











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何构建产品化机器学习系统?
2019年05月28日 由 sunlei 发表
945648
0

为生产而构建的机器学习系统需要有效地培训、部署和更新机器学习模型。在决定每个系统的体系结构时,必须考虑各种因素。这篇博文的部分内容是基于Coursera和GCP(谷歌云平台)关于构建生产机器学习系统的课程。下面,我将列出构建可伸缩机器学习系统时需要考虑的一些问题:
- 扩展模型培训和服务流程。
- 跟踪不同超参数的多个实验。
- 以预测的方式重现结果和再培训模型。
- 跟踪不同的模型及其随时间的模型性能(即模型漂移)。
- 使用新数据和回滚模型对模型进行动态再培训。
Uber(Michaelangelo)、谷歌、Airbnb (Bighead)和Facebook (FBlearner Flow)这样的公司都有解决上述问题的平台。但并不是所有人都拥有这些大公司所拥有的资源。也就是说,让我们来看看如何构建我们自己的生产ML系统。
机器学习(ML)系统的组成部分
对于ML的不同领域,如计算机视觉、NLP(自然语言处理)和推荐系统,有很多关于正在开发的新模型的文章,如BERT、YOLO、SSD等。然而,在大多数情况下,构建模型只占生产ML系统工作的5-10% !
还有很多其他组件需要考虑——数据接收、数据预处理、模型培训、模型服务和模型监控。
[caption id="attachment_40741" align="aligncenter" width="723"]
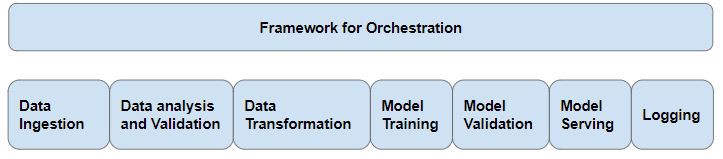 典型的ML管道[/caption]
典型的ML管道[/caption]数据接收和处理
对于大多数应用程序,数据可以分为三类:
- 存储在Amazon S3或谷歌云存储等系统中的非结构化数据。
- 结构化数据存储在关系数据库中,如MySQL或分布式关系数据库服务,如Amazon RDS、谷歌Big Query等。
- 来自web应用程序或物联网设备的流数据。
ML管道中的第一步是从相关数据源获取正确的数据,然后为应用程序清理或修改数据。以下是一些用于摄取和操作数据的工具:
DataflowRunner——谷歌云上的Apache Beam运行器。Apache Beam可以用于批处理和流处理,因此同样的管道可以用于处理批处理数据(在培训期间)和预测期间的流数据。
