











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






另一种深度学习(下):自我监督学习的生成方法
2019年06月08日 由 sunlei 发表
11215
0

在上一篇文章中,我们讨论了一些自我监督学习:利用几乎无限数量的无注释图像,并随意推广到其他任务中。有希望的是,能够更接近目前尚未达到的ImageNet预训练基准。
我们从Yan Lecun那里得到了一些额外的帮助,他把几分钟的NeurIPS演讲“迈向人工智能的下一步”用于自我监督学习。他将自我监督学习描述为蛋糕的主体,当顶部是监督学习时,樱桃相当于强化学习(因为RL中奖励的稀疏性)。
此外,在处理视频方面,也存在着突出的自我监督主体,这是显而易见的。然而,视频将在以后讨论,现在我们有另一个主题,即生成模型。
什么生成模型与自我监督有关
在关于自我监督的讨论中,Efros经常讨论为自我监督任务找到正确的损失函数很困难。
在上一篇文章中,我们研究了用于着色任务的特殊分类损失,并强调了为它们找到正确的损失函数的难度。
在演讲中,Efros描述了一种找到这种损失函数的方法。他称之为“graduate student descent”。换句话说,在为这些模型找到良好的损失函数方面存在大量的试错。所以我们能用更好的,更普遍的方法来找到它们吗?
[caption id="attachment_41042" align="aligncenter" width="880"]
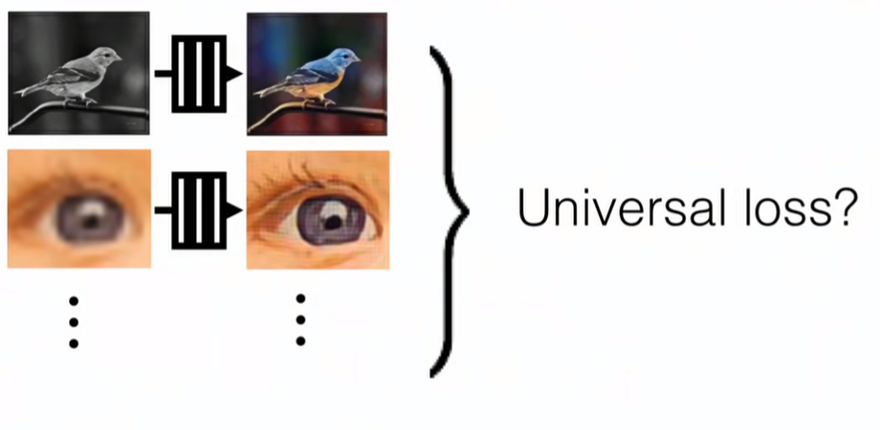 着色,超分辨率等:是否存在通用的自监督损失函数?[/caption]
着色,超分辨率等:是否存在通用的自监督损失函数?[/caption]此外,关于着色图灵测试:为了评估结果,研究人员使用mechanical Turks来辨别真假照片。所以,我们希望在这两种类型的图像之间建立某种机制。
如果你回顾2014年的深度学习,你可能还记得Ian Goodfellow第一次展示他开创性的GAN工作时,社区对这一代有前途的能力感到非常兴奋,但许多研究人员对这项工作的目的表示怀疑。对他们来说,至少在取得重大进展之前,这只是一个玩具。
自我监督的研究人员有一些不同的想法,在他们看来,GAN可能是自我监督任务的自定义损失函数。
[caption id="attachment_41044" align="aligncenter" width="880"]
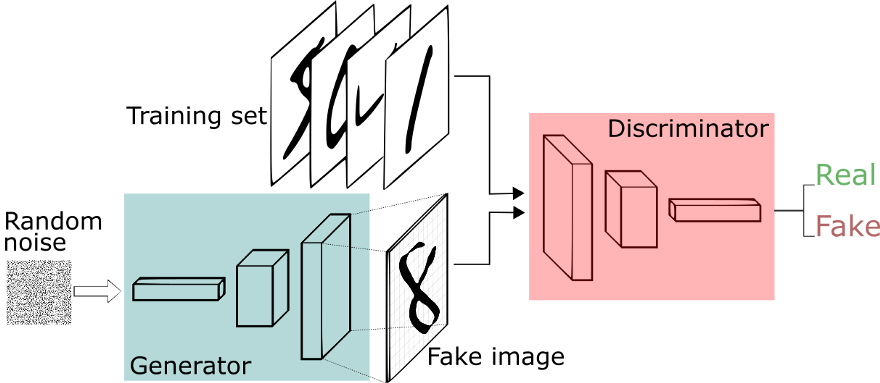 生成对抗网络的工作原理[/caption]
生成对抗网络的工作原理[/caption]让我们考虑一下,在着色工作中,我们使用标准深度学习范例来预测每个像素的颜色。我们可以使用GAN鉴别器的功能作为自定义损失吗?如果可以,就需要用另一种方式来组织问题。
我们知道GAN本质上是从完全随机的分布中生成图像。如果我们能够在给定黑白图像的情况下生成彩色图像,使用鉴别器评估结果呢?
这需要对范式进行一些改变,从不同的东西生成图像然后通过条件GAN完成随机分布:向生成器添加特征,使其生成目标空间的一些子集。例如,来自Mnist数据集的特定数字。但是如果我们可以使用标量(数字)作为“条件”,我们也可以使用向量。而如果我们可以使用向量,我们也可以使用张量。一个图像只是张量。
所以在这里的想法是:训练一个类似条件的GAN网络,条件(以及生成器的输入)是一个黑白图像,输出限制为彩色图像。
Pix2pix
Efros的学生Phillip Isola也参与了之前讨论过的着色工作,他在研究(richzhang.github.io/colorization/)中使用Pix2pix完成了这项任务。这需要对GAN架构进行严格的调整:首先为生成器使用编解码器体系结构。其次,鉴别器不能只从数据集和生成器中随机获取成对的图像。它应该有严格的图像对,一个是原始的RGB,另一个是黑白生成的。鉴别器体系结构和训练计划也与标准不同。
[caption id="attachment_41045" align="aligncenter" width="583"]
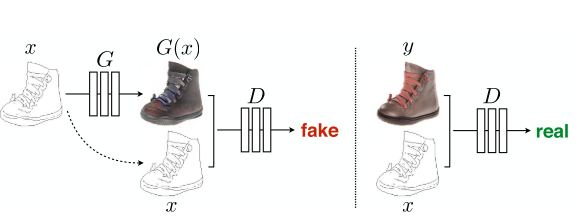 pix2pix的配对策略。这里有边=>照片而不是黑白=>RGB[/caption]
pix2pix的配对策略。这里有边=>照片而不是黑白=>RGB[/caption]但是Isola又向前迈了一步,如果成功地建立了一个从成对图像中学习的着色GAN,为什么不能将它应用于不同的图像对呢?比如说:
- 谷歌地图和谷歌地球图像对
- 建立成绩单和实际建筑立面
- 边缘和物体

