











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






TensorFlow 2.0实战入门(上)
2019年06月15日 由 sunlei 发表
943469
0

如果你正在读这篇文章,你可能接触过神经网络和TensorFlow,但是你可能会对与深度学习相关的各种术语感到有点畏缩,这些术语经常在许多技术介绍中被掩盖或未被解释。本文将深入介绍TensorFlow 2.0的初学者教程,从而让大家对其中的一些主题有所了解。
注意:鉴于这是一个初学者指南,这里所表达的大部分思想都应该有一个较低的入门门槛,但是对什么是神经网络有一定的背景知识会有所帮助。如果您想温习一下,本文将提供一个很好的概述。
你将学到的
阅读本文之后,您将更好地理解这些主题的一些关键概念主题和TysFrace/CARAS实现(Keras是一个构建在TensorFlow之上的深度学习库)。
概念
- 神经网络层形状
- 激活功能(如Relu和Softmax)
- Logits
- Dropout
- Optimizers
- Loss
- Epochs
TensorFlow / Keras功能:
- keras.layers.Sequential()
- keras.layers.Flatten()
- keras.layers.Dense()
- compile()
- fit()
数据
TensorFlow 2.0初学者教程使用的数据是MNIST数据集,它被认为是一种“Hello, World!”用于神经网络和深度学习,可以直接从Keras下载。它是一个满是手绘数字0-9之间的数据集,并有一个相应的标签描述绘图应该描述的数字。
[caption id="attachment_41242" align="aligncenter" width="806"]
 来自MNIST数据集的示例观察[/caption]
来自MNIST数据集的示例观察[/caption]使用此数据集的想法是,我们希望能够训练一个模型,该模型了解数字0–9对应的形状类型,并随后能够正确地标记未经过训练的图像。当图像(如下图所示)传递给模型时,此任务变得更加复杂。有些人甚至会把这张图误认为是零,尽管它被标为8。
[caption id="attachment_41243" align="aligncenter" width="304"]
 示例来自mnist的模糊图像[/caption]
示例来自mnist的模糊图像[/caption]在较高的层次上,初学者教程中构建的模型将训练图像作为输入,并尝试将这些图像分类为0到9之间的数字。如果预测错误,它将进行数学调整以更好地预测类似的图像。一旦模型完成了培训,它将在未培训的图像上进行测试,以最终评估模型的性能。
[caption id="attachment_41244" align="aligncenter" width="872"]
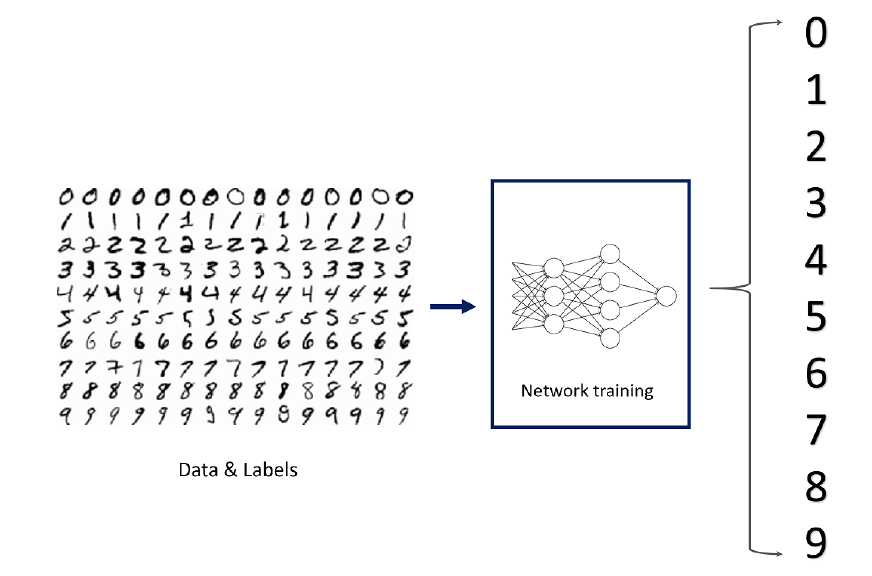 基本结构的神经网络建立在初学者的笔记本上[/caption]
基本结构的神经网络建立在初学者的笔记本上[/caption]了解初学者笔记本
现在让我们深入研究TensorFlow是如何实现这个基本神经网络的。
加载数据
在第一个单元中进行了一些设置之后,笔记本电脑开始使用它的load_data()函数从keras库加载mnist数据集,该函数返回两个元组,如代码所示。文档可以在这里找到。
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) =
mnist.load_data()
