











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌AI可通过起始帧和结束帧生成逼真的视频序列
2019年05月29日 由 董灵灵 发表
940698
0
 想象一下:你得到了一个视频的开头和结尾,并负责勾画出交错帧,从手头有限的信息中推断出你所能做的来填补空白。
想象一下:你得到了一个视频的开头和结尾,并负责勾画出交错帧,从手头有限的信息中推断出你所能做的来填补空白。这可能听起来像是一项不可能完成的任务,但谷歌人工智能研究部门的研究人员已经开发出一种新颖的系统,可以通过起始帧和结束帧生成真实的视频序列,这个过程被称为“在关键帧中加入中间帧(inbetweening)”。
他们发表了一篇新的论文“From Here to There: Video Inbetweening Using Direct 3D Convolutions”。
论文中写道,“如果我们能够教一个智能系统来自动将漫画书变成动画,无疑将彻底改变动画产业,虽然这种极其节省劳动力的能力仍然超出了目前所能达到的,但计算机视觉和机器学习的进步正在使它变得越来越切实可行。”
AI系统包括一个完全卷积模型,具有三个组成部分:2D卷积图像解码器,3D卷积潜在表示生成器,以及一个视频发生器。图像解码器将来自目标视频的帧映射到潜在空间,而潜在表示生成器学习合并输入帧中包含的信息。最后,视频生成器将潜在表示解码为视频帧。
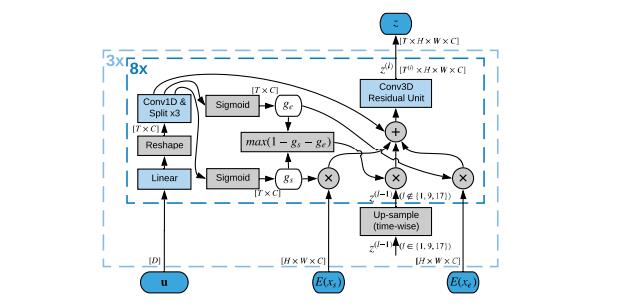
研究人员表示,将潜在表示生成与视频解码分离对于成功实现中间帧至关重要,他们试图直接从开始帧和结束帧的编码表示生成视频,但结果并不理想。为了解决这个问题,他们设计了潜在的表示生成器来融合帧表示,并逐步提高生成的视频的分辨率。
为了验证他们的方法,研究人员从三个数据集中获取视频:BAIR robot pushing,KTH动作数据库和UCF101动作识别数据集,并将它们向下采样到64 x 64像素的分辨率。每个样本总共包含16个帧,其中14个由AI系统负责生成。研究人员为每对视频帧运行模型100次,并针对每个模型变量和数据集重复该过程10次。
研究人员报告说,AI产生的序列在风格上与给定的起始和结束帧一致,有意义并且多样化。“相当令人惊讶的是,inbetweening可以在如此长的时间内实现,这可能为未来的视频生成研究提供了一个有用的替代视角。”
论文:
arxiv.org/pdf/1905.10240.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消