而这一切都成功了。这成为去年最有趣的深度学习工作之一,它引发了Efros称之为“推特驱动的研究”。由于该论文的代码在GitHub上很容易获得,很多人对它进行各种图像配对的训练,并取得了一些非常有创意的结果。

你还可以通过在Twitter上查找#pix2pix,从而找到更多信息。Efros说,这些项目让他感到惊讶,带来了许多新的想法,并使他们的研究向前迈进了很多。
这些GAN开启了各种新的选择。然而,在创新的道路上,失去了一个小细节:自我监督的范式,意图使用自我监督的模型进行迁移学习,在此过程中却被忽略了,文中甚至没有提到。也许生成器架构太过不同,无法尝试这一点,或者生成结果的重要性掩盖了另一种更部分成功的自我监督尝试的潜力。
BiGAN
好吧,Pix2Pix的作品是彩色化的“自然继承者”。还有另一项工作尝试了在GAN网络上应用迁移学习:双向GAN——BiGAN。
BiGAN提出了一个新概念(2016年):除了标准的GAN架构,一个编码器被添加到架构中(见下文)。该编码器旨在为不同目的来学习逆向的生成器。
这项工作采用了一种非常有趣的方法:采用标准的GAN架构,而不是用x(一个真实图像)和G(z)(当z是发生器的随机输入时生成的图像)呈现鉴别器时,鉴别器是用2对输入:(x,E(x)),(G(z),z),这意味着随机输入z 和E(x),这是编码器函数试图复制随机输入。有趣的是,在生成器和编码器之间没有共享的知识。
这一点难以掌握,因此您可以在本文中阅读更多细节 - 关于编码器和生成器必须学会相互颠倒以欺骗鉴别器。
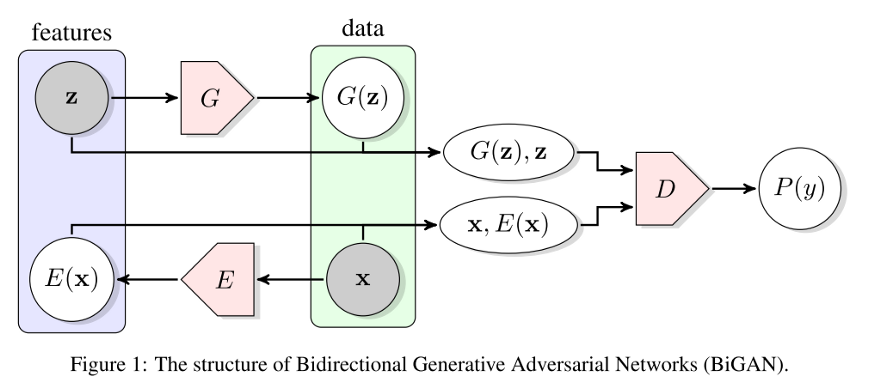
虽然这里没有条件元素 - z不是标签,但编码器可以用于分类(因此在切换一些图层后进行检测和分割)。结果可能被描述为“合理”。
如果你觉得类似的想法出现在BiGan和Pix2Pix的作品中(我应该提到BiGan之前的作品),那不是偶然的。pix2pix的后续论文《CycleGAN》,是两者的结合,允许在不“配对”训练图像的情况下训练这样的网络,并显著扩展了可转移对象,创造了著名的斑马到马(和马的背部)的转移。
[caption id="attachment_41049" align="aligncenter" width="880"]
 来自CycleGAN的一些结果[/caption]
来自CycleGAN的一些结果[/caption]交叉信道编码器
