











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






另一种深度学习(上):自我监督学习与着色任务
2019年06月01日 由 深深深海 发表
109858
0
 深度学习确实在机器学习领域,尤其是图像识别任务中重新调整了东西。2012年,Alex-net发起了一项(仍然远未结束)的竞赛,以解决或至少显着改善计算机视觉任务。虽然主要思想非常稳定(对所有事物都使用深度神经网络),但研究人员却采用了不同的方法:
深度学习确实在机器学习领域,尤其是图像识别任务中重新调整了东西。2012年,Alex-net发起了一项(仍然远未结束)的竞赛,以解决或至少显着改善计算机视觉任务。虽然主要思想非常稳定(对所有事物都使用深度神经网络),但研究人员却采用了不同的方法:深度学习真正改变了机器学习领域,特别是关于图像识别任务。2012年,alexo -net发起了一场竞赛,旨在解决或至少显著改善计算机视觉任务。
尽管其主要思想相当稳定——使用深度神经网络,但研究人员采取了截然不同的方法:
- 尝试优化模型体系结构。
- 尝试优化训练计划,例如优化器本身。
- 尝试优化数据,如顺序,大小,多样性等。
这些研究路径中的每一个都提高了训练质量(速度,准确性,有时是泛化),但似乎做同样的事情可能会渐进地改进,而不是重大的突破。
另一方面,越来越多的关于深度学习的研究表明,目前的方法存在着明显的缺陷,尤其是在泛化方面。如对象旋转时泛化失败:

因此似乎需要进行更具侵略性的改进。或者可能将研究范围扩展到可能有点风险的想法。
除了上述方法,还有一些方向试图改变学习范式。可能是:
- N shot学习
- 半监督学习
- 域适应
- 自我监督学习
这些方法采用了一些不同的训练范式,尝试更具创造性,或模仿一些类似人类的模式。虽然我们尚未从上述方法(和其他方法)中获得证据来取得重大突破,但它们确实达到了一些非常重要的结果,并且还教会了我们很多关于训练过程的知识。
自我监督学习
想象一下,你有一个智能体可以搜索网络,并从它遇到的每一个图像中无缝地学习。这个概念非常有趣,因为如果它能够实现,那么深度学习的最大障碍——注释数据将部分消除。
但要如何着手呢?它首先是在文本中提出的:文本由人类很好地构建,因此有许多概念可以从中学习而没有任何注释。预测下一个或上一个单词是突出的例子,就像在单词嵌入和语言模型任务中所做的那样。
在视觉中,这样的技巧有点复杂,因为视觉数据(图像和视频)不是人类明确创造的,不是每一个视频和图像都具有任何可用于从中提取信号的逻辑结构。
这难道不是另一种形式的无监督学习吗?的确是,但是它有一个特殊之处,因为任务是受监督的(例如分类),但没有出现有效的注释。不能保证这种特定的范式会给深度学习带来最好的成果,但它肯定已经带来了一些很棒的创意。
如上所述,此类任务的名称是自我监督学习。与“弱注释”不同,“弱注释”意味着具有不同标签或标题的图像,自监督任务被认为只有图像本身而没有注释。
着色
也许图像中最直观的信号是它的颜色。当大多数计算机化颜色表示中有3个通道时,1或2可以无缝地用作注释。
由于给旧图像上色是一项有趣的任务,有许多研究都在解决这个问题,但如果是完全自动化的着色(自我监督的),就没那么多了。
在这种情况下的着色任务形成为“交叉信道编码器”,这意味着图像中的一个(或一些)信道用于编码其他信道。这个概念将在后面进一步讨论。
最引人注目的着色论文是这个:arxiv.org/pdf/1603.08511.pdf
解决着色任务的常用方法不是使用标准RGB编码,而是使用Lab颜色空间。在Lab颜色空间中,L代表亮度(B&W强度),用于预测ab通道(a-绿色到红色,b-蓝色到黄色)。
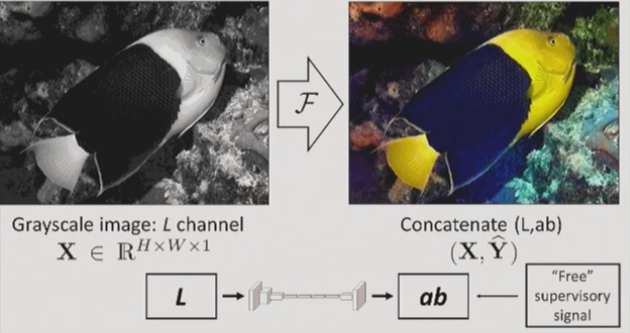
着色与Lab编码
正如我们将在我们讨论的所有任务中看到的那样,自我监督学习并不像我们在深度学习中习惯的那样简单。有一些工件会中断模型使其无法实现目标。此外,有时如果不仔细检查培训,模型会走捷径,这将阻碍其推广到其他任务。
以下是着色任务的一些挑战:
1.着色的固有模糊性:很明显,对于某些图像,存在多于一种似是而非的着色。此问题在训练和评估中会导致多个问题:
在下面的特朗普图像中,窗帘的颜色可以是红色或蓝色(以及其他颜色)。可以匹配到他的领带(或不匹配)。给定数据集中关系和窗帘的不同示例,模型将倾向于对它们进行平均化,将这些项目着色为灰色。