当我们开始探索TensorFlow是如何处理这些数据的时,理解这些数据实际上是什么样子将会很有帮助。
>>> x_train.shape
(60000, 28, 28)
>>> y_train.shape
(60000,)
>>> x_test.shape
(10000, 28, 28)
>>> y_test.shape
(10000,)
通过观察这些结果,我们可以看到数据集中有70k个图像,60k个训练和10000个测试。这两个28表示每个图像是28像素乘28像素,图像表示为28x28数组,其中填充了像素值,如下图所示。
[caption id="attachment_41245" align="aligncenter" width="858"]
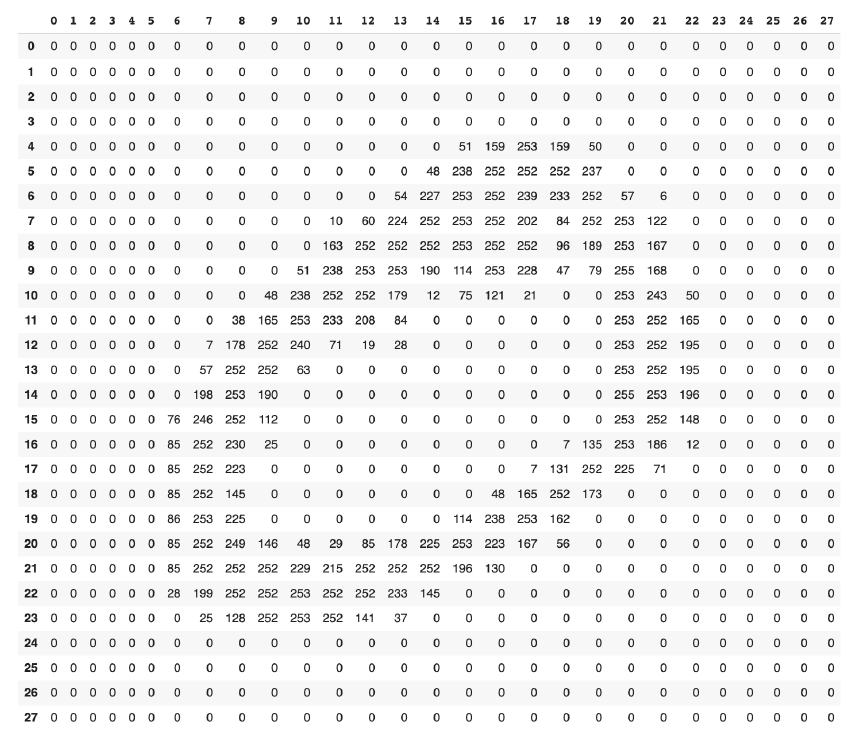 描述每个图像如何存储在MNIST数据集中[/caption]
描述每个图像如何存储在MNIST数据集中[/caption]笔记本准备数据的最后一步是将每张图像中的每个像素值转换为0.0 - 1.0之间的浮点数。这样做是为了帮助计算出每幅图像的预测所涉及的数学尺度。
x_train, x_test = x_train / 255.0, x_test / 255.0
构建模型结构
也许本笔记本最令人困惑的部分是创建模型结构的部分。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
这段代码的目的是指定在我们的神经网络中会出现什么样的层。第一个组件是tf.keras.models.sequential()调用。所有这些功能都是开始创建线性(或“顺序”)的层排列。上面代码片段中的所有其他代码详细说明了模型中的层以及它们的排列方式。
下一行代码tf.keras.layers.flatten(input_shape=(28,28))创建网络中的第一层。直观地说,我们希望能够使用图像中的所有信息来预测它是什么数字,因此输入层应该为图像中的每个像素都有一个节点。每个图像有28*28=784个值,因此flatten()创建一个包含784个节点的层,其中包含给定图像的每个像素值。如果我们的彩色图像每个像素包含3个值(RGB值),那么flatten()将创建一个节点为28*28*3=2352的层。
我们在模型中看到的另一种层是使用tf.keras.layers. density()创建的,它创建了所谓的完全连接层或紧密连接层。这可以与稀疏连接的层进行比较,区别在于相邻层中的节点之间如何传递信息。
[caption id="attachment_41246" align="aligncenter" width="863"]
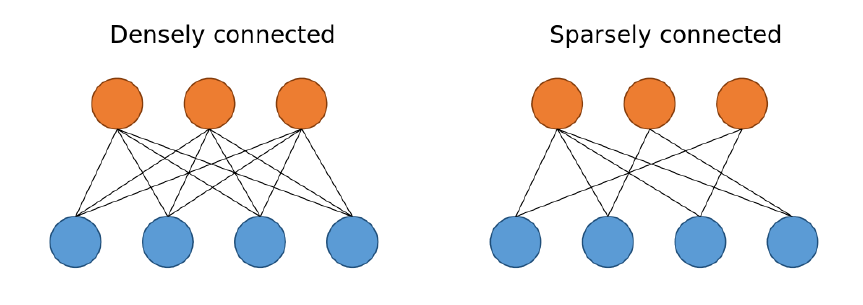 密集和稀疏连接的比较(来自Mir Alavi博客的图片)[/caption]
密集和稀疏连接的比较(来自Mir Alavi博客的图片)[/caption]可以看到,在一个密集连接的层中,一层中的每个节点都连接到下一层中的每个节点,而在稀疏连接的层中,情况并非如此。所以Dense()所做的就是创建一个完全连接到它前面的层的层。第一个参数(在第一个实例中是128)指定层中应该有多少个节点。隐藏层(不是输入层或输出层的层)中的节点数是任意的,但需要注意的是,输出层中的节点数等于模型试图预测的类的数量。在这种情况下,模型试图预测10个不同的数字,因此模型中的最后一层有10个节点。这一点非常重要,因为最终层的每个节点的输出将是给定图像是特定数字的概率。
为了理解这段代码中的其余部分,我们需要发展对激活函数和退出的理解。这一部分我们将在明天的文章里讲到。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消