











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Babylon:建立AI医生的数据挑战(3/5):构建全貌
2019年05月27日 由 平安 发表
867804
0

挑战3:当不是所有成员的医疗保健都通过Babylon进行时,我们如何才能全面了解成员的健康?
这是一个由五部分组成的博客系列的第三部分,探讨了我们在构建个人人工智能医生时所面临的一些挑战。
到目前为止,我们关注的是通过与Babylon平台的直接交互而获得的数据。
这主要包括:
1.成员提供的关于他们自己的数据。
2.Babylon临床医生提供的关于成员的数据。
这里面有很多信息,但并没有给我们成员健康的完整情况。
例如,除了他们的常规家庭医生外,许多人使用Babylon作为私人医生。我们的医生告诉我们,如果看不到这些患者的NHS健康记录,他们在做出某些临床决定时会感到不舒服,比如重复开处方。
如果不全面了解他们的健康状况,我们对会员的照顾是有限的。
问题:当不是所有成员的医疗保健都通过Babylon进行时,我们如何才能对他们的健康有一个整体的看法?
简短回答:我们从其他来源引入数据。
具体来说包括了解要引入的数据以及如何理解来自不同系统的数据,同时确保我们的成员能够控制他们的数据。
我们需要的数据补充了我们通过巴比伦平台获得的内容,并且与我们的使命相关。
让我们从Circle of Care的中举个例子:
- 病假护理:Babylon临床医生需要彻底了解私人病人的病史,以避免重复用药。一些患者的病史记录在他们的NHS健康记录中。因此,我们必须为我们的临床医生提供这些患者的NHS健康记录。
- 医疗保健:为了帮助人们坚持他们的健康计划,我们需要定期,持续地跟踪他们的进展。许多人使用应用程序和可穿戴设备来监控他们的睡眠,营养,活动和其他生活方式措施。因此,我们访问这些应用和可穿戴设备收集的数据。
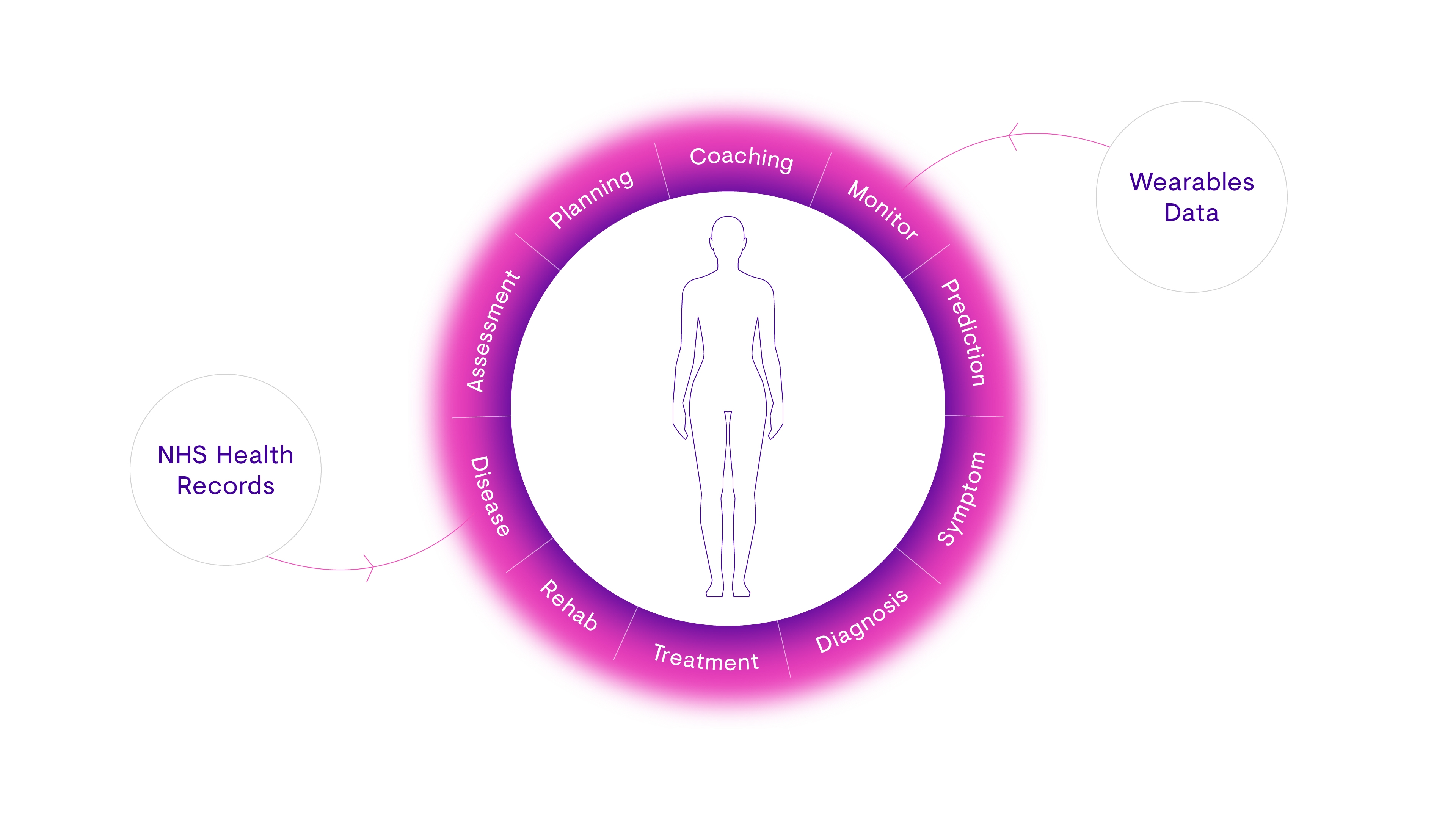