解决方案:在论文中,研究人员将着色作为分类问题而不是回归。除了使用特殊的损失函数外,他们的模型预测概率分布层而不是图像的实际颜色,然后将这些概率转换为颜色,即Lab空间中的313种可用颜色:
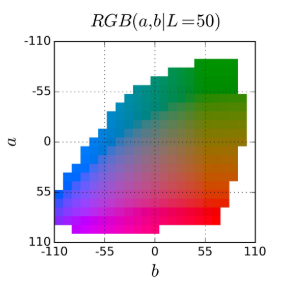
2.偏见:Lab不是均匀分布的空间。由于云层、路面等的高频率,大多数解趋向于较低的值。
解决方案:用重量损失函数解决此问题。
3.评估问题:现在模型可以预测正确的不同答案,例如,如果地面实况为蓝色且模型将选择红色,则在标准评估中它将被认为是错误的。
解决方案:使用不同的评估方法,包括事后分类“Colorization Turing测试”,即在真实图像和机器着色之间进行分析。以及将图像输入图像分类器,并与实际图像进行比较。
该模型在Colorization Turing测试中得分为35%,这并不是那么糟糕。

在这张图片中,机器着色的狗看起来比原来的更真实
在最近的另一篇论文中,使用空间局部化的多层切片(超列)和回归损失。他们试图通过预测颜色直方图并从中抽样来克服模糊性问题:

除了使用Lab空间之外,这项工作还尝试预测色调/色度属性,这与HSV色彩空间有关。
上下文
除了颜色预测,下一个最明显(但也很有创意)的任务是从图像结构中学习东西。更确切地说,试图预测图像分割(image crop)的某些内容。
这个任务的灵感直接来自word2vec,也许我们可以称之为图像的跳跃图。
但是,在文本中,单词的数量仅限于词汇量的大小,并且可能不会超过100万。虽然逐像素地完成图像补丁存在于更大的空间中。你可能会说GAN就是这样的,但是确实存在大量正确的解决方案,因此很难将其一般化。
我们将在接下来的部分讨论GAN。
在这种范式中,实际任务并不是自然而然地出现的:研究人员必须为模型提出“游戏”才能解决。通过一些突出的例子来理解:
拼图上下文
从图像中提取上下文的最简单方法是使用类似拼图的任务。第一个是Doersch和Efros的工作:从图像中裁剪出补丁,并训练模型对它们之间的关系进行分类。
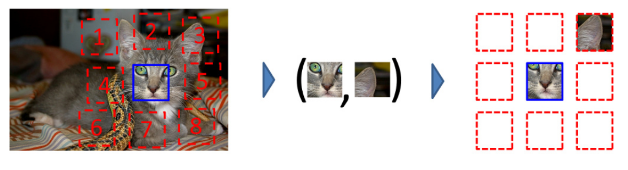
就像着色一样,任务并不简单。具体来说,模型正在寻找捷径:它不是实际学习高级特征及其关系,而是可以学习某些低级特征,例如边缘和光照关系,这往往暗示着图像部分。
为了解决这个问题,研究人员在贴片上应用了一些抖动。
研究人员遇到的另一个问题是模型通过一些照明伪像预测贴片位置,即色差。这意味着在一些相机中,颜色的分布在图像的不同部分中变化。
解决方案:这部分通过一些颜色进行转换处理,特别是将绿色和洋红色转向灰色。
下一个有突出的结果是Noroozi和Favaro的这篇论文(arxiv.org/pdf/1603.09246.pdf),解决了完整的9部分的拼图,但得到了更多的性能回报:
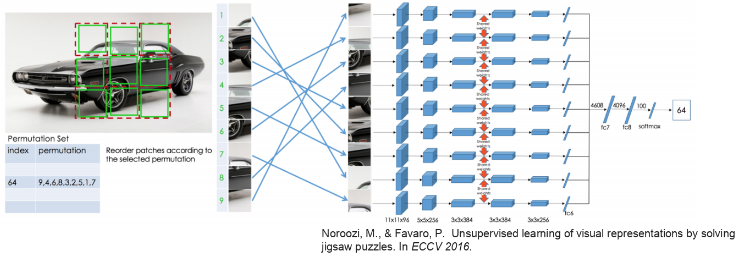
研究人员应用了对贴片进行良好编组的验证。
上下文编码器
如上所述,文本中的word2vec填充了缺失的单词。在视觉上有这样的尝试吗?事实上是有的。在论文中(arxiv.org/abs/1604.07379),研究者尝试了一些自动编码器模型来填充图像上经过剪裁的空间。