因此,我们已经看到GAN在自我监督学习中具有巨大的潜力(某种程度上尚未实现)。但是他们的老版本,现在不那么流行的版本,自动编码器呢?
实际上,自动编码器在某些任务上已经取得了良好的效果,但是它们总是会因层的信息损失而受损。
在自我监督的学习中,他们取得了一些成功。
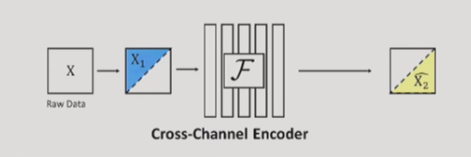
在我们前一篇文章中关于着色的讨论中,我们已经提到着色实际上是一个跨通道编码器。意思是,使用一些渠道来预测其他渠道。如果我们在这里给真正的自动编码器一个机会并且以不同的方式定义通道怎么办?
更具体地说,通过尝试通过另一半重建图像的一半。下面的工作,命名为“脑裂”正是这样做的。它定义了对角平分图像的任务,并使用自动编码器预测另一半的图像。
更进一步,每个图像可以使用两次,每半个图像用于预测另一个图像。
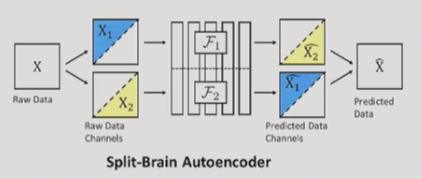
研究人员发现这种方法对对角线平分线的效果相当好,于是他们又回到了颜色的问题上,反复地预测:B&W的RBG值,B&W的RBG值,B&W的B&W值(使用特定的实验室空间)

总结和评估
根据上一篇文章,我对自监督模型的实际转学习结果有一些疑问。如上所述,重要的特征是对不同任务的概括,例如检测和分割。有意思的是,我并没有过分强调这些结果,因为它们非常脆弱,并且始终与目标保持10%的稳定差异:ImageNet预训练。
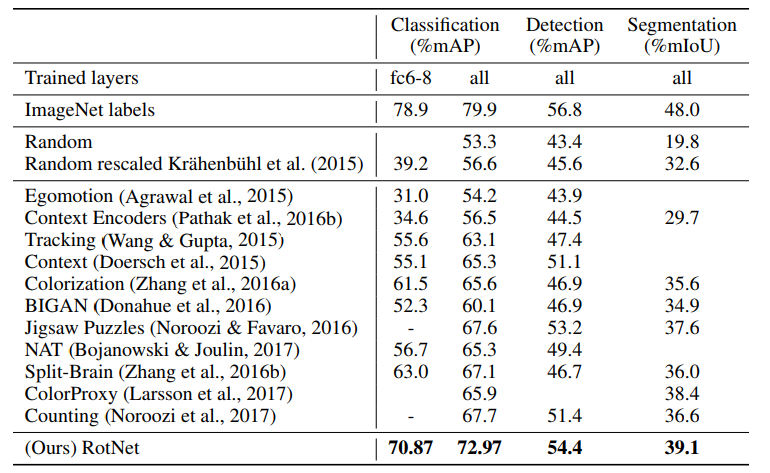
上表是从轮转工作中提取的,这可能是目前自我监督转移学习的“最新技术”。大多数其他讨论的论文也在那里。然而,我们应该对此持保留态度,因为:
- 轮转论文没有得到评论家的高度评价
- 许多这些论文中都有一些数据表达技巧,使它们在出版时看起来很领先,但在现实生活中并没有真正有用。
所以再一次强调,它似乎有很多潜力,特别是在自定义损失函数的想法,但结果还没有达到。但是,我们仍有一些希望:幸运的是,视觉信号不仅限于图像,还可以在...视频中找到。视频添加了重要的时间维度,这反过来又增加了大量新的可能任务,范例和选项,并最终产生了一些真实的结果~这些我将在未来的文章中讲到,所以请继续关注我。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消