











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






不用多进程的Python十倍速并行技巧(上)
2019年06月11日 由 sunlei 发表
311658
0

虽然python的多处理库已经成功地广泛的用于应用程序,但在本文中,我们发现它在缺少一些重要的应用程序类中依然存在不足,包括数值数据处理、状态计算和具有昂贵初始化的计算。主要有两个原因:
- 数字数据处理效率低下。
- 缺少状态计算的抽象(即无法在单独的“任务”之间共享变量)。
Ray是一个快速、简单的框架,用于构建和运行解决这些问题的分布式应用程序。Ray利用ApacheArrow进行高效的数据处理,并为分布式计算提供任务和参与者抽象。
本文对三种不易用Python多处理表示的工作负载进行了基准测试,并比较了Ray、Python多处理和串行Python代码。请注意,务必与优化的单线程代码进行比较。
在这些基准测试中,Ray比串行Python快10-30倍,比多处理快5-25倍,比大型机器上这两种方法快5-15倍。
[caption id="attachment_41133" align="aligncenter" width="600"]
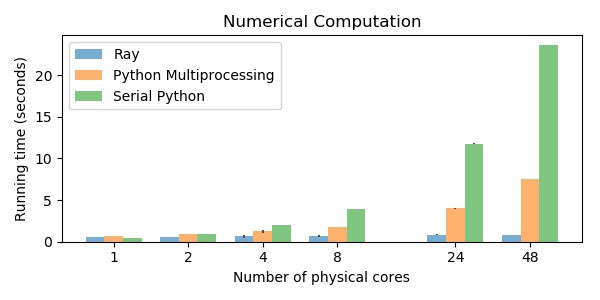 在48个物理内核的机器上,Ray比Python多处理快9倍,比单线程Python快28倍。错误条被描绘出来,但在某些情况下太小,看不见。下面提供了复制这些数字的代码。工作负载被扩展到核心的数量,所以更多的核心需要做更多的工作(这就是为什么serial python在更多的核心上花费更长的时间)。[/caption]
在48个物理内核的机器上,Ray比Python多处理快9倍,比单线程Python快28倍。错误条被描绘出来,但在某些情况下太小,看不见。下面提供了复制这些数字的代码。工作负载被扩展到核心的数量,所以更多的核心需要做更多的工作(这就是为什么serial python在更多的核心上花费更长的时间)。[/caption]使用M5实例类型(M5.large用于1个物理内核,M5.24XLarge用于48个物理内核)在EC2上运行基准测试。这里提供了运行所有基准的代码。这篇文章中包含了缩写的代码片段。主要的区别在于,完整的基准包括1)计时和打印代码,2)预热Ray对象存储的代码,以及3)使基准适应小型机器的代码。
基准1:数字数据
许多机器学习、科学计算和数据分析工作负载大量使用大型数据阵列。例如,一个数组可以表示一个大的图像或数据集,应用程序可能希望有多个任务分析该图像。有效处理数字数据至关重要。
通过下面的for循环,每一个使用Ray需要0.84秒,使用python多处理需要7.5秒,使用串行python需要24秒(在48个物理核上)。这一性能差异解释了为什么可以在Ray上构建类似Modin的库,而不是在其他库之上构建。
代码如下:
import numpy as np
import psutil
import ray
import scipy.signal
num_cpus = psutil.cpu_count(logical=False)
ray.init(num_cpus=num_cpus)
@ray.remote
def f(image, random_filter):
# Do some image processing.
return scipy.signal.convolve2d(image, random_filter)[::5, ::5]
filters = [np.random.normal(size=(4, 4)) for _ in range(num_cpus)]
# Time the code below.
for _ in range(10):
image = np.zeros((3000, 3000))
image_id = ray.put(image)
ray.get([f.remote(image_id, filters[i]) for i in range(num_cpus)])
使用ray的玩具图像处理示例的代码。
通过调用ray.put(image),大型数组存储在共享内存中,所有工作进程都可以访问它,而不需要创建副本。这不仅适用于数组,还适用于包含数组的对象(如数组列表)。
当工作人员执行f任务时,结果再次存储在共享内存中。然后,当脚本调用ray.get([…])时,它创建由共享内存支持的numpy数组,而无需反序列化或复制值。
这些优化是由于Ray使用Apache Arrow作为底层数据布局和序列化格式以及等离子共享内存对象存储而实现的。
使用Python多处理,代码如下所示:
from multiprocessing import Pool
import numpy as np
import psutil
import scipy.signal
num_cpus = psutil.cpu_count(logical=False)
def f(args):
image, random_filter = args
# Do some image processing.
return scipy.signal.convolve2d(image, random_filter)[::5, ::5]
pool = Pool(num_cpus)
filters = [np.random.normal(size=(4, 4)) for _ in range(num_cpus)]
# Time the code below.
for _ in range(10):
image = np.zeros((3000, 3000))
pool.map(f, zip(num_cpus * [image], filters))
使用多处理的玩具图像处理示例的代码。
这里的不同之处在于,Python multiprocessing在进程之间传递大型对象时使用pickle来序列化它们。这种方法要求每个进程创建自己的数据副本,这增加了大量的内存使用,以及昂贵的反序列化开销,Ray通过使用Apache Arrow数据布局实现零拷贝序列化和Plasma store来避免这种开销。
基准2:有状态计算
需要在许多小工作单元之间共享大量“状态”的工作负载是对Python多处理构成挑战的另一类工作负载。这种模式非常常见,我用一个玩具流处理应用程序来说明它。
[caption id="attachment_41135" align="aligncenter" width="600"]
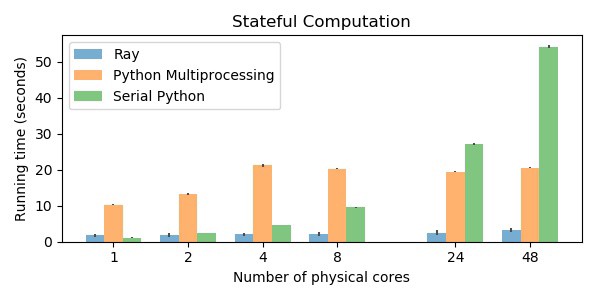 在拥有48个物理内核的机器上,Ray比Python多处理速度快6倍,比单线程Python快17倍。在少于24个内核上,Python多处理并不比单线程Python表现得更好。工作负载被扩展到核心的数量,所以更多的核心需要做更多的工作(这就是为什么serial python在更多的核心上花费更长的时间)。[/caption]
