——宣扬他主人的使命,他用“聆听”、“荣幸”等词语来谄媚主人。
[caption id="attachment_40658" align="aligncenter" width="1280"]
跪下聆听并感到荣幸吧!你有幸被最伟大的救世主拯救……——乌木喉[/caption]今天先更新到这里,最后来个彩蛋:格鲁特说得最多的是——
[caption id="attachment_40659" align="aligncenter" width="640"]
“I am Groot.”(我是格鲁特。)[/caption]明天见~

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消