











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






AI根据语音音频生成实时面部动画
2019年05月29日 由 老张 发表
339579
0
 即使借助基于视觉的性能捕获软件(如CrazyTalk),使计算机生成的化身的嘴唇动起来以匹配说话者的嘴也是相当困难。要在恐怖谷效应和过于卡通化之间找到平衡并不容易,尤其是当目标对话的时长超过数十甚至数百小时。
即使借助基于视觉的性能捕获软件(如CrazyTalk),使计算机生成的化身的嘴唇动起来以匹配说话者的嘴也是相当困难。要在恐怖谷效应和过于卡通化之间找到平衡并不容易,尤其是当目标对话的时长超过数十甚至数百小时。浙江大学和网易的FuxiAI实验室的研究人员开发出了一种端到端的机器学习系统Audio2Face,可以单独从音频生成实时面部动画,同时兼顾音高和说话风格。
团队表示,“我们的方法完全是基于音轨设计的,没有任何其他辅助输入,例如图像,这使得它越来越具有挑战性,因为我们试图从声音序列中回归视觉空间,另一个挑战是面部运动涉及到面部几何表面相关区域的多重激活,这使得化身很难产生逼真且一致的面部变形。”
该团队试图构建一个符合几个标准的系统,即(生成的动画必须反映可见语音运动中的说话模式)和低延迟(系统必须能够进行近乎实时的动画)。他们还尝试将其泛化,以便可以将生成的动画重新定位到其他3D角色。
该方法包括从原始输入音频中提取手工制作的高级声学特征,特别是梅尔频率倒谱系数(MFC),声音的短期功率谱的表示。然后深度相机与mocap工具Faceshift一起用于捕捉配音演员的面部动作并编制训练集。
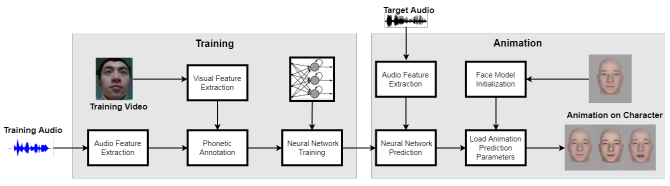
之后研究人员构建了带有参数(共51个)的3D卡通人脸模型,控制了脸部不同部位(例如,眉毛,眼睛,嘴唇和下巴)。最后,他们利用上述AI系统将音频上下文映射到参数,产生唇部和面部的动作。
训练语料库包含两个60分钟,每秒30帧的视频,女性和男性演员读台词脚本,每个对应的视频帧有1470个音频样本,机器学习模型输出与地面实况相比十分可信。
它成功地在测试音频上重现了精确的脸型,并始终能很好地针对不同的字符进行重新定位。此外,人工智能系统从一个给定的音频窗口提取特征平均只需0.68毫秒。
团队指出,AI无法跟随演员的眨眼模式,主要是因为眨眼与言语没有紧密相关。但从广义上讲,该框架可能为适应性强、可扩展的音频到面部动画技术奠定基础,这些技术几乎适用于所有发言者和所有语言。
评估结果表明,模型不仅可以从音频生成准确的唇部运动,还可以成功地还原说话者随时间变化的面部动作。
论文:
arxiv.org/pdf/1905.11142.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消