结果表明,这种方法是可行的,特别是在增加了对抗性损失的情况下,它成功地避免了处理多模式,从而避免了模糊的平均结果。
Rotation
在跳到下一级的东西之前,先来看一下rotation prediction。论文(openreview.net/forum?id=S1v4N2l0-)提出了一种新颖的图像预测方法。
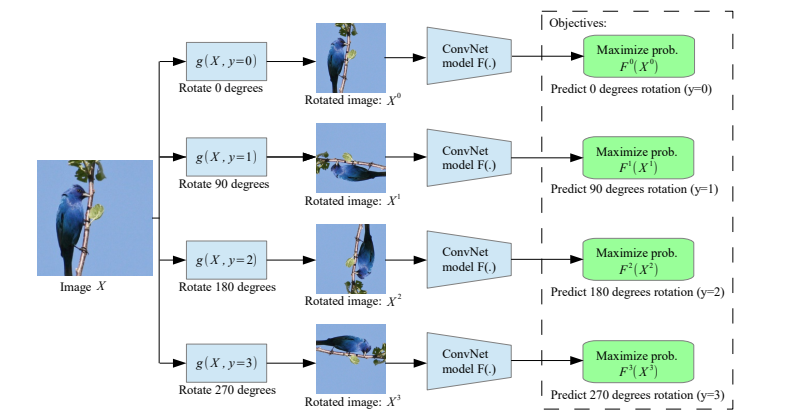 这种预测方法除了具有创造性之外,相对较快,并且不需要像我们之前看到的其他任务那样需要进行任何预先考虑,以克服对琐碎特征的学习。
这种预测方法除了具有创造性之外,相对较快,并且不需要像我们之前看到的其他任务那样需要进行任何预先考虑,以克服对琐碎特征的学习。论文中还探讨了一些“注意图”,显示了网络集中在图像的重要部分:头部,眼睛等。
尽管报告了关于转移学习到imageNet分类的最新技术成果(大多数其他工作与pascal相关),但是评论者在论文中发现了一些缺陷,因此必须采取一些措施。
总结
那么在完成所有这些工作之后,我们学到了什么呢?
着色B&W图像很好,解决拼图可能是一个有趣的演示应用程序,但更大的目标是在主要任务中实现更好的结果,尤其是分类、检测和分割。
最常见的基准是VOC Pascal数据集,当使用imagenet预训练时,它具有当前技术的最高水平:

目前的结果是:
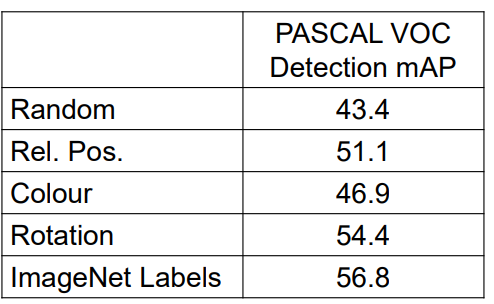
好吧,看来我们还没到那一步。虽然自我监督数据实际上是无限的,但还没有工作来挑战经典的基于图像的迁移学习结果。
除了对上述任务的标准概括之外,研究人员利用这组任务的特定功能来尝试和推广其他一些任务,例如图像聚类(最近邻,可视化数据挖掘等)。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消