ApacheAirflow——Airflow的托管版本是GCP的云编辑器,用于工作流编排。气流可用于创作、安排和监控工作流。
流数据——有各种可用于接收和处理流数据的工具,如Apache Kafka、Spark Streaming和Cloud Pub/Sub。
Argo——Argo是一个开源容器本地工作流引擎,用于协调Kubernetes上的并行作业。Argo可用于指定、调度和协调Kubernetes上复杂工作流和应用程序的运行。
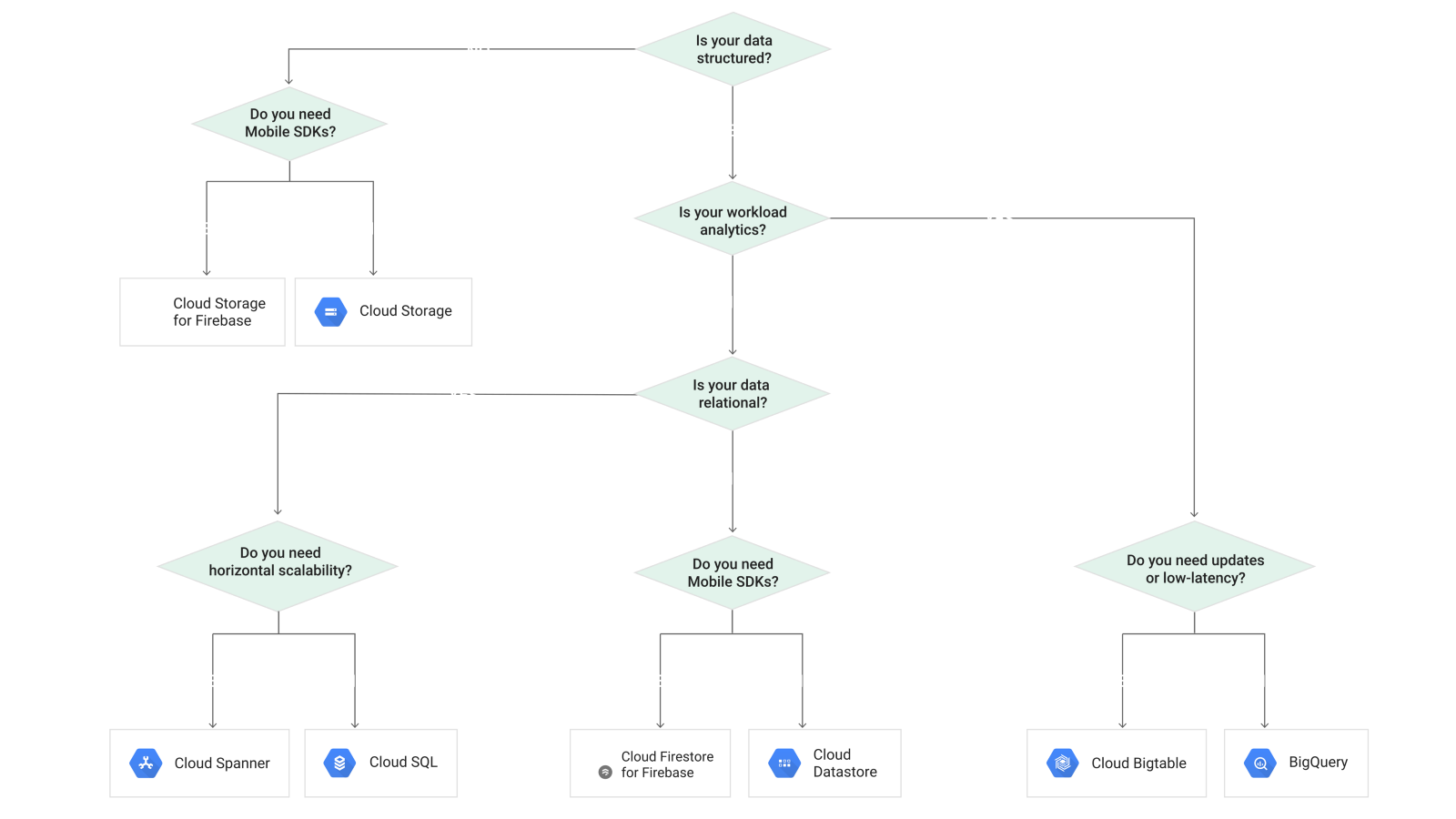
下图显示了如何在谷歌云上选择正确的存储选项:
数据验证
需要通过数据验证来减少培训服务的偏差。必须检查输入,以确定它们是否是正确的类型,并且必须持续监视输入分布,因为如果输入分布发生了显著变化,那么模型性能将会下降,这将需要重新培训。它还可以指向输入源类型的更改或某种客户机端错误。
IO和Compute—根据用例,训练时间可以是IO(输入/输出)界限、Compute界限,或者两者都有!计算边界意味着需要更多的CPU/GPU/TPU资源来减少训练时间。这可以通过增加更多的工人相对容易地完成。
IO绑定意味着读取数据并将其传输到计算资源(CPU/GPU/TPU)需要更多的时间,而在数据加载期间,计算资源长时间处于空闲状态。以下是从最慢到最快读取文件以解决IO速度问题的三种方法:
- 使用pandas或python命令读取-这是最慢的方法,应该在处理小数据集以及原型制作和调试期间使用。
- 使用TysFraseFraseFrase-这些函数在C++中实现,因此它们比上述方法更快。
- tfrecord-这是最快的方法。tfrecord格式是用于存储二进制记录序列的简单格式。
raw_dataset = tf.data.TFRecordDataset(filenames)
模型训练
对于模型训练,可以使用完全托管的服务,如AWS Sagemaker或Cloud ML Engine。使用这两种服务,用户不必担心提供实例来扩展培训过程,他们还支持托管模型服务。要创建自己的分布式培训系统,请参见下面的——
分布式训练——TensorFlow支持多种分布式训练策略。它们可分为两类:
数据并行性——在数据并行性中,数据被分成更小的组,在不同的工人/机器上进行培训,然后每次运行时更新参数。下面是一些更新参数的技术:
- 参数服务器策略(Async)——在这种方法中,特定的工作人员充当参数服务器。这是最常用的技术,也是最稳定的。由于这是一种异步方法,有时不同工作者的参数可能不同步,这会增加收敛时间。