图6:从相关外部来源引入不同类型的数据对我们全面了解成员的健康状况至关重要。
这些示例还说明了另一个重要的点,即我们所重视的数据有两种类型:
1.直接提供会员医疗信息的数据(如NHS健康记录)。
2.不能清晰告诉我们成员健康状况的数据,但可以进行处理和解释以提供丰富的医学见解(例如,可穿戴设备记录的步数)。
第7课:找出明确编码医学洞察的相关数据和可以处理以生成洞察的相关数据。
所以我们已经知道了我们需要什么数据以及从哪里得到它。接下来,我们只需将他们的系统连接到我们的系统,数据就会源源不断地涌入。
要是这么简单就好了。
在一个理想的世界里,数据总是以标准的结构和格式呈现给我们。
现实恰恰相反。
尽管在全球范围内花费了数十年的时间,医疗信息的描述使用了许多不同的编码系统如:ICD-10、Read2、Snomed CT......
周围有类似fhir的标准,但在实践中经常不遵守。所以我们经常需要自己在编码系统之间进行翻译。
由于能够描述近35万种独特的医学概念3,您可能认为snomed相当全面。但这还不足以描述我们在巴比伦平台上看到的所有医疗状况。
这就是为什么我们制作了我们自己的通用语,它比目前存在的任何医学编码系统都更具表现力——更多的是关于单一医学语言的部分……
第8课:充分利用时间和资源来克服互操作性的挑战。
所有这些都已经有很多事情需要考虑,所以很容易忽略最重要的事情:我们的成员。
请记住,通过引入所有这些数据所带来的痛苦,我们的重点是为我们的成员提供我们所能提供的最安全、最有效和最方便的照顾,所有这些都是在一个隐含信任的环境中进行的。相信我们总是把会员的利益放在首位。相信各成员对自己的数据拥有完全的透明度和控制力。这包括Babylon“忘记”他们的数据,如果这是他们想要的。
在我们考虑应对数据集成挑战之前,需要先构建支持这一点的功能。
第9课:在引入新的用户数据之前,创建一种基于透明度和控制的用户信任关系。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消