在拥有48个物理内核的机器上,Ray比Python多处理速度快6倍,比单线程Python快17倍。在少于24个内核上,Python多处理并不比单线程Python表现得更好。工作负载被扩展到核心的数量,所以更多的核心需要做更多的工作(这就是为什么serial python在更多的核心上花费更长的时间)。[/caption]状态通常封装在Python类中,Ray提供了一个参与者抽象,这样类就可以在并行和分布式设置中使用。相反,Python multiprocessing并没有提供一种自然的方法来并行化Python类,因此用户经常需要在map调用之间传递相关的状态。这种策略在实践中很难实现(许多Python变量不容易序列化),而且当它实际工作时可能很慢。
下面是一个有趣的示例,它使用并行任务一次处理一个文档,提取每个单词的前缀,并在末尾返回最常见的前缀。前缀计数存储在actor状态中,并由不同的任务进行更改。
本例使用Ray使用3.2秒,使用Python多处理使用21秒,使用串行Python使用54秒(在48个物理核心上)。
Ray版本如下所示:
from collections import defaultdict
import numpy as np
import psutil
import ray
num_cpus = psutil.cpu_count(logical=False)
ray.init(num_cpus=num_cpus)
@ray.remote
class StreamingPrefixCount(object):
def __init__(self):
self.prefix_count = defaultdict(int)
self.popular_prefixes = set()
def add_document(self, document):
for word in document:
for i in range(1, len(word)):
prefix = word[:i]
self.prefix_count[prefix] += 1
if self.prefix_count[prefix] > 3:
self.popular_prefixes.add(prefix)
def get_popular(self):
return self.popular_prefixes
streaming_actors = [StreamingPrefixCount.remote() for _ in range(num_cpus)]
# Time the code below.
for i in range(num_cpus * 10):
document = [np.random.bytes(20) for _ in range(10000)]
streaming_actors[i % num_cpus].add_document.remote(document)
# Aggregate all of the results.
results = ray.get([actor.get_popular.remote() for actor in streaming_actors])
popular_prefixes = set()
for prefixes in results:
popular_prefixes |= prefixes
使用Ray的玩具流处理示例的代码。
Ray在这里表现得很好,因为Ray的抽象符合当前的问题。这个应用程序需要一种在分布式设置中封装和修改状态的方法,而actor正好符合这个要求。
多处理版本如下。
from collections import defaultdict
from multiprocessing import Pool
import numpy as np
import psutil
num_cpus = psutil.cpu_count(logical=False)
def accumulate_prefixes(args):
running_prefix_count, running_popular_prefixes, document = args
for word in document:
for i in range(1, len(word)):
prefix = word[:i]
running_prefix_count[prefix] += 1
if running_prefix_count[prefix] > 3:
running_popular_prefixes.add(prefix)
return running_prefix_count, running_popular_prefixes
pool = Pool(num_cpus)
running_prefix_counts = [defaultdict(int) for _ in range(4)]
running_popular_prefixes = [set() for _ in range(4)]
for i in range(10):
documents = [[np.random.bytes(20) for _ in range(10000)]
for _ in range(num_cpus)]
results = pool.map(
accumulate_prefixes,
zip(running_prefix_counts, running_popular_prefixes, documents))
running_prefix_counts = [result[0] for result in results]
running_popular_prefixes = [result[1] for result in results]
popular_prefixes = set()
for prefixes in running_popular_prefixes:
popular_prefixes |= prefixes
使用多处理的玩具流处理示例的代码。
这里的挑战是pool.map执行无状态函数,这意味着要在另一个pool.map调用中使用的pool.map调用中生成的任何变量都需要从第一个调用返回并传递到第二个调用。对于小对象来说,这种方法是可以接受的,但是当需要共享大的中间结果时,传递它们的成本是很高的(注意,如果变量在线程之间共享,这是不可能的,但是因为它们是跨进程边界共享的,必须使用类似pickle的库将变量序列化为一个字节字符串)。
因为它必须传递如此多的状态,所以多处理版本看起来非常笨拙,最终只在串行Python上实现了很小的加速。实际上,您不会编写这样的代码,因为您只是不会使用Python多处理进行流处理。相反,您可能会使用专用的流处理框架。这个例子表明,Ray非常适合构建这样的框架或应用程序。
这里有一个警告是,有很多方法可以使用Python多处理。在本例中,我们将pool.map进行比较,因为它提供了最接近的API比较。在本例中,应该可以通过启动不同的进程并在它们之间设置多个多进程队列来获得更好的性能,但是这会导致复杂而脆弱的设计。
好了,今天的内容已经很多了,余下的内容我们明天继续。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消