[caption id="attachment_40743" align="aligncenter" width="580"]
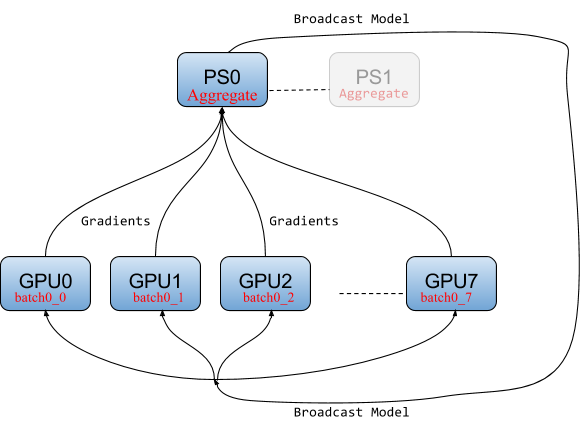 同步随机梯度下降源参数服务器架构[/caption]
同步随机梯度下降源参数服务器架构[/caption]- All Reduce(镜像策略)——这是一种相对较新的方法,其中每个worker持有参数的副本,并且在每次传递之后,所有worker都被同步。当工人之间有高速连接时,这种方法很有效。因此,它适用于TPUs和具有多个gpu的工作人员。
Horovod——Horovod是Uber发布的一个开源分布式培训框架,它使分布式培训更加容易,并且支持TensorFlow、Keras、PyTorch和Apache MXNet。
模型并行性——模型并行性不同于数据并行性,因为这里我们将模型图分布在不同的worker上。这是非常大的模型所需要的。Mesh TensorFlow和GPipe是一些可以用于模型并行化的库。
模型预测——静态服务vs动态服务
模型预测有三种方法——
- 批量预测或脱机预测——在这种情况下,脱机对大量输入进行预测,预测结果与输入一起存储,供以后使用。这适用于提前知道输入的应用程序,例如预测房价、离线生成建议等。还可以使用预测API;然而,只加载模型并进行预测更便宜、更快、更简单。
- 在线预测——在这种情况下,输入事先未知,必须根据用户提供的输入进行预测。对于这些应用程序,最好使用TensorFlow service、Cloud ML引擎或Cloud AutoML创建可扩展的性能API。在某些应用程序中,预测延迟非常重要,比如信用卡欺诈预测等等。
- 边缘预测——在这种情况下,预测必须在边缘设备上完成,如手机、Raspberry Pi或 Coral Edge TPU。在这些应用程序中,必须压缩模型大小以适合这些设备,并且还必须降低模型延迟。缩小模型大小有三种方法:
- 图形冻结-冻结图形将变量节点转换为常量节点,然后与图形一起存储,从而减小模型大小。
- 图形转换工具-图形转换工具删除预测期间未使用的节点,并帮助减少模型大小(例如,在推断期间可以删除批处理规范层)。
- 重量量化-此方法导致最大尺寸减小。通常,权重存储为32位浮点数;但是,通过将其转换为8位整数,可以显著减小模型大小。然而,这会导致精度降低,这在不同的应用中有所不同。为了防止精度损失,可以使用量化感知训练和量化参数调整。
ML系统的开源平台
Kubeflow——Kubeflow是一个构建在Kubernetes之上的开源平台,支持可伸缩的机器学习模型培训和服务。Kubeflow使用Seldon Core在Kubernetes集群上部署机器学习模型。Kubeflow可以运行在任何云基础设施上,使用Kubeflow的一个关键优势是,系统可以部署在一个本地基础设施上。
[caption id="attachment_40744" align="aligncenter" width="1069"]
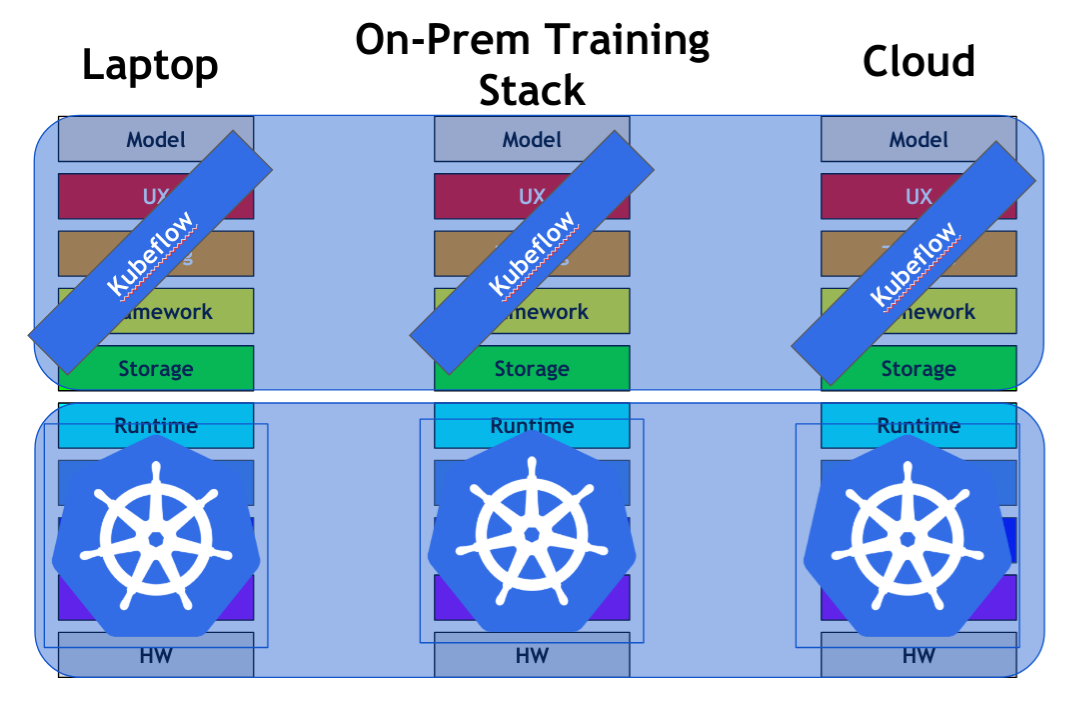 Kubeflow[/caption]
Kubeflow[/caption]MLFlow是一个用于管理机器学习生命周期的开源平台。它有三个主要组成部分,如下图所示:
[caption id="attachment_40745" align="aligncenter" width="1143"]
 MLFlow源组件[/caption]
MLFlow源组件[/caption]Polyxon-Polyxon是管理机器学习应用程序生命周期的另一个开源平台。Polyxon也在Kubernetes上运行。
TensorFlow Extended (TFX)——TFX是是用于部署生产ML管道的端到端平台。TensorFlow服务和Kubernetes可以用来创建一个可扩展的模型服务系统。TFX还有其他组件,如TFX转换和TFX数据验证。TFX使用气流作为任务的有向非循环图(DAGs)来创建工作流。TFX使用Apache Beam运行批处理和流数据处理任务。
MLFlow可以在kubeflow的基础上解决博客开头列出的大部分问题。与TFX相比,Kubeflow的优势在于,由于Kubeflow是构建在Kubernetes之上的,所以您不必担心伸缩性等问题。
结论
这些只是在构建生产ML系统时需要担心的一些事情。其他各种问题包括日志记录和监视各种服务的状态。还有许多其他工具,比如Istio,可以用来保护和监视系统。云原生计算基金会构建并支持云本地可扩展系统的各种其他项目。
许多工具仍在积极开发中,因此,构建可扩展的机器学习系统仍然是一个非常具有挑战性的问题。我热衷于建立生产机器学习系统,以解决具有挑战性的现实问题。如果你对此也感兴趣,请持续关注我的更